句法分析是在计算机系统的基础上进行发展的,常见的句法分析应用有: 计算机的翻译、文字的注释、一对一的问答系统、信息的自然摘录以及自动搜索等。如果对句法分析这一词不了解,那么一定知道文法分析,这是该定义不同的两个说法。句法分析说白了就是在一定规则的语法中,进行句子以及句法单位的自动识别,并按照规定输出识别。常见的汉语理解是分几个步骤的,一般都会包含待翻译文章的输入、文章词句的切分、词语属性分析标注、生成目的标注等。长期以来句法的分析都是各个国家所研究的课题,也是公认的一个难题。句法分析的机器理念出自于 20 世纪的 50 年代,大概是在 60 年代时有了相应的成果。
句法分析的难点
( 一) 语句歧义
汉语言文化博大精深,很多词都有多种意思,即便是一个很简单的语句,都有可能有很多种的结果,所以句子语法的分析非常重要
( 二) 汉语的搜索量太大
语法的分析是一个极其复杂的过程,一般完成一个语法的分析需要很多的数据支持,根据不同的语句长度也会有不同的数据要求
句法的机构

不同的汉语句法结构,会有不同的句法计算方式,所以先要了解句法的机构。短语结构语法和依存关系语法是现在常见的两种语法关系,当然还有其他的句法体系,在此只做简单的介绍,并不展开分析。短语结构语法拥有不同的层级,他们之间都是阐述了语法、语言和自动机之间的关系。短语结构语法呈现一个树分类关系,句法根据一定的规则进行转换分析。每一个词的转换都是需要按照设定的树值规则进行目的性的转换。
依存语法( 从属关系语法) ,该项理论的提出是由法国的语言家———思尼耶尔提出的,在思尼耶尔提出的概念中,依存的语法句式结构表示的一个依存的关系,并不是一个句法树。每一个依存都是由句子中的支配词和从属词构成,没有规定每一个语句的定义,也没有明确的规则来对依存的关系进行进一步的确定标记。依存语法相较于短语结构更加的自由,所以其在近年来受到越来越多的专家学者的青睐,发展也较为迅速。
除了以上介绍的两种句法体系外,国内外都开展了对句法分析的研究。不论是国外的美国链语法、范畴语法等,还是国内的 HNC 理论都是目前行业内常用的语法,只是由于设定区域的不同,所以使用有一定的局限性。国外的两种语法体系是由美国的 CMU 计算机学院提出的,国内的 HNC 理论则是由黄曾阳教授提出的 。
关于句法结构分析的详细的讲解请看宗老师的书,这里就不叙述了,建议大家先看看CFG,这里就不解释了,他们都是基于文法的,更偏向于语言学,语言学不是我的专长,我擅长统计方面的,因此下面我们看看PCFG
PCFG(Probabilistic Context-Free Grammar,PCFG)
在统计语言模型中,原来比较常用的是隐马尔可夫模型,但隐马尔可夫模型的描述能力等价于随机正则文法,它的描述能力是很有限的,它能统计词与词,词性与词性等短距离依赖,在统计词间长距离依赖便遇到了困难,而且不能用隐马尔可夫模型统计词与短语、短语与短语的规约,不能使用这个模型来统计句法信息和语义信息。因此,基于概率的上下文无关语法
(Probabilistic Context-Free Grammar,PCFG)和随机正则文法在计算语言学领域受到了广泛的关注。基于概率的上下文无关语法可以直接统计语言学中词与词、词与词组以及词组与词组规约信息,并且可以统计由语法规则生成给定句子的概率、一个给定句子最可能的分析、以及由语法规则生成前缀和后缀的概率等等。大家结合宗老师的来看会更好:
原理介绍
为了清楚的介绍概率上下文无关语法,首先对本文要使用的记号做一些说明,如表3-1所示:

概率上下文无关语法是上下文无关语法的一种扩展,一个概率上下文无关语法是一个四元组:
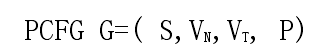
其中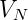
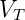
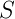
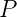
![]() ,
,![]() 是终结符号和非终结符号组成的符号串,
是终结符号和非终结符号组成的符号串,![]() 是产生式的概率,并且有 :
是产生式的概率,并且有 :
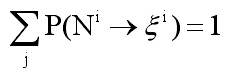
概率上下文无关语法的规则可分为两类,一部分规则的右端出现的是某种语言中的词汇,这些规则可以成为词汇规则;另一部分规则的左端出现的是词汇类别或短语类别符号,一般称为语法规则。 语法的作用在于帮助进行句子的句法分析,概率上下文无关语法也是这样。依据概率上下文无关语法进行句子的句法分析,首先要得到该句子的句法分析树,这与利用上下文无关语法分析句子类似。 在自然语言中,歧义现象是天然地大量存在着的,而且这些歧义的解释往往都有可能是合理的,因此,对歧义现象的处理是自然语言句法分析器最本质的要求。人们正常交流中所使用的语言,放在特定的环境下看,一般是没有歧义的,否则人们将无法交流(某些特殊情况如幽默或双关语除外),如果不考虑语言所处的环境和语言单位的上下文,将会发现语言的歧义现象无所不在。
一般来说,语言单位的歧义现象在引入更大的上下文范围或者语言环境时总是可以被被消解的。句法分析的核心任务就是消解一个句子在句法结构上的歧义。 概率上下文无关语法提供了一条解决句法排歧问题的途径。概率型上下文无关语法通过为每条产生式规则指派一个概率值,扩展了标准的上下文无关语法(CFG)描述体系,即PCFG为CFG中的每条规则增加一个概率值。
可以表示为![]() ,并且满足以下的概率一致化条件:
,并且满足以下的概率一致化条件:![]() 。利用这个分布概率值,我们可以很方便地应用概率论中很完备的计算工具来完成句法排歧任务。即利用附在每条规则后的概率值给每棵分析树计算出一个概率值,利用这个概率值作为评价分析树的依据,拥有最大概率值的分析树就是最可能的分析树。 计算一个句子的概率,最为直接的方法是通过计算出这个句子所有可能的分析树的概率,然后对它们求和。
。利用这个分布概率值,我们可以很方便地应用概率论中很完备的计算工具来完成句法排歧任务。即利用附在每条规则后的概率值给每棵分析树计算出一个概率值,利用这个概率值作为评价分析树的依据,拥有最大概率值的分析树就是最可能的分析树。 计算一个句子的概率,最为直接的方法是通过计算出这个句子所有可能的分析树的概率,然后对它们求和。
实例
在本文产生式规则所用符号说明,如表3-2所示:

下面是一组产生式规则:
上下文无关文法(CFG)的产生式规则如下:
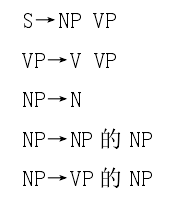
概率上下文无关语法的产生式规则如下:

下面是对句子“老虎咬死了猎人的狗。”的概率计算。图 3-2 是例句的词性标注。

例句的概率P(S)为:
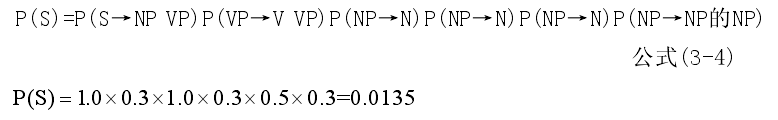
PCFG三个假设 :
使用概率上下文无关语法进行句法分析,需要先做如下三个假设。
位置无关性假设
子结点概率与子结点所管辖的字符串在句子中的位置无关,即![]() 相同。
相同。
下面的例子说明假设1)的含义。对于句子:
![]()
有如图句法结构树。

在句子的位置1,有一个ART1→a,在位置4也有一个ART2→a,可以看成是结点ART处在句子的不同位置,但只要他们的管辖的结点都是相同的(即用了相同的词汇规则),则每个ART结点的概率均相同。也就是说ART只与其管辖的词a有关,而与该词在句子中所处的位置无关。对于句法树中出现的两个NP也是一样的情况,由于两个NP均管辖相同的串(ART N),可看成是结点NP处在句子的不同位置,它们的概率依据假设也是相同的。
上下文无关假设
子结点概率与不受子结点管辖的其他符号串无关,即

例如,在上面例句中,如果把saw换成bought,ART,NP等结点的概率值保持不变。该假设是上下文无关假设在概率上的体现,不仅重写规则是上下文无关的,而且重写规则的概率也是无关的。
祖先结点无关性假设
子结点概率与导出该结点的所有祖先结点的概率无关。
有了这三个假设,概率上下文无关语法就不仅继承了语法本身(无附带概率时)的上下文无关,还使得概率值也能够上下文无关的相同使用。这样就可以利用概率上下文无关语法的句法分析算法,得到句子的句法分析树;然后,为每个结点附带一个概率值,在上述三个假设下,每个结点的概率值就是对该结点进行进一步重写所使用的规则后面附带的概率。
三个基本问题
给定一个符号串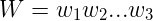
1) 如何快速计算由G产生符号串W的概率P(W|G)?
2) 如果W有多种可能的语法树,如何选择一棵最好的树?
3) 如何调整G的规则概率参数,使得P(W|G)最大?
为了解决上面的三个问题,下面介绍本系统用的三种概率上下文无关语言的基本算法。其中包括向内算法,viberbi 算法,向内-向外算法。
向内算法
所示非终结符A的内部概率(inside probability)定义为:根据文法G从A推出词串…的概率,记做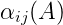
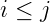

向内算法公式:
![]()
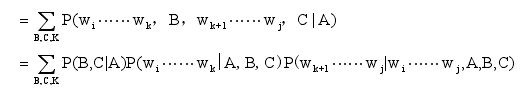
利用独立性假设可以推导成下式:
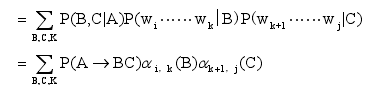
当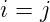

向内算法的过程描述:(自底向上)

Viterbi算法
通过 Viterbi 算法可以有效地找出最为可能的分析树。为了介绍该算法,首先引入变量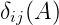
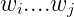
产生出词串

不解释了,不理解维特比算法的建议看我起前面的博客,我有详细讲解过,这里直接给出步骤了。维特比算法详解
向内-向外算法
图 4-3 所示非终结符 A 的外部概率(outside probability)定义为:根据文法 G 从 A 推出词串 
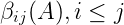
外部概率公式如下:
以上述例句“John ate fish with bone。”为例,通过向内向外算法分析如下:

好了 ,本节就到这里,这里的三个问题可以类比于隐马尔可夫的问题,结合理解就容易了。