写在前面的话:从今日起,我会边跟着硅谷大牛Siraj的MOVE 37系列课程学习Reinforcement Learning(强化学习算法),边更新这个系列。课程包含视频和文字,课堂笔记会按视频为单位进行整理。
课程表地址:https://github.com/llSourcell/Move_37_Syllabus
本课作为导论,大致普及了一下机器学习和强化学习的概念和用途。其次,捎带介绍了一下最常见的监督学习和非监督学习。对机器学习稍有了解的同学们,对这两个概念应该不陌生。如果对此毫无概念的同学们,可以看我下面的简单说明。
机器学习(Machine Learning)
首先,我们要明白,所谓的机器学习就是试图找出输入输出量之间的一个固定关系,以期对以后所有的输入量都能相应地去预测一个输出量。用数学语言来说,就是从一堆已知的x和y之间找出映射f。打个比方,如果我们发现每次穿裙子(x)就一定会下雨(y),那么这个因果关系就是f;由此,我们就可以根据f这个关系,也就是某天穿没穿裙子,来推断会不会下雨。
监督学习 (Supervised Learning)
这里举一个水果分类的例子。这里机器学习算法所要完成的工作,就是要得到水果和水果名称之间的关系。
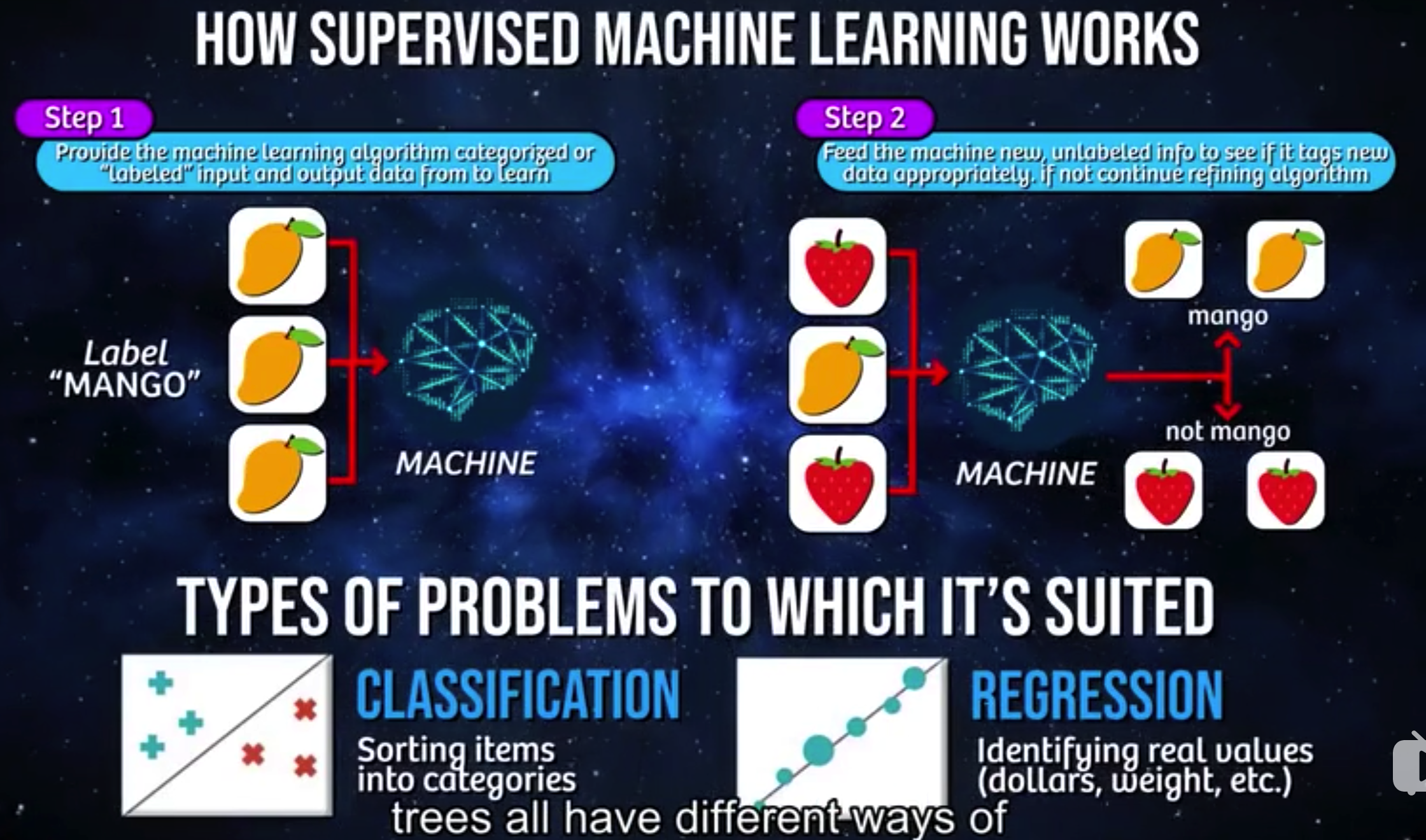
第一步是训练算法,第二步是用测试数据来检验算法的完善度。图中可以看到,这里训练算法时输入的数据是预先分过类的(即打过标签的),所以事先需要人工参与,把未分类的原始数据进行分类。此即是“监督”二字的要义所在,需要人工“监督”才能完成算法的训练。
非监督学习 (Unsupervised Learning)
同样是以水果举例。
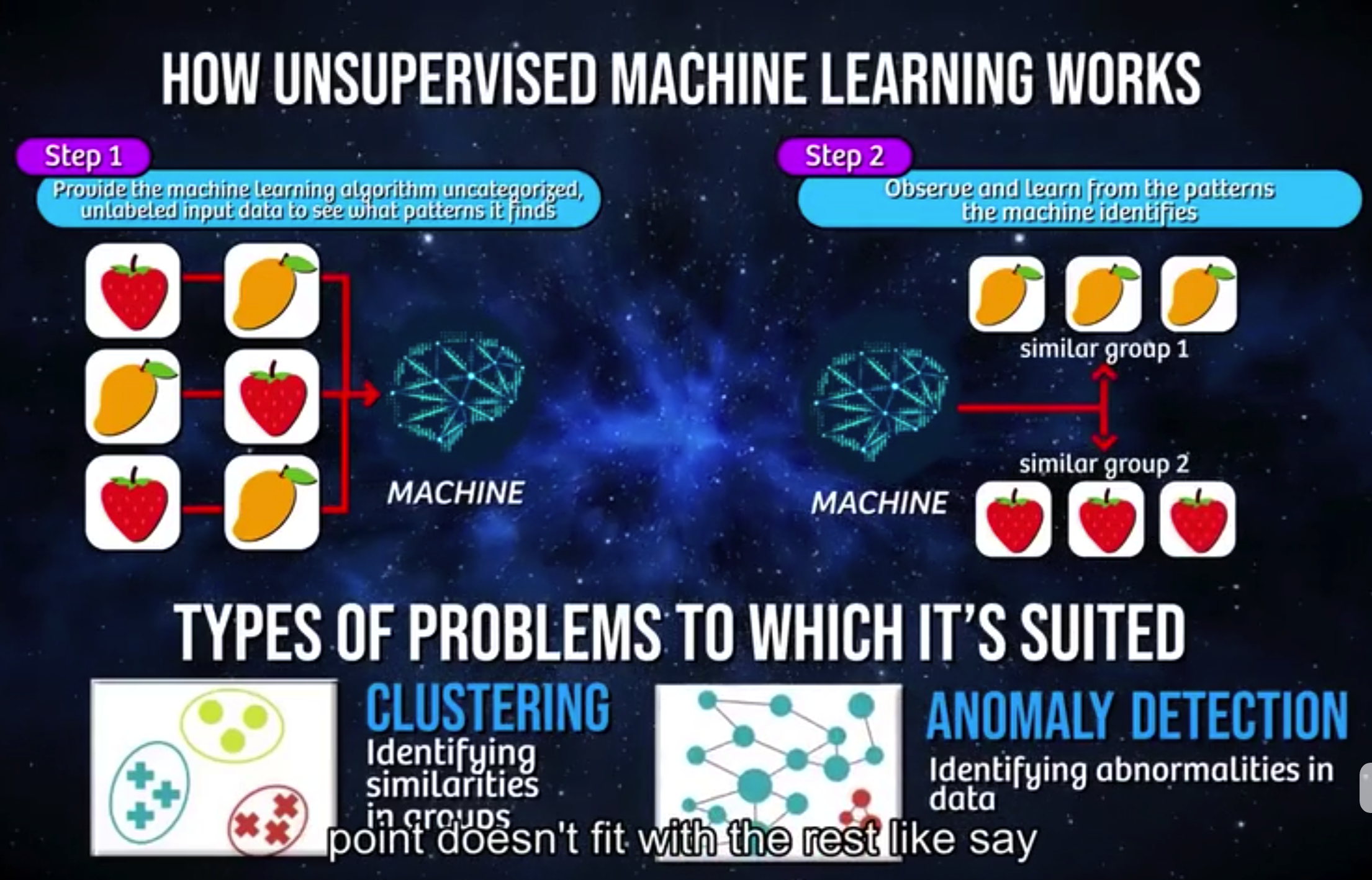
同样分为两步,区别在于,这里输入的数据是未分类过的(也未打标签)。机器学习算法需要自己完成分类的工作,并从中找出数据中的模式(往往是我们无法解释和说明的)。