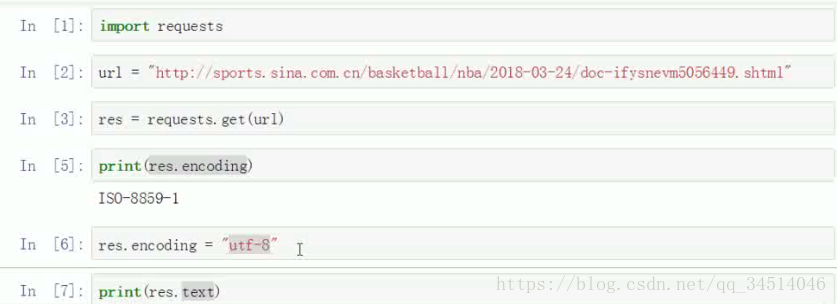
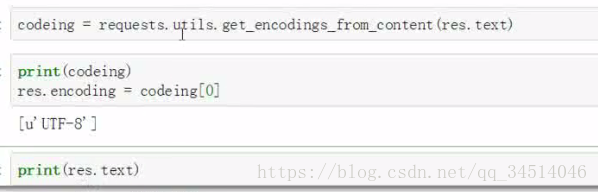
获取网页默认编码
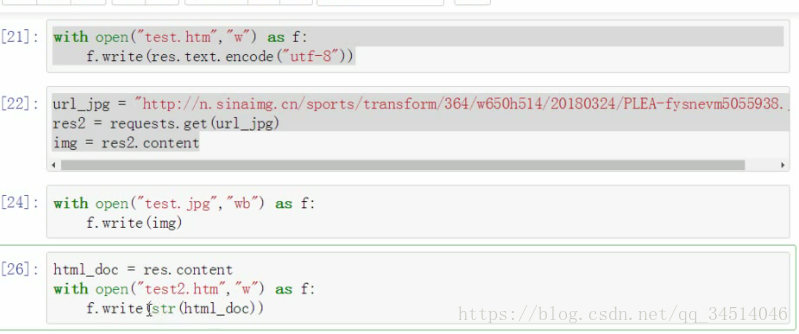
保存我们读取到的网页内容
内容总结:


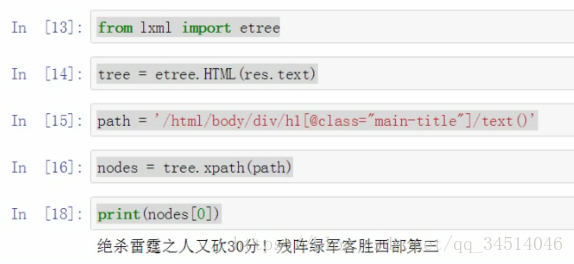
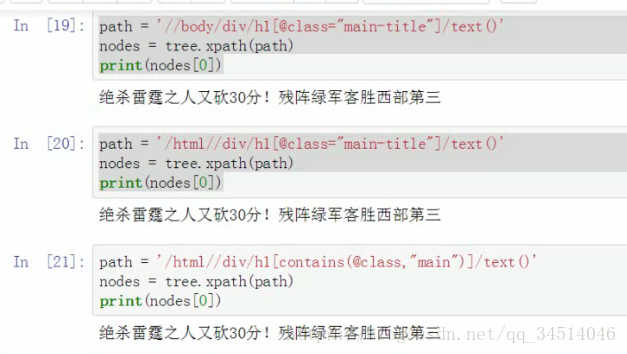
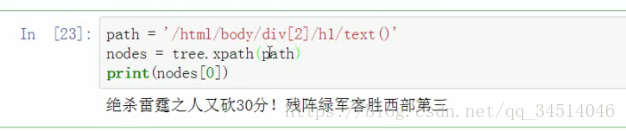
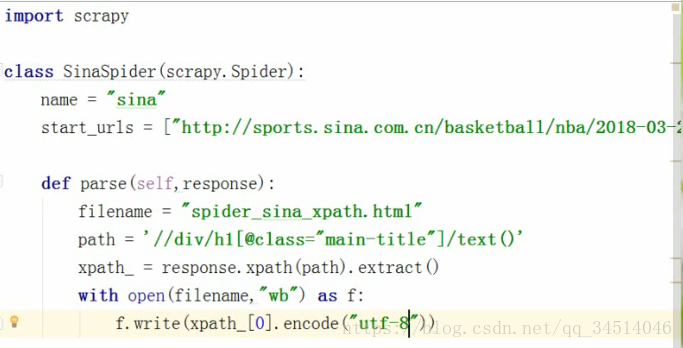
xpath解析html

