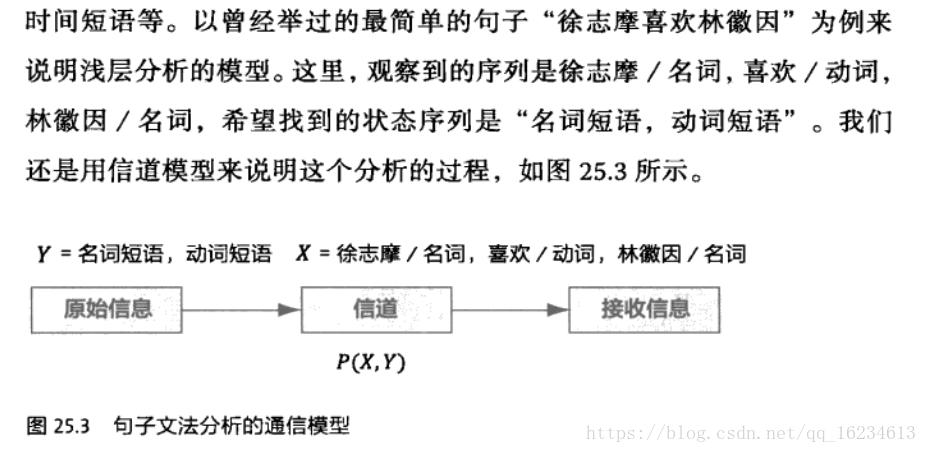
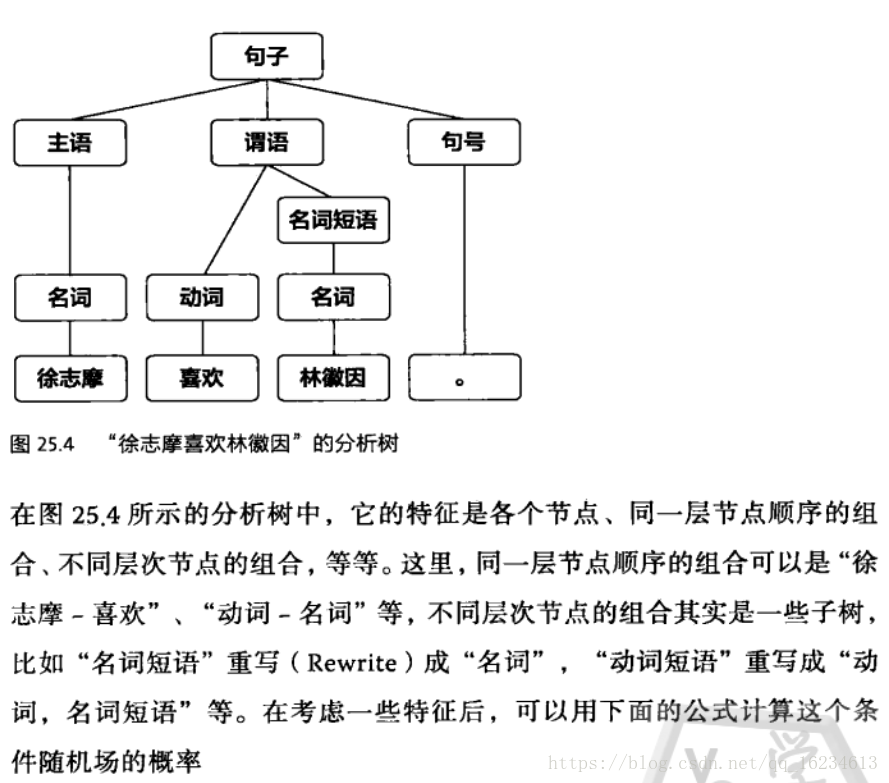
句法分析就是为每个句子建立语法树。最初的句法分析,受形式语言的影响,使用的是规则方法,不断使用规则树从底向上的将树的末端节点向上合并,直到合并出根节点。当然也可以使用自顶向下的方法。但这种方法不能一次选对,一旦选错一步,就需要回溯很多步,因此计算复杂度特别高。后来出现在选择文法规则时,坚持一个原则:让被分析的句子的语法树概率达到最大。这方法虽然简单,却降低了复杂度,提高了准确度。而且在句法分析和数学之间搭建起了桥梁。
拉纳帕提从一个全新的角度看待句法分析,他将句法分析看待成一个阔括号过程。