非监督学习通常可以用于聚类——识别各个类别之下数据的相似性并由此分类,也可以用于异常识别——例如排除数据集中的异常值(视频中的例子是欺诈性交易)。

这里,一句话总结:监督学习适用于事后对数据阐释性分析和对未来的预测,非监督学习则更适合发现数据的内在规律和结构。
然而,实际情况中的影响因素往往更复杂,要解决的问题也往往不止是确定既有的固定关系。有时,需要我们在没有训练数据的情况根据实际情况去不断优化策略(有点类似于我们人类的熟能生巧)。因此,这里引进了另一个概念:“强化学习”。
强化学习 (Reinforcement Learning)
这里以选择最优运输路线为例。

可知影响运输结果的因素有很多,包括天气、道路拥堵、交通工具、食品保存等等。同时,我们也没有先验数据来训练算法和检验算法的优越性。那么这里的强化学习算法,就引入了一个新的维度:时间,来帮助我们在实际情况中通过不断迭代来优化算法。
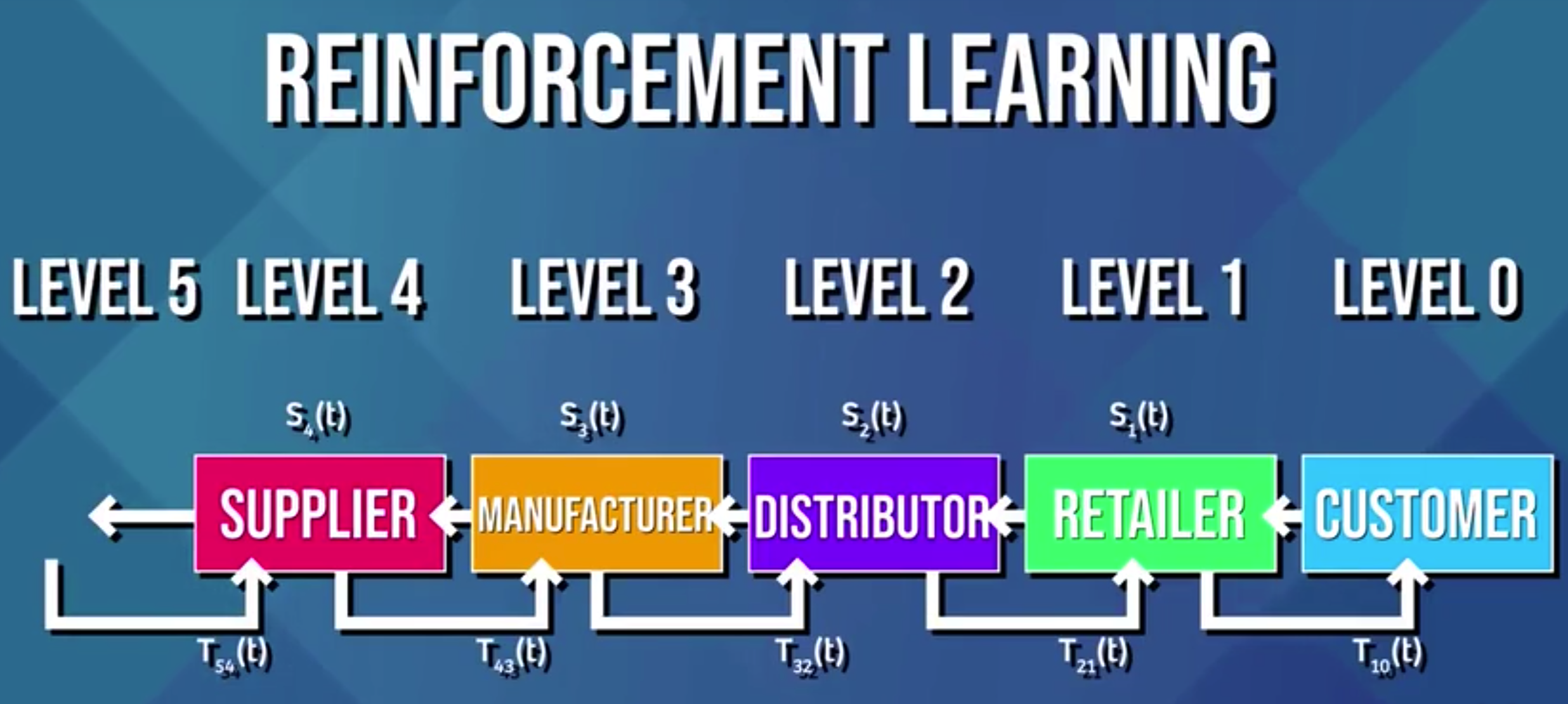