扫描二维码关注公众号,回复:
3343303 查看本文章


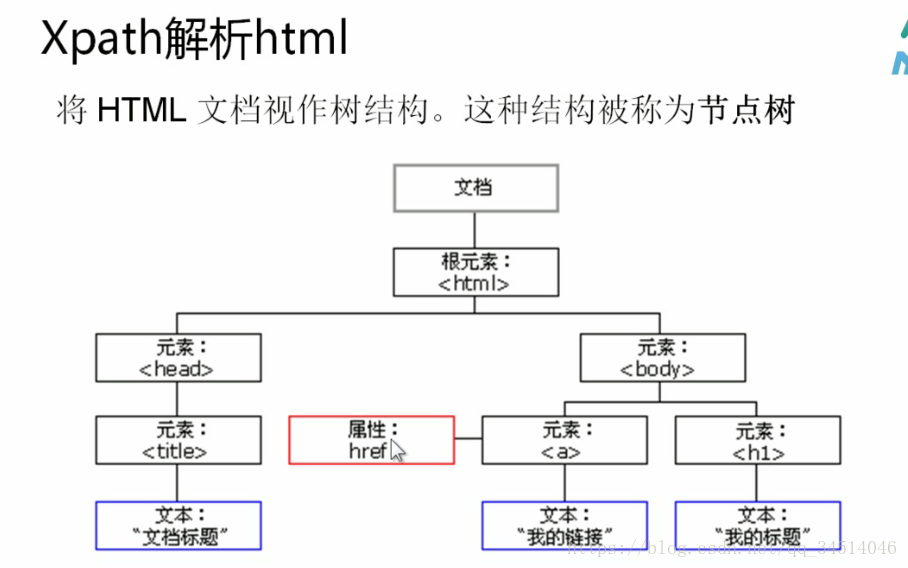
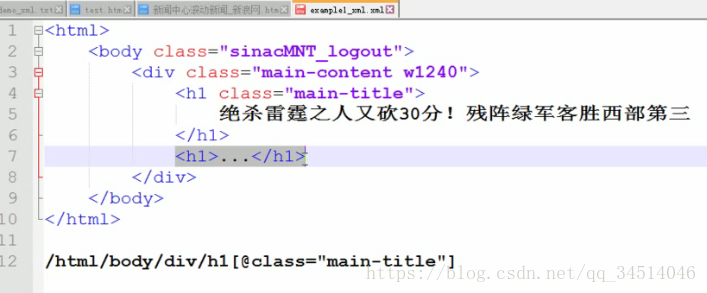
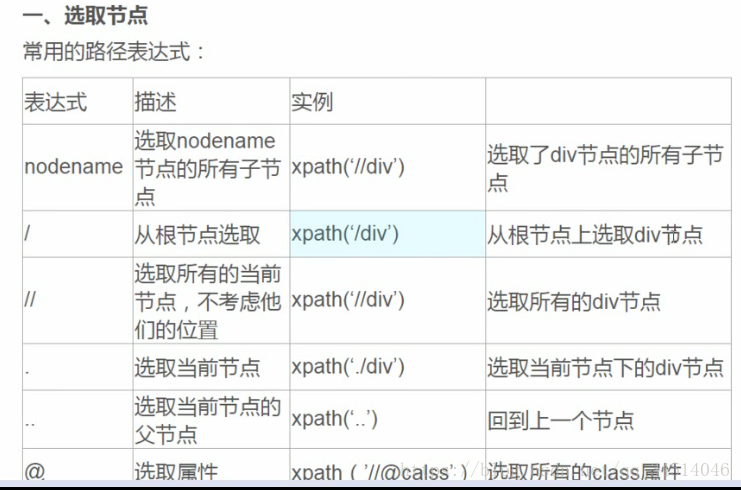
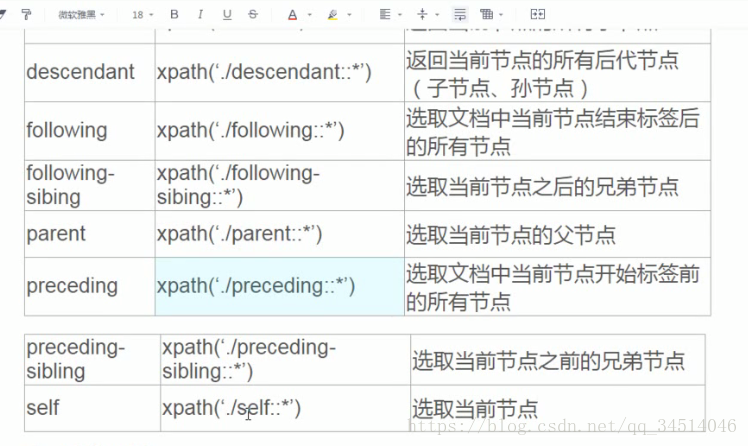
选取节点





