总结(上)链接:https://blog.csdn.net/lipengfei0427/article/details/108995955
四、作用
前三条最重要
1)防止梯度消失与梯度爆炸
(1)关于梯度消失
以sigmoid函数为例子,sigmoid函数使得输出在[0,1]之间。
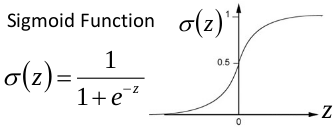
事实上x到了一定大小,经过sigmoid函数的输出范围就很小了,参考下图
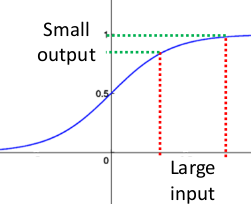
如果输入很大,其对应的斜率就很小,我们知道,其斜率(梯度)在反向传播中是权值学习速率。所以就会出现如下的问题,

在深度网络中,如果网络的激活输出很大,其梯度就很小,学习速率就很慢。假设每层学习梯度都小于最大值0.25,网络有n层,因为链式求导的原因,第一层的梯度小于0.25的n次方,所以学习速率就慢,对于最后一层只需对自身求导1次,梯度就大,学习速率就快。
这会造成的影响是在一个很大的深度网络中,浅层基本不学习,权值变化小,后面几层一直在学习,结果就是,后面几层基本可以表示整个网络,失去了深度的意义。
(2)关于梯度爆炸
根据链式求导法, 第一层偏移量的梯度=激活层斜率1x权值1x激活层斜率2x…激活层斜率(n-1)x权值(n-1)x激活层斜率n
假如激活层斜率均为最大值0.25,所有层的权值为100,这样梯度就会指数增加。
2)允许更大的学习率,大幅提高训练速度
你可以选择比较大的初始学习率,让你的训练速度飙涨。以前还需要慢慢调整学习率,甚至在网络训练到一半的时候,还需要想着学习率进一步调小的比例选择多少比较合适,现在我们可以采用初始很大的学习率,然后学习率的衰减速度也很大,因为这个算法收敛很快。当然这个算法即使你选择了较小的学习率,也比以前的收敛速度快,因为它具有快速训练收敛的特性;
3)改善正则化策略:作为正则化的一种形式,轻微减少了对dropout的需求
你再也不用去理会过拟合中drop out、L2正则项参数的选择问题,采用BN算法后,你可以移除这两项了参数,或者可以选择更小的L2正则约束参数了,因为BN具有提高网络泛化能力的特性;
4)减少对初始化的强烈依赖
5)不需要使用局部响应归一化层了,因为BN本身就是一个归一化网络层
6)可以把训练数据彻底打乱(防止每批训练的时候,某一个样本都经常被挑选到,文献说这个可以提高1%的精度)
五、在卷积网络中使用BN层
BN层同卷积层、池化层一样,都是独立的一层,并且一般用在卷积层和线性层之后,因为非线性单元的输出分布形状会在训练过程中变化,归一化无法消除他的方差偏移,相反的,全连接和卷积层的输出一般是一个对称,非稀疏的一个分布,更加类似高斯分布,对他们进行归一化会产生更加稳定的分布。
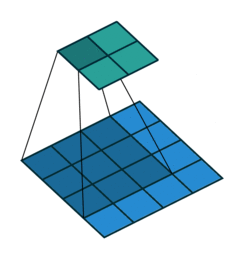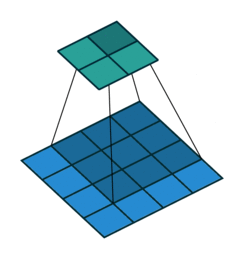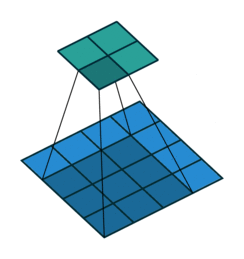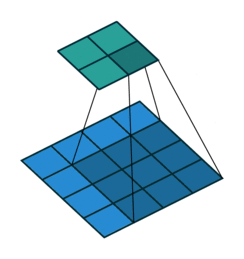
以上图卷积为例,蓝色层为输入,绿色为卷积后的特征图。特征图里的值,作为BN的输入,也就是这4个数值通过BN计算并保存γ与β,通过γ与β使得输出与输入不变。假设输入的batch size为m,那就有m*4个数值,计算这m*4个数据的γ与β并保存。正向传播过程如上述,对于反向传播就是根据求得的γ与β计算梯度。
需要注意两点:
1.网络训练中以batch size为最小单位不断迭代,很显然,新的batch size进入网络,机会有新的γ与β,因此,在BN层中,有总图片数/batch size组γ与β被保存下来。
2.图像卷积的过程中,通常是使用多个卷积核,得到多张特征图,对于多个的卷积核需要保存多个的γ与β。
附一张过程伪代码

六、代码实现(以Pytorch为例)
Pytorch中的BN操作为
nn.BatchNorm2d(self, num_features, eps=1e-5, momentum=0.1, affine=True, track_running_stats=True)num_features:输入数据的通道数,归一化时需要的均值和方差是在每个通道中计算的
eps:用来防止归一化时除以0
momentum:滑动平均的参数,用来计算running_mean和running_var
affine:是否进行仿射变换,即缩放操作
track_running_stats:是否记录训练阶段的均值和方差,即running_mean和running_var
BN层的状态包含五个参数:
weight:缩放操作的γ \gammaγ。
bias:缩放操作的β \betaβ。
running_mean:训练阶段统计的均值,测试阶段会用到。
running_var:训练阶段统计的方差,测试阶段会用到。
num_batches_tracked:训练阶段的batch的数目,如果没有指定momentum,则用它来计算running_mean和running_var。一般momentum默认值为0.1,所以这个属性暂时没用。
weight和bias这两个参数需要训练,而running_mean、running_val和num_batches_tracked不需要训练,它们只是训练阶段的统计值。
#示例
bn = nn.BatchNorm2d(3)
x = torch.randn(4, 3, 2, 2)
y = bn(x) #前向传播一次
a = (x[0, 0, :, :] + x[1, 0, :, :] + x[2, 0, :, :] + x[3, 0, :, :]).sum() / 16
b = (x[0, 1, :, :] + x[1, 1, :, :] + x[2, 1, :, :] + x[3, 1, :, :]).sum() / 16
c = (x[0, 2, :, :] + x[1, 2, :, :] + x[2, 2, :, :] + x[3, 2, :, :]).sum() / 16
print('The mean value of the first channel is %f' % a.data)
print('The mean value of the first channel is %f' % b.data)
print('The mean value of the first channel is %f' % c.data)
print('The output mean value of the BN layer is %f, %f, %f' % (bn.running_mean.data[0], bn.running_mean.data[1], bn.running_mean.data[2]))
参考链接:
https://blog.csdn.net/qq_34886403/article/details/82558399
https://www.zhihu.com/question/61607442
https://blog.csdn.net/sinat_33741547/article/details/87158830
https://blog.csdn.net/m0_37699976/article/details/81584101
https://blog.csdn.net/qq_38900441/article/details/106047525
https://www.cnblogs.com/kk17/p/9693462.html
https://www.jianshu.com/p/fcc056c1c200
https://zhuanlan.zhihu.com/p/75603087