强化学习算法可以说是介于监督算法和非监督算法之间。它既不像非监督算法一样完全不使用标签,也不像监督算法一样预先打好标签,这里的标签是延时(delayed)打上的。就像图中所标出的那样,每个环节的标签T(也可以称为反馈)由下一个环节来标记。
我个人的理解是,所谓的强化学习算法的核心,就是一个环环相扣的负反馈系统。学过生物的同学大概能理解的意思,生物内部环境的稳态就是通过负反馈机制来实现的。
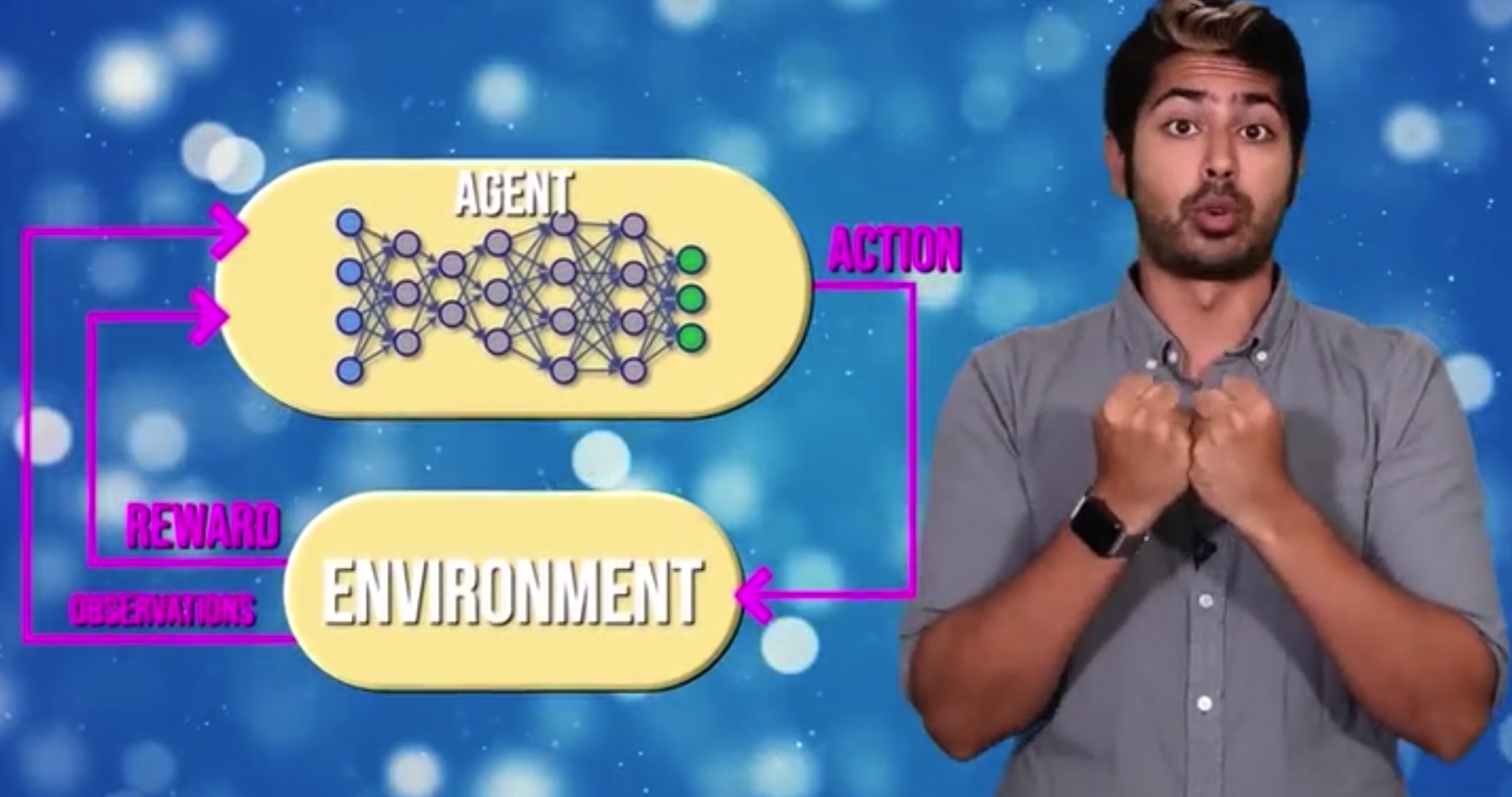
而当模式识别网络(神经网络)和基于强化学习框架的实时环境结合在一起,就是所谓深度强化学习。我的理解是,和非监督学习算法类似,前者相当于Step1的模式识别部分,而后者相当于Step2——不断提供反馈来优化算法。
至于这一算法有多牛逼嘛,看阿尔法狗就知道了。
-----------------------------------------------------
介绍完这些基本概念后,下面就进入正题了。有一些数学知识必须了解。
马尔科夫链 (Markov Chain)
对于强化学习来说,马尔科夫链是个很重要的概念。正是基于这个概念,才发展出算法和外界之间沟通和反馈的方式。
马尔科夫链究竟是什么呢?简单来说,就是用来描述一连串相互关联的事件(状态)的一种抽象模型。其中每个事件(状态)已经发生的前提下,接着会发生哪个事件(切换到哪个状态)的概率分布是已知的。

好吧,如果概率统计里没学过这一课的同学,估计此时已经百分百晕了。拿现实中的例子来举例,就比方说,天气预报吧。首先我们假定只有两种天气:晴天和雨天,并且前一天下雨后第二天放晴的概率是0.2,继续下雨的概率是0.8;前一天晴天第二天下雨的概率是0.4,继续放晴是0.6。那么,根据今天的天气,我们是不是能把未来七天每天放晴和下雨的概率都算出来了?OK,这未来七天的天气状态,就是一条简单的马尔科夫链。
必须注意两点,一、我们计算出来的只是概率分布,依旧无法确定给出每天的天气;二、每天的天气概率情况只取决于前一天的天气。
现在可以结合一下视频里的示意图来看了,这里的转移矩阵(Transition Matrix)给出了状态间互相转移的概率分布,右下角则展示了每多走一步后我们来到A、B、C三个节点的可能性。
马尔科夫决策过程(Markov Decision Process)
马尔科夫决策过程是马尔科夫链的扩展,在原基础上加入了行动(Action)和奖励/反馈(Reward)。相应的转移矩阵也产生了变化,下一个状态的概率分布 不仅取决于上一个状态还取决于采取的行动。而从环境得到的反馈则告诉我们这一步到底是好(正向反馈)还是坏(负向反馈)——所谓趋利避害,下次就可以避免在同一状态下采取同样的行动。那么最终在不断最大化奖励的过程中,我们就获取了最优策略。
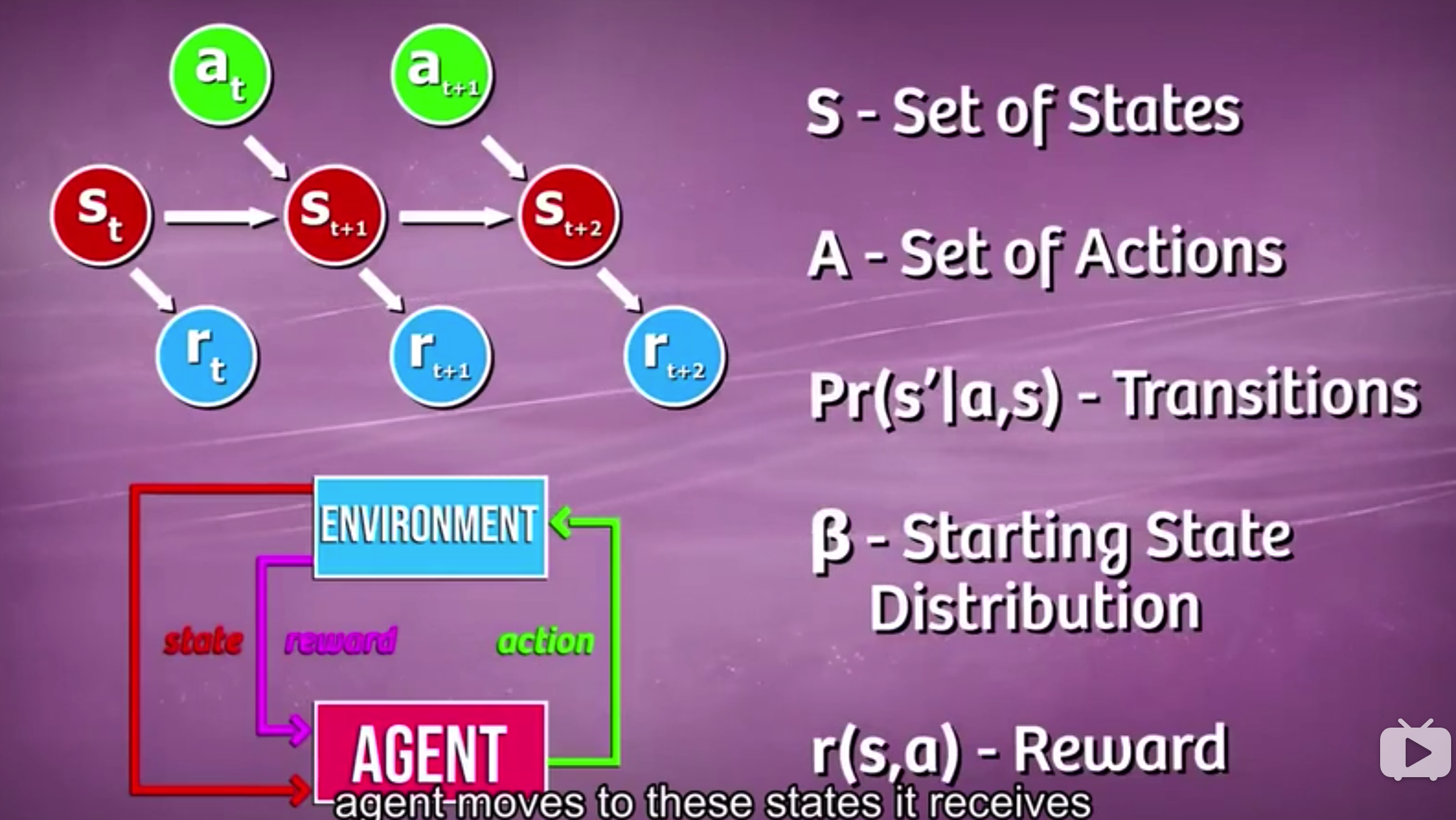
OK,以上就是导论课的所有内容。
有理解不当或阐述的错误的地方,还望大牛们不吝指正。
感谢阅读~