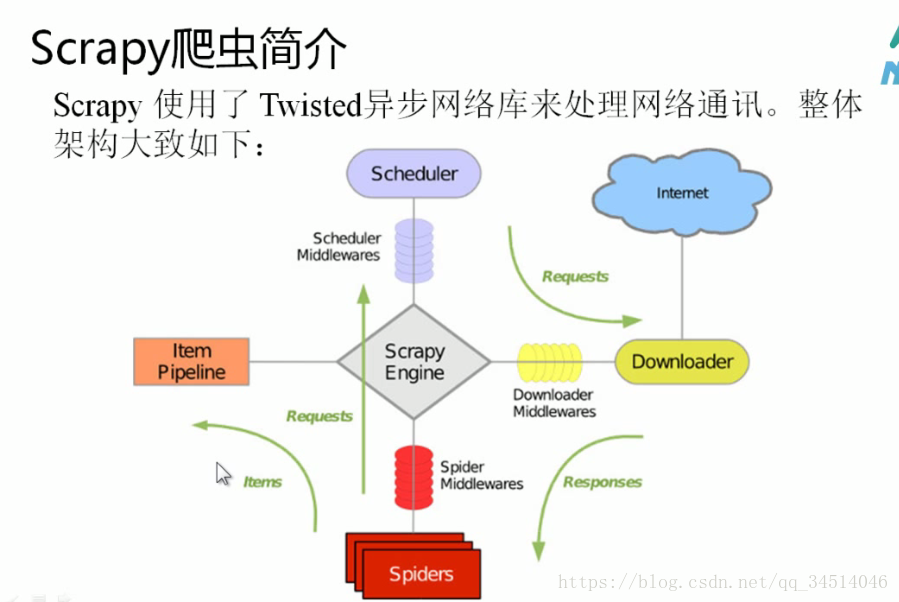
scrapy框架

scrapy项目创建、

Vim items.py要抓取的内容
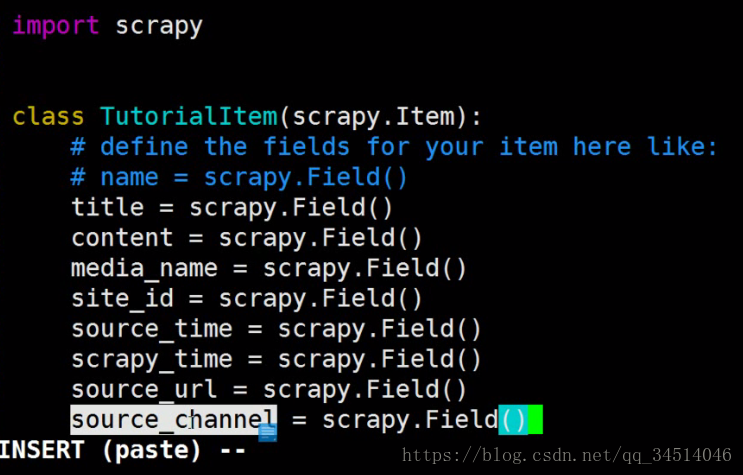
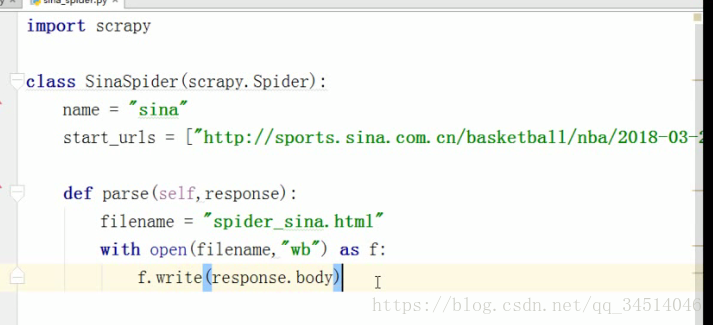
spider爬虫编写



