版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/u013985879/article/details/82731896
本案例仅用于学术交流!
原文地址 https://github.com/fuyunzhishang/python-spider
效果图
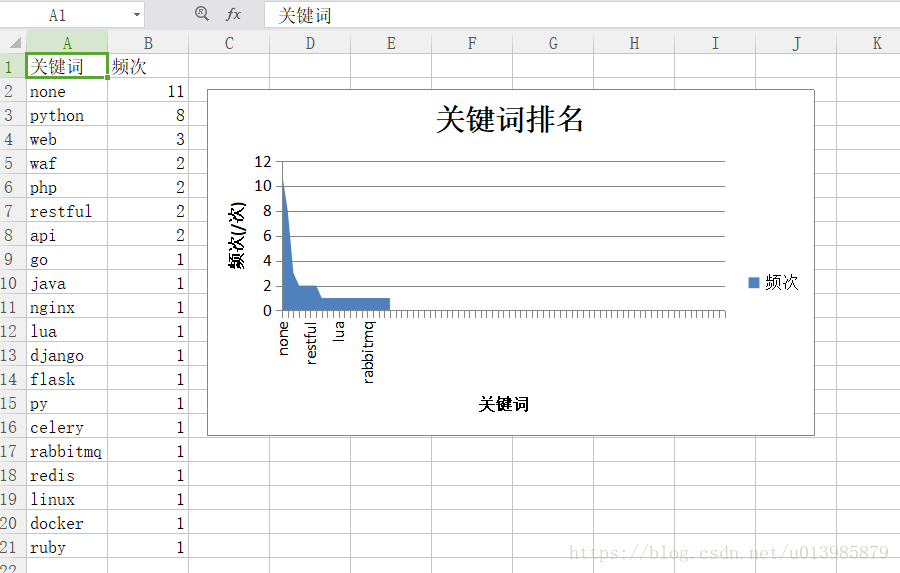
爬取第二页的时候会提示操作太频繁,后期会考虑优化方案
import re
import time
import requests
import xlsxwriter
from bs4 import BeautifulSoup
from collections import Counter
BASE_URL = "https://www.lagou.com/jobs/positionAjax.json?city=%E5%8C%97%E4%BA%AC&needAddtionalResult=false"
def get_page(base_url,pn,keyword):
if pn == 1:
boo = True
else:
boo = False
# proxies = {
# "http":"http://61.135.217.7:80",
# }
formdata = {
"first":boo,
"pn": pn,
"kd": keyword,
}
headers = {
"Content-Length": str(len(formdata)),
"Host": "www.lagou.com",
"Origin": "https://www.lagou.com",
"Referer": "https://www.lagou.com/jobs/list_Python?city=%E5%8C%97%E4%BA%AC&cl=false&fromSearch=true&labelWords=&suginput=",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.81 Safari/537.36",
"X - Anit - Forge - Code": "0",
"X - Anit - Forge - Token": None,
"X - Requested - With": "XMLHttpRequest",
}
req = requests.post(url=BASE_URL,headers=headers,data=formdata)#proxies=proxies
json_req = req.json()
print("----------------------------{}".format(json_req))
# soup = BeautifulSoup(req.content,'lxml')
# content = soup.select("p")
# print(type(json_req)) #<class 'dict'>
return json_req
# 获取 PositionId
def read_positionId(json_req):
tag = "positionId"
# page_json = json.loads(soup)
page_json = json_req['content']['positionResult']['result']
company_list = []
for i in range(0,15): #查询列表每页展示15条
# print("company_list_positionId = {}".format(page_json[i].get(tag)))
company_list.append(page_json[i].get(tag))
return company_list
# 合成目标url
# 获取职位详情 由positionId 和 BaseUrl 组成
def get_content(positionId):
detail_page_url =r"https://www.lagou.com/jobs/{}.html".format(positionId)
print("detail_page_url....{}".format(detail_page_url))
headers = {
"Host": "www.lagou.com",
"Referer":detail_page_url,
"Upgrade-Insecure-Requests": "1",
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.81 Safari/537.36"
}
req = requests.get(detail_page_url,headers=headers)
return req
# 对数据进行清洗,获取职位描述信息
def get_result(content):
soup = BeautifulSoup(content.content, 'lxml')
# print("soup...{}".format(soup))
job_description = soup.find("dd", attrs={"class": "job_bt"})
# job_description = soup.select("dd[class='job_bt']") #list
# print("job_description...{}".format(job_description))
job_description = str(job_description)
rule = re.compile(r'<[^>]+>')
result = rule.sub(' ', job_description)
# print("job_description...result:{}".format(result))
return result
# 筛选关键词,得到技能关键词
def get_search_skill(result):
rule = re.compile(r'[a-zA-Z]+')
skill_list = rule.findall(result)
# print("get_search_skill...{}".format(skill_list))
return skill_list
# 对关键词计数,并排序,选取频次排序Top80 的关键词作为样本
def count_skill_list(skill_list):
skill_lower = [i.lower() for i in skill_list] #list 元素转换小写
count_dict = Counter(skill_lower).most_common(80)
# print("count_skill_list...",count_dict) #[('waf', 2), ('php', 1), ('python', 1), ('go', 1), ('java', 1), ('nginx', 1), ('lua', 1)]
return count_dict
# 对结果进行存储并可视化处理 生成area 图
def save_excel(count_dict,file_name):
book = xlsxwriter.Workbook(r'F:\lagou_project\com\lagou\spider\{}.xls'.format(file_name)) #创建你的.xlsx文件
tmp = book.add_worksheet() #增加sheet
row_num = len(count_dict)
for i in range(1,row_num):
if i == 1:
tag_pos = 'A%s' % i
tmp.write_row(tag_pos,['关键词','频次'])
else:
con_pos = 'A%s' % i
k_v = list(count_dict[i-2])
tmp.write_row(con_pos,k_v)
chart1 = book.add_chart({'type':'area'}) #在工作表中创建一个图表对象
chart1.add_series({
'name':'=Sheet1!$B$1',
'categories':'=Sheet1!$A$2:$A$80',
'values':'=Sheet1!$B$2:$B$80'
})
chart1.set_title({'name':'关键词排名'})
chart1.set_x_axis({'name':'关键词'})
chart1.set_y_axis({'name':'频次(/次)'})
tmp.insert_chart('C2',chart1,{'x_offset':15,'y_offset':10})
book.close()
if __name__ == '__main__':
keyword = input("请输入你想查询的关键字:")
all_skill_list = [] #关键词总表
for i in range(1,30):
time.sleep(3)
print("************************正在抓取第 {} 页{} *************************".format(i,keyword))
soup = get_page(BASE_URL,pn=i,keyword=keyword)
company_list = read_positionId(soup)
for id in company_list:
req = get_content(id)
# print(content)
# req = get_content("4904310")
result = get_result(req)
skill_list = get_search_skill(result)
all_skill_list.extend(skill_list)
# print(skill_list)
count_dict = count_skill_list(all_skill_list)
# print("===={}".format(count_dict))
save_excel(count_dict,'0917')