volatile是轻量级的synchronized,它在多处理器开发中保证了共享变量的“可见性”。可见性的意思是当一个线程修改一个共享变量时,另外一个线程能读到这个修改的值。volatile执行成本比synchronized底,因为它不会引起线程上下文的切换和调度。
如果一个字段被声明成volatile,Java线程内存模型确保所有线程看到这个变量的值是一致。

Cpu术语定义
有volatile变量修饰的共享变量进行写操作的时候会多出第二行汇编代码
0x01a3de1d: movb $0×0,0×1104800(%esi);0x01a3de24: lock addl $0×0,(%esp);
Lock前缀的指令在多核处理器下会引发了两件事情:
1)将当前处理器缓存行的数据写回到系统内存。
2)这个写回内存的操作会使在其他CPU里缓存了该内存地址的数据无效。
为了提高处理速度,处理器不直接和内存进行通信,而是先将系统内存的数据读到内部缓存(L1,L2或其他)后再进行操作,但操作完不知道何时会写到内存。如果对声明了volatile的变量进行写操作,JVM就会向处理器发送一条Lock前缀的指令,将这个变量所在缓存行的数据写回到系统内存。
在多处理器下,为了保证各个处理器的缓存是一致的,就会实现缓存一致性协议,每个处理器通过嗅探在总线上传播的数据来检查自己缓存的值是不是过期了,当处理器发现自己缓存行对应的内存地址被修改,就会将当前处理器的缓存行设置成无效状
态,当处理器对这个数据进行修改操作的时候,会重新从系统内存中把数据读到处理器缓存里。
volatile的两条实现原则:
- Lock前缀指令会引起处理器缓存回写到内存。
- 一个处理器的缓存回写到内存会导致其他处理器的缓存无效。
对volatile变量的单个读/写,看成是使用同一个锁对这些单个读/写操作做了同步。
事例:
class VolatileFeaturesExample {
volatile long vl = 0L; //使用volatile声明64位的long型变量
public void set(long l) {
vl = l; //单个volatile变量的写
}
public void getAndIncrement() {
vl++; //复合(多个)volatile变量的读/写
}
public long get() {
return vl; //单个volatile变量的读
}
}程序语义等价:
class VolatileFeaturesExample1 {
long vl = 0L; // 64位的long型普通变量
public synchronized void set(long l) {//对单个的普通变量的写用同一个锁同步
vl = l;
}
public void getAndIncrement() { //普通方法调用
long temp = get(); //调用已同步的读方法
temp += 1L; //普通写操作
set(temp); //调用已同步的写方法
}
public synchronized long get() { //对单个的普通变量的读用同一个锁同步
return vl;
}
}锁的happens-before规则保证释放锁和获取锁的两个线程之间的内存可见性,这意味着对一个volatile变量的读,总是能看到(任意线程)对这个volatile变量最后的写入。
锁的语义决定了临界区代码的执行具有原子性。
volatile变量特性:
可见性。对一个volatile变量的读,总是能看到(任意线程)对这个volatile变量最后的写入。
原子性:对任意单个volatile变量的读/写具有原子性,但类似于volatile++这种复合操作不具有原子性。
volatile写-读的内存语义
当写一个volatile变量时,JMM会把该线程对应的本地内存中的共享变量值刷新到主内存。
当读一个volatile变量时,JMM会把该线程对应的本地内存置为无效。线程接下来将从主内存中读取共享变量。

共享变量的状态示意图

volatile重排序规则表
当第二个操作是volatile写时,不管第一个操作是什么,都不能重排序。这个规则确保volatile写之前的操作不会被编译器重排序到volatile写之后。
当第一个操作是volatile读时,不管第二个操作是什么,都不能重排序。这个规则确保volatile读之后的操作不会被编译器重排序到volatile读之前。
当第一个操作是volatile写,第二个操作是volatile读时,不能重排序。
为了实现volatile的内存语义,编译器在生成字节码时,会在指令序列中插入内存屏障来禁止特定类型的处理器重排序。
基于保守策略的JMM内存屏障插入策略:
在每个volatile写操作的前面插入一个StoreStore屏障。
在每个volatile写操作的后面插入一个StoreLoad屏障。
在每个volatile读操作的后面插入一个LoadLoad屏障。
在每个volatile读操作的后面插入一个LoadStore屏障。


指令序列示意图
StoreStore屏障可以保证在volatile写之前,其前面的所有普通写操作已经对任意处理器可见了。这是因为StoreStore屏障将保障上面所有的普通写在volatile写之前刷新到主内存。
StoreLoad屏障。此屏障的作用是避免volatile写与后面可能有的volatile读/写操作重排序
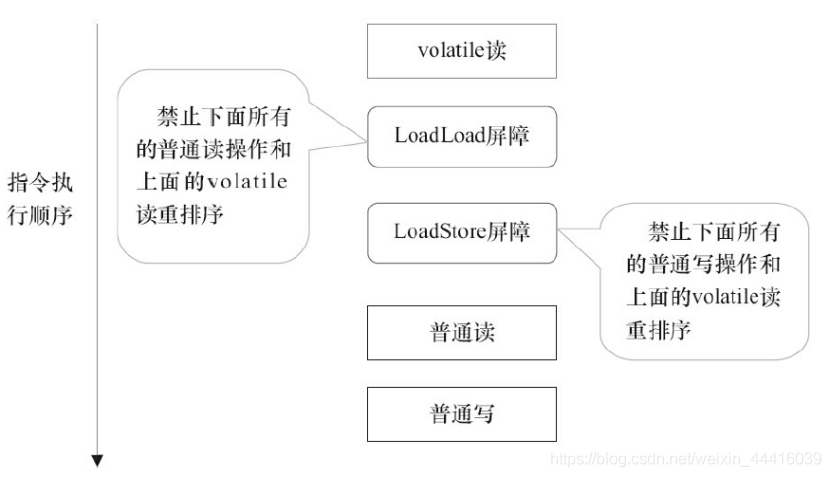
LoadLoad屏障用来禁止处理器把上面的volatile读与下面的普通读重排序。
LoadStore屏障用来禁止处理器把上面的volatile读与下面的普通写重排序。
class VolatileBarrierExample {
int a;
volatile int v1 = 1;
volatile int v2 = 2;
void readAndWrite() {
int i = v1; //第一个volatile读
int j = v2; // 第二个volatile读
a = i + j; //普通写
v1 = i + 1; // 第一个volatile写
v2 = j * 2; //第二个 volatile写
}
//… //其他方法
}
注意,最后的StoreLoad屏障不能省略。因为第二个volatile写之后,方法立即return。此时编译器可能无法准确断定后面是否会有volatile读或写,为了安全起见,编译器通常会在这里插
入一个StoreLoad屏障。
X86处理器可以优化成:
