Boosting
Boosting的大概思想是先从初始训练集中训练出一个基学习器,再根据这个基学习器对训练集的判断重新调整训练集,让当前分类器判断错误的样本在后续学习中受到更高的关注,如此不断迭代,直到生成目标数目的基学习器,然后根据权重相加,获得一个强学习器。如下图所示的流程
(上图来自https://blog.csdn.net/willduan1/article/details/73618677)
Boosting一类的算法中AdaBoost是最著名的代表,下图为一个流程:
(上图来自https://www.cnblogs.com/DianaCody/p/5425633.html)
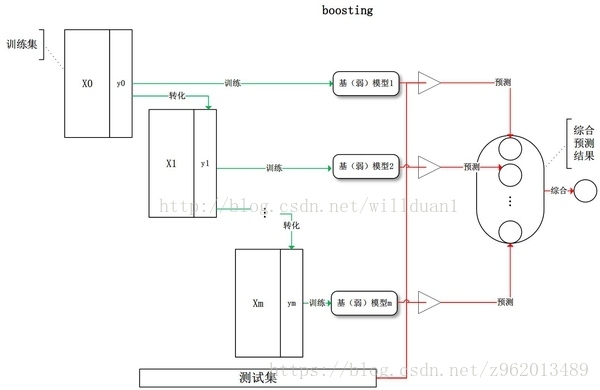
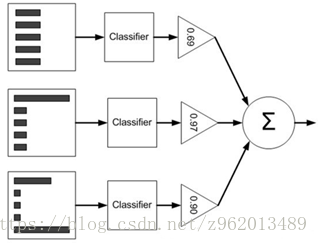
- 第一行左边的图为样本的分布,第一次迭代的时候样本分布是均匀的,然后使用分布均匀的样本训练一个弱分类器,然后根据误差e (这里e实际上是被分类错误的样本的分布权重的和) 计算该分类器的权重 ( ) 并更新样本分布
- 第二次迭代的时候我们就要用新的样本分布下的样本训练弱分类器了,然后再根据误差更新样本分布并计算该分类器的权重
- 循环直到建立了要求的T个弱分类器后停止
这里只简单的讲解了AdaBoost的流程,具体的可以参考https://blog.csdn.net/guyuealian/article/details/70995333,讲的非常清楚
Bagging
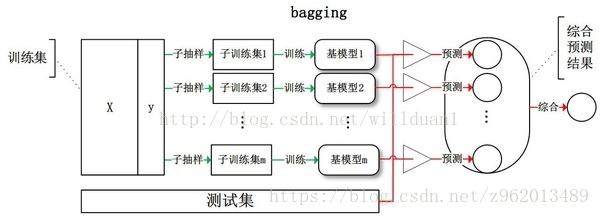
前面说的Boosting由于每次学习的弱学习器都是迭代获得的,因此只能串行计算,而Bagging的特性允许进行并行计算
(图片来自https://blog.csdn.net/willduan1/article/details/73618677)
Bagging的思想是从训练集中抽样出子训练集,分别使用不同的子训练集获得基分类器,然后通常对分类任务使用简单投票法,对回归任务使用简单平均法。
随机森林(Random Forest,RF)是Bagging的一个扩展变体,随机森林使用的基分类器是决策树,但是与传统的决策树不同的是,传统决策树在选择划分属性时在当前结点的属性集合中选择最优属性,而随机森林的决策树是先从该节点的属性集合中随机选择一个包含k个属性的子集,然后从子集中选择最优属性,一般推荐 ,d为样本属性个数
由于前面的博客实现过决策树的代码
(https://blog.csdn.net/z962013489/article/details/80024574)
所以只需要对决策树中的代码稍微修改,就可以完成随机森林的python代码
首先给出获得样本集的代码
# -*- coding: gbk -*-
import pandas as pd
def ReadAndSaveDataByPandas(target_url=None, save=False):
wine = pd.read_csv(target_url, header=0, sep=";")
if save == True:
wine.to_csv("D:\Documents\ml_data\carbon_nanotubes.csv",
sep=' ', index=False)
target_url = "https://archive.ics.uci.edu/ml/machine-learning-databases/glass/glass.data" # 一个玻璃的多分类的数据集
ReadAndSaveDataByPandas(target_url, True)
然后给出决策树的代码 DecisionTree.py
# -*- coding: gbk -*-
import numpy as np
import math
from collections import Counter
class decisionnode:
def __init__(self, d=None, thre=None, results=None, NH=None, lb=None, rb=None, max_label=None):
self.d = d # d表示维度
self.thre = thre # thre表示二分时的比较值,将样本集分为2类
self.results = results # 最后的叶节点代表的类别
self.NH = NH # 存储各节点的样本量与经验熵的乘积,便于剪枝时使用
self.lb = lb # desision node,对应于样本在d维的数据小于thre时,树上相对于当前节点的子树上的节点
self.rb = rb # desision node,对应于样本在d维的数据大于thre时,树上相对于当前节点的子树上的节点
self.max_label = max_label # 记录当前节点包含的label中同类最多的label
def entropy(y):
'''
计算信息熵,y为labels
'''
if y.size > 1:
category = list(set(y))
else:
category = [y.item()]
y = [y.item()]
ent = 0
for label in category:
p = len([label_ for label_ in y if label_ == label]) / len(y)
ent += -p * math.log(p, 2)
return ent
def Gini(y):
'''
计算基尼指数,y为labels
'''
category = list(set(y))
gini = 1
for label in category:
p = len([label_ for label_ in y if label_ == label]) / len(y)
gini += -p * p
return gini
def GainEnt_max(X, y, d):
'''
计算选择属性attr的最大信息增益,X为样本集,y为label,d为一个维度,type为int
'''
ent_X = entropy(y)
X_attr = X[:, d]
X_attr = list(set(X_attr))
X_attr = sorted(X_attr)
Gain = 0
thre = 0
for i in range(len(X_attr) - 1):
thre_temp = (X_attr[i] + X_attr[i + 1]) / 2
y_small_index = [i_arg for i_arg in range(
len(X[:, d])) if X[i_arg, d] <= thre_temp]
y_big_index = [i_arg for i_arg in range(
len(X[:, d])) if X[i_arg, d] > thre_temp]
y_small = y[y_small_index]
y_big = y[y_big_index]
Gain_temp = ent_X - (len(y_small) / len(y)) * \
entropy(y_small) - (len(y_big) / len(y)) * entropy(y_big)
'''
intrinsic_value = -(len(y_small) / len(y)) * math.log(len(y_small) /
len(y), 2) - (len(y_big) / len(y)) * math.log(len(y_big) / len(y), 2)
Gain_temp = Gain_temp / intrinsic_value
'''
# print(Gain_temp)
if Gain < Gain_temp:
Gain = Gain_temp
thre = thre_temp
return Gain, thre
def Gini_index_min(X, y, d):
'''
计算选择属性attr的最小基尼指数,X为样本集,y为label,d为一个维度,type为int
'''
X = X.reshape(-1, len(X.T))
X_attr = X[:, d]
X_attr = list(set(X_attr))
X_attr = sorted(X_attr)
Gini_index = 1
thre = 0
for i in range(len(X_attr) - 1):
thre_temp = (X_attr[i] + X_attr[i + 1]) / 2
y_small_index = [i_arg for i_arg in range(
len(X[:, d])) if X[i_arg, d] <= thre_temp]
y_big_index = [i_arg for i_arg in range(
len(X[:, d])) if X[i_arg, d] > thre_temp]
y_small = y[y_small_index]
y_big = y[y_big_index]
Gini_index_temp = (len(y_small) / len(y)) * \
Gini(y_small) + (len(y_big) / len(y)) * Gini(y_big)
if Gini_index > Gini_index_temp:
Gini_index = Gini_index_temp
thre = thre_temp
return Gini_index, thre
def attribute_based_on_GainEnt(X, y):
'''
基于信息增益选择最优属性,X为样本集,y为label
'''
D = np.arange(len(X[0]))
Gain_max = 0
thre_ = 0
d_ = 0
for d in D:
Gain, thre = GainEnt_max(X, y, d)
if Gain_max < Gain:
Gain_max = Gain
thre_ = thre
d_ = d # 维度标号
return Gain_max, thre_, d_
def attribute_based_on_Giniindex(X, y):
'''
基于信息增益选择最优属性,X为样本集,y为label
'''
D = np.arange(len(X.T))
Gini_Index_Min = 1
thre_ = 0
d_ = 0
for d in D:
Gini_index, thre = Gini_index_min(X, y, d)
if Gini_Index_Min > Gini_index:
Gini_Index_Min = Gini_index
thre_ = thre
d_ = d # 维度标号
return Gini_Index_Min, thre_, d_
def devide_group(X, y, thre, d):
'''
按照维度d下阈值为thre分为两类并返回
'''
X_in_d = X[:, d]
x_small_index = [i_arg for i_arg in range(
len(X[:, d])) if X[i_arg, d] <= thre]
x_big_index = [i_arg for i_arg in range(
len(X[:, d])) if X[i_arg, d] > thre]
X_small = X[x_small_index]
y_small = y[x_small_index]
X_big = X[x_big_index]
y_big = y[x_big_index]
return X_small, y_small, X_big, y_big
def NtHt(y):
'''
计算经验熵与样本数的乘积,用来剪枝,y为labels
'''
if len(y) == 0:
return 0.1
ent = entropy(y)
print('ent={},y_len={},all={}'.format(ent, len(y), ent * len(y)))
return ent * len(y)
def maxlabel(y):
print(y)
label_ = Counter(y).most_common(1)
return label_[0][0]
def ChooseSubsetForRF(X, y, d):
'''
d为属性的个数
'''
k = int(np.log2(d))
index = np.random.choice(d, k, replace=False)
X_sub = X[:, index]
return X_sub, index
def buildtree(X, y, method='Gini'):
'''
递归的方式构建决策树
'''
if y.size > 1:
X_sub, d_index = ChooseSubsetForRF(X, y, d=X.shape[1])
if method == 'Gini':
Gain_max, thre, d = attribute_based_on_Giniindex(X_sub, y)
elif method == 'GainEnt':
Gain_max, thre, d = attribute_based_on_GainEnt(X_sub, y)
if (Gain_max > 0 and method == 'GainEnt') or (Gain_max >= 0 and len(list(set(y))) > 1 and method == 'Gini'):
X_small, y_small, X_big, y_big = devide_group(
X, y, thre, d_index[d])
left_branch = buildtree(X_small, y_small, method=method)
right_branch = buildtree(X_big, y_big, method=method)
nh = NtHt(y)
max_label = maxlabel(y)
return decisionnode(d=d_index[d], thre=thre, NH=nh, lb=left_branch, rb=right_branch, max_label=max_label)
else:
nh = NtHt(y)
max_label = maxlabel(y)
return decisionnode(results=y[0], NH=nh, max_label=max_label)
elif y.size == 1:
nh = NtHt(y)
max_label = maxlabel(y)
return decisionnode(results=y.item(), NH=nh, max_label=max_label)
def classify(observation, tree):
if tree.results != None:
return tree.results
else:
v = observation[tree.d]
branch = None
if v > tree.thre:
branch = tree.rb
else:
branch = tree.lb
return classify(observation, branch)
最后给出随机森林的代码 RandomForest.py
# -*- coding: gbk -*-
import pandas as pd
import numpy as np
import DecisionTree
from collections import Counter
from sklearn.ensemble import RandomForestClassifier
class RF():
def __init__(self, num=5):
self.num = num # 基分类器数量
def random_Xy(self, X, y, per=80):
'''
per表示要取出的X,y中的数量占原来的比重,默认为80%
'''
index = np.random.choice(y.shape[0], int(
y.shape[0] * per / 100), replace=False)
return X[index], y[index]
def fit(self, X, y):
self.tree = []
for i in range(self.num):
X_r, y_r = self.random_Xy(X, y)
self.tree.append(DecisionTree.buildtree(X_r, y_r, method='Gini'))
def predict(self, x):
results = []
for i in range(self.num):
results.append(DecisionTree.classify(x, self.tree[i]))
return Counter(results).most_common(4)[0][0]
if __name__ == '__main__':
dir = 'D:\\Documents\\ml_data\\'
name = 'glass.csv'
obj = pd.read_csv(dir + name, header=None)
data = np.array(obj[:][:])
label = data[:, -1]
label = label.astype(int)
data = data[:, 1:data.shape[1] - 1]
test_index = np.random.choice(label.shape[0], 50, replace=False)
test_label = label[test_index]
test_data = data[test_index]
train_index = np.linspace(
0, data.shape[0], num=data.shape[0], endpoint=False, dtype=int)
train_index = np.delete(train_index, test_index, axis=0)
train_label = label[train_index]
train_data = data[train_index]
rf = RF(num=50)
rf.fit(train_data, train_label)
true_count = 0
for i in range(len(test_label)):
predict = rf.predict(test_data[i])
if predict == test_label[i]:
true_count += 1
print(true_count / test_label.shape[0])
clf = RandomForestClassifier(n_estimators=50)
clf = clf.fit(train_data, train_label)
pl = clf.predict(test_data)
diff = pl - test_label
count1 = 0
for i in diff:
if i == 0:
count1 += 1
print(count1 / test_label.shape[0])
这里同时调用的sklearn中的随机森林,两者进行了比较,运行结束后两者正确率对比如下
自己写的随机森林正确率80%
库函数随机森林正确率84%
生成的决策树都为50个
stacking
前面说的方法对于基学习器的处理都是线性累加,而stacking是通过另一个学习器来对基学习器进行结合的,我们把个体学习器称为出基学习器,把用于结合的学习器称为次级学习器或元学习器(meta-learner)。
(图片来自https://www.cnblogs.com/jiaxin359/p/8559029.html)
在网上看到好多引用这个图的博客,有一些讲解的感觉不是很容易理解,这里我详细记录一下:
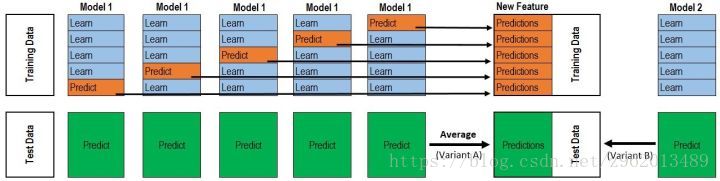
为了防止过拟合,stacking通常用k折交叉验证来进行训练,图中使用的是5折,只用了1个学习器Model1,但是由于这里用了5折交叉验证,因此拥有5个子样本集,所以实际上训练了5个不同的Model1,然后再将那5个子样本集对应的没有训练的样本代入对应的Model1中,得到的预测结果拼起来,变成一个1*n维的向量,作为次级学习器的样本集。
通常stacking算法会使用m种Model1,那么最后获得的供给次级学习器的样本集就是一个m维的n个样本。
全部学习完以后,对于预测,首先将预测样本代入所有的基学习器(5m个),然后同类学习器获得的结果取平均值,最后得到的是1m的向量,代入次级学习器给出最终的预测结果
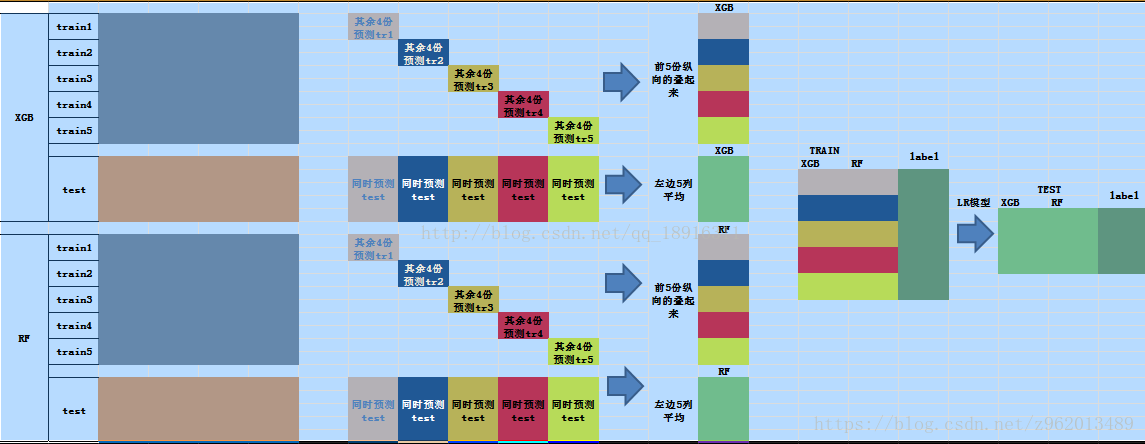
这里还有另外一个图看着更清晰一些:
(图片来自https://blog.csdn.net/qq_18916311/article/details/78557722)
这张图描述的是使用XGB和RF作为基学习器,LR作为次级学习器的stacking
注意:已很强的学习器(如randomForest,SVM, gbm,mboost 等),再用强学习器集成,一般没啥子效果,,该结合特定专业或实际需要,采用特定方法集成,才会对实践有价值
这里我借用sklearn库中的一些分类器作为基学习器写了一个stacking
分类的数据来自http://archive.ics.uci.edu/ml/datasets/Avila,训练集和测试集都有10000多个样本
# -*- coding: gbk -*-
import numpy as np
import pandas as pd
from sklearn.svm import SVC
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier, GradientBoostingClassifier, ExtraTreesClassifier
import copy
class stacking():
def __init__(self, n_folds=5, meta_model_name='svc'):
self.n_folds = n_folds
self.meta_model_name = meta_model_name
try:
if self.meta_model_name == 'svc':
self.meta_model = SVC(gamma=1, C=1)
elif self.meta_model_name == 'gbc':
self.meta_model = GradientBoostingClassifier()
elif self.meta_model_name == 'etc':
self.meta_model = ExtraTreesClassifier()
elif self.meta_model_name == 'dtc':
self.meta_model = DecisionTreeClassifier()
elif self.meta_model_name == 'rfc':
self.meta_model = RandomForestClassifier(n_estimators=50)
except ValueError:
print('error arg')
self.gbc_model = GradientBoostingClassifier()
self.svc_model = SVC(gamma=0.5, C=50)
self.etc_model = ExtraTreesClassifier()
self.dtc_model = DecisionTreeClassifier()
self.rfc_model = RandomForestClassifier(n_estimators=50)
self.gbc_models = []
self.svc_models = []
self.etc_models = []
self.dtc_models = []
self.rfc_models = []
self.base_models = [self.gbc_models, self.svc_models,
self.etc_models, self.dtc_models, self.rfc_models]
def get_n_folds(self, X, y):
n_X = []
n_y = []
for i in range(self.n_folds):
n_X.append(X[i::self.n_folds])
n_y.append(y[i::self.n_folds])
return n_X, n_y
def multi_base_models_train(self, X, y):
n_X, n_y = self.get_n_folds(X, y)
meta_data = np.array([])
meta_label = np.array([])
for i in range(self.n_folds):
index = np.arange(self.n_folds)
index = np.delete(index, i)
# 获取n_fold中除去某一折以后的训练集
n_fold_X = np.array([])
n_fold_y = np.array([])
for k in index:
n_fold_X = np.append(n_fold_X, n_X[k])
n_fold_y = np.append(n_fold_y, n_y[k])
n_fold_X = n_fold_X.reshape(-1, X.shape[1])
part_meta_data = np.array([])
for model_, j in [(self.gbc_model, 0), (self.svc_model, 1), (self.etc_model, 2), (self.dtc_model, 3), (self.rfc_model, 4)]:
# 训练初级分类器
model_.fit(n_fold_X, n_fold_y)
new_model = copy.deepcopy(model_)
self.base_models[j].append(new_model)
predict_y = self.base_models[j][i].predict(n_X[i])
predict_y = predict_y.reshape(-1, 1)
# 将一折的预测label数据作为次级训练集
if j == 0:
part_meta_data = predict_y
else:
part_meta_data = np.append(
part_meta_data, predict_y, axis=1)
if i == 0:
meta_data = part_meta_data
else:
meta_data = np.append(meta_data, part_meta_data, axis=0)
meta_label = np.append(meta_label, n_y[i])
return meta_data, meta_label
def meta_model_train(self, X, y):
self.meta_model.fit(X, y)
def fit(self, X, y):
meta_data, meta_label = self.multi_base_models_train(X, y)
self.meta_model_train(meta_data, meta_label)
def predict(self, XX):
for i in range(self.n_folds): # 选择交叉验证得到的分类器组
for j in range(5): # 选择分类器类型
predict_y = self.base_models[j][i].predict(XX)
predict_y = predict_y.reshape(-1, 1)
if j == 0:
meta_data = predict_y
else:
meta_data = np.append(meta_data, predict_y, axis=1)
if i == 0:
ave_meta_data = meta_data
else:
ave_meta_data = ave_meta_data + meta_data
ave_meta_data = ave_meta_data / self.n_folds
pre = self.meta_model.predict(ave_meta_data)
return pre
def count_true(pre_p, p):#计算正确率
p1 = pre_p - p
count = 0
for i in p1:
if i == 0:
count += 1
print(count / p.shape[0])
if __name__ == '__main__':
label_in = {'A': 0, 'F': 1, 'H': 2, 'E': 3, 'I': 4, 'Y': 5,
'D': 6, 'X': 7, 'G': 8, 'W': 9, 'C': 10, 'B': 11} # 将标签从字母转换为数字,便于使用
dir = 'D:\\Documents\\ml_data\\avila\\'
train_name = 'avila-tr.txt'
test_name = 'avila-ts.txt'
obj = pd.read_csv(dir + train_name, header=None)
data = np.array(obj[:][:])
train_label = data[:, -1]
for i in range(train_label.shape[0]):
train_label[i] = label_in[train_label[i]]
train_label = train_label.astype(int)
train_data = data[:, 0:data.shape[1] - 1]
obj = pd.read_csv(dir + test_name, header=None)
data = np.array(obj[:][:])
test_label = data[:, -1]
for i in range(test_label.shape[0]):
test_label[i] = label_in[test_label[i]]
test_label = test_label.astype(int)
test_data = data[:, 0:data.shape[1] - 1]
stk = stacking(n_folds=5, meta_model_name='dtc')
stk.fit(train_data, train_label)
for j in range(5): # 显示出每个基分类器对测试集的预测正确率
for i in range(stk.n_folds):
a = stk.base_models[j][i].predict(test_data)
count_true(a, test_label)
print('-------')
a = stk.predict(test_data)
count_true(a, test_label)
这里使用5折交叉验证,基学习器为GradientBoostingClassifier, SVC, ExtraTreesClassifier, DecisionTreeClassifier, RandomForestClassifier, 次级学习器为DecisionTreeClassifier,运行结果正确率为95.3%
输出如下:
0.9434703458848328
0.9468237999425122
0.9495065631886558
0.9412666475040721
0.9500814410271151
-------
0.8215004311583789
0.8243748203506754
0.8232250646737568
0.8215962441314554
0.8267701446775894
-------
0.9122353166618761
0.9565009102232442
0.9229663696464502
0.9566925361693973
0.9133850723387946
-------
0.969244035642426
0.9697231005078087
0.964740825907828
0.9622496886078375
0.9381048193925458
-------
0.9767174475423972
0.9736514324039475
0.9743221232154834
0.9743221232154834
0.9758551307847082
-------
0.9531474561655648
这里每5个数据表示同类分类器对测试集的正确率,最后一个是整个stacking预测的正确率,我发现效果不是很好,考虑前面加粗的“注意”说过的话,我尝试将这些很强的学习器换成弱一些的,然而最后的预测正确率很低。
感觉还是有点问题,但是不知道是什么,有知道的同学麻烦评论告知一下,多谢了!
###参考###
《机器学习》周志华
http://bbs.pinggu.org/forum.php?mod=viewthread&tid=6424260
https://blog.csdn.net/qq_18916311/article/details/78557722
https://blog.csdn.net/willduan1/article/details/73618677
https://www.cnblogs.com/jiaxin359/p/8559029.html
https://blog.csdn.net/mys12/article/details/80851212
https://blog.csdn.net/wstcjf/article/details/77989963