为了判断是哪种操作,拉纳帕提建立了一个统计模型P(A|prefix);其中A表示采取哪种动作,prefix表示从句子开头到目前为止所有的词和语法分析。最终拉纳帕提使用最大熵模型来实现这个模型。这种方法速度非常快,每次扫描,句子成分数量就按一定比例减少,因此扫描次数是句子长度的对数函数。
但以上模型对于常规的句子分析效果很好,对于广大网民随意书写的句子准确率不高。所幸的是在自然语言处理中我们一般不需要非常深入那些的考虑句子成分,而只需要对句子做浅层分析,如找出句子中主要词组,分析它们之间的关系。因此随后的科学家采用了一种新的模型:条件随机场。
条件随机场:
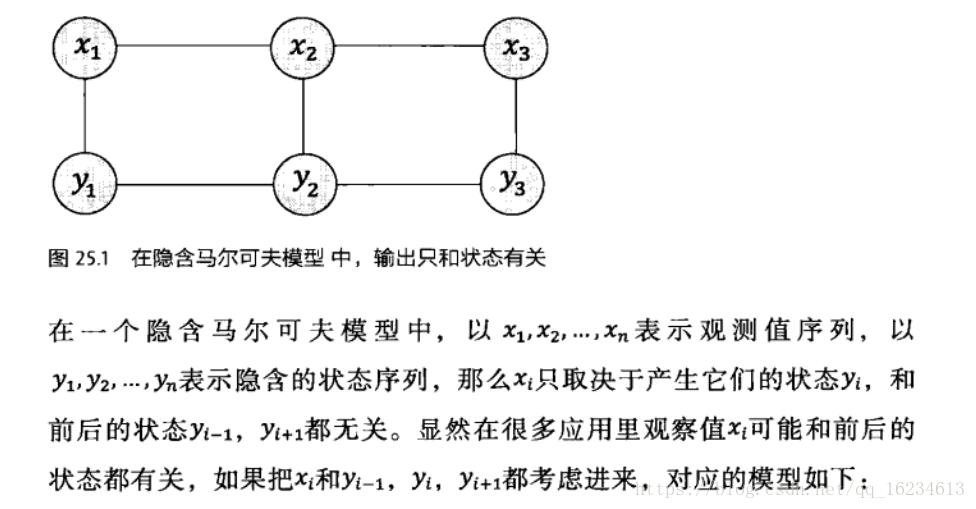
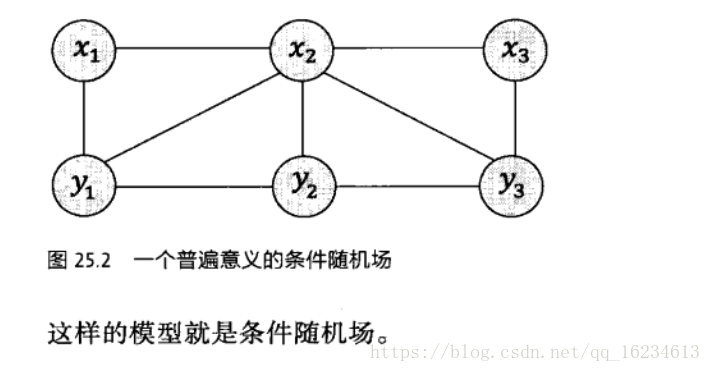
HMM模型基于马尔科夫假设和独立输出假设,但在条件随机场中,不再做独立输出假设,而是认为输出与前后都有关系。所以可以看成是HMM的一种扩展。更广义的讲,条件随机场是一种特殊的概率图模型。其特殊性在于变量间遵循马尔科夫假设,这一点和前面介绍到的贝叶斯网络相同,不同在于条件随机场是无向图,而贝叶斯网络是有向图。

由于模型参数很多,没有足够数据来直接估计。因此只能使用一些边缘分布,如P(X1),P(Y2),P(X1,Y3)来找出符合这些条件的概率分布函数。当然这种函数不可能只有一个。因此根据最大熵原则,我们希望找到一个符合所有边缘分布,且熵达到最大的模型。前面介绍过,这个模型就是指数函数,每一个边缘分布对应指数函数中的一个特征fi。比如针对x1的边缘分布特征就是:

以句法分析为例:
假设X代表所看到的东西,在浅层分析中是句子中的词、词性等;Y代表要推导的东西,它是语法成分,如名词短语,动词短语等。