volatile?
volatile是保证共享变量变化可见性的关键字。所谓可见性,就是一个变量在多个线程间可见,而volatile保证了共享变量的改变在多线程之间能够及时的发现。
示例
代码
public class T {
/*volatile*/ boolean running = true;// 对比一下有无volatile的情况下,整个程序运行结果的区别
void m() {
System.out.println("m start...");
while (running) {
}
System.out.println("m end...");
}
public static void main(String[] args) {
T t = new T();
new Thread(t::m, "t1").start();
try {
TimeUnit.SECONDS.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
t.running = false;
}
}无volatile运行结果左,有volatile运行结果右:
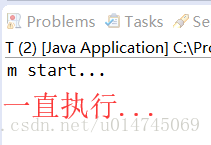
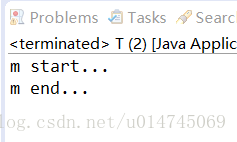
结果分析
在上面代码中,变量running存在于堆内存的 t 对象中。
当线程 t1 开始运行的时候,会把running值从内存中读到 t1 线程的工作区,在运行过程中直接使用这个copy,并不会每次都去读取堆内存,这样,在主线程修改running 的值之后,t1 线程忙于执行while死循环(这里有个变式,如果在while循环中加入一些执行的代码,让线程有时间在下一次循环之前读取一下running的值,可能结果会有不同)而感知不到,所以不会停止运行。
使用volatile ,会强制所有线程都去堆内存中读取 running 的值。
volatile与synchronized区别
volatile与synchronized区别体现在原子性上。
public class T {
volatile int count = 0;
void m() {
for (int i = 0; i < 10000; i++)
count++;
}
public static void main(String[] args) {
T t = new T();
List<Thread> threads = new ArrayList<>();
for (int i = 0; i < 10; i++) {
threads.add(new Thread(t::m, "t" + i));
}
threads.forEach((o) -> o.start());
threads.forEach((o) -> {
try {
o.join();
} catch (Exception e) {
e.printStackTrace();
}
});
System.out.println(t.count);
}
}上面代码中,成员变量count 在线程之间可见,10个线程共同完成为count 自加10000的操作,并通过join()方法将10个线程结果合到一起,我们理想的计算结果应该是count 被加了10,0000次(10个线程每个线程加10000次),但是执行结果却是:

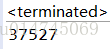

结果分析
volatile保证了数据的可见性,但是没有保证对数据操作的原子性,也就是说,共享数据可能会因高并发被同一个值覆盖。通俗点解释,多个线程同时改变主内存中的某个值的时候,一个线程改变了这个值,并通知给其他线程及时更新自己线程内缓冲区的副本,但是由于线程改变volatile修饰的变量后需要写入到公共内存中+其他线程再读取,这个过程必然会慢于其他线程写出的速度,导致其他线程还没来得及更新自己副本变量就执行了写出,导致主内存中的数据被覆盖,因此在高并发的情况下不对某个数据的写入加锁,即便设置了volatile可见性,依然会出现问题。
因此,volatile比synchronized速度快很多,所以,如果程序中只需要保证可见性,那就要使用volatile;而如果要同时保证
可见性 + 原子性 ,则一定要加锁。
解决不一致问题(扩展)
上一节中volatile无法保证原子性,导致最后的结果远远小于10,0000,除了比较常规的将count++ 加锁之外是否有其他的比较好的解决方法呢?
/**
* 解决同样的问题更高效的方法,是使用AtomicXXX类,
* AtomicXXX类中的每一个方法都是原子性的,但是不能保证多个方法连续调用是原子性的。
*/
public class T {
// volatile int count = 0;
AtomicInteger count = new AtomicInteger(0);
void m() {
for (int i = 0; i < 10000; i++)
// count++;
count.getAndIncrement();
}
public static void main(String[] args) {
T t = new T();
List<Thread> threads = new ArrayList<>();
for (int i = 0; i < 10; i++) {
threads.add(new Thread(t::m, "t" + i));
}
threads.forEach((o) -> o.start());
threads.forEach((o) -> {
try {
o.join();
} catch (Exception e) {
e.printStackTrace();
}
});
System.out.println(t.count);
}
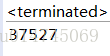
}上述代码解决了volatile无法保证原子性的问题,使用AtomicXXX类,可以保证其方法操作是原子性的,执行结果如下:

incrementAndGet()方法,可以理解为加了synchronized的count++(保证了count++的原子性),但其实它的实现并不是通过synchronized而是使用了一种系统相当底层的实现,所以AtomicXXX类中方法的效率要比synchronized高很多。所以,对于纯计算的操作,建议使用AtomicXXX类。
总结
A B线程都用到了一个变量,Java默认是A线程中保留一个copy , 这样如果B 线程修改了该变量,则A线程未必知道。
使用volatile关键字,会让所有线程都会读到变量的修改值。
但是,使用volatile并不能保证在多个线程共同修改共享变量时所带来的不一致问题,也就是说volatile 不能代替 synchronized。
参考:《马士兵-高并发编程》56:35-67:00 + 68:50