scrapy文本解析:抽取网页中的标题


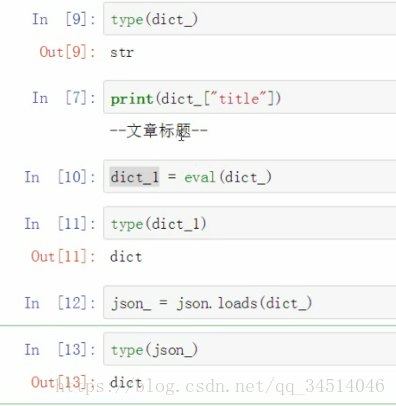
items结构化输出 json存储


第八课没你妈截图,编码只有实战,截图也没用的
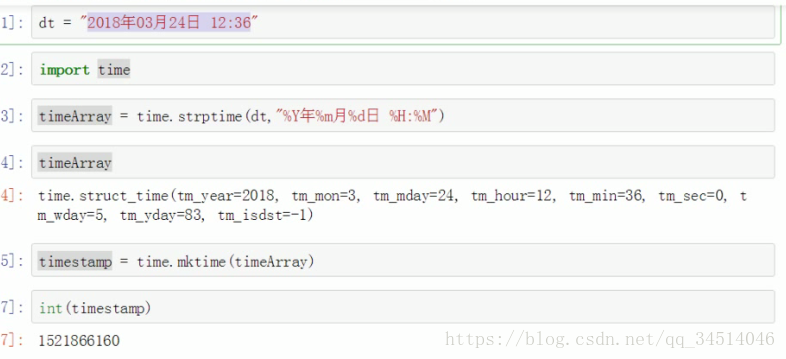
时间戳记录

时间存储的时候:
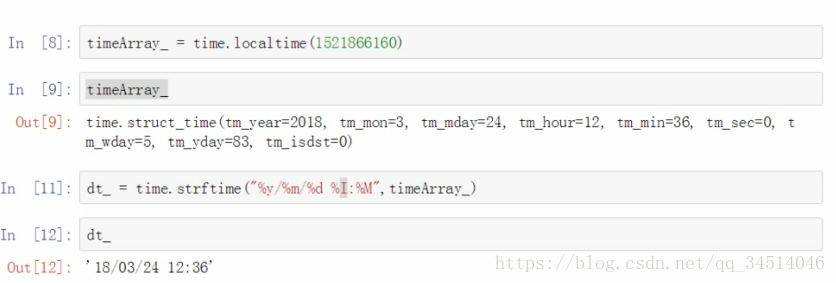
再反转回去:时间展示的时候
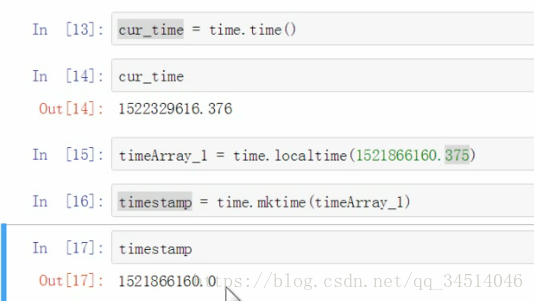
获取当前时间
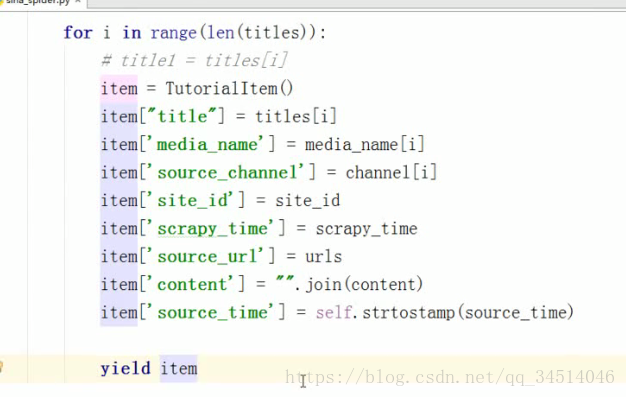
数据持久化存储
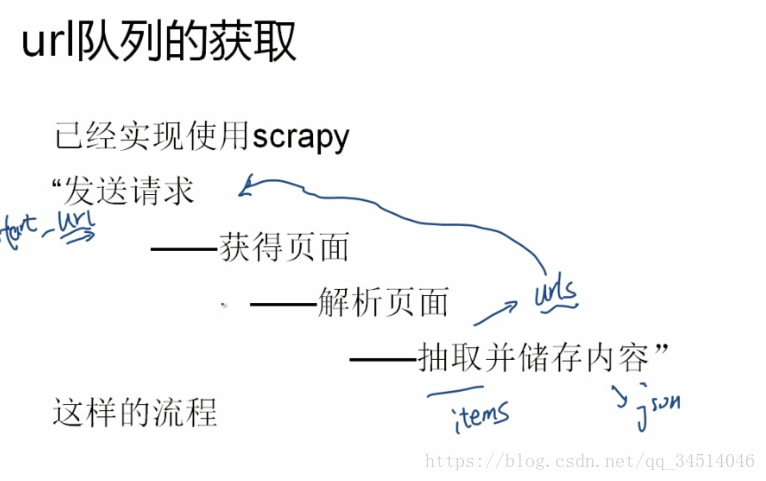
url队列的获取