【强化学习】强化学习介绍
1.定义
强化学习(reinforcement learning),又称再励学习、评价学习,是一种重要的机器学习方法,在智能控制机器人及分析预测等领域有许多应用。但在传统的机器学习分类中没有提到过强化学习,而在连接主义学习中,把学习算法分为三种类型,即非监督学习(unsupervised learning)、监督学习(supervised leaning)和强化学习。
强化学习主要包含四个元素:智能体(Agent)、环境状态(environment)、奖励(reward)、动作(action)。
举个例子作为一个决策者(agent)你有两个动作(action)学习、打游戏,你去打游戏学习成绩就会下降,学习成绩就是你的(state)你的父母看到你学习成绩会对你相应的奖励和惩罚(reward)所以经过一定次数的迭代你就会知道什么样的成绩下选择什么样的动作会能够得到最高的奖励的,这就是强化学习的主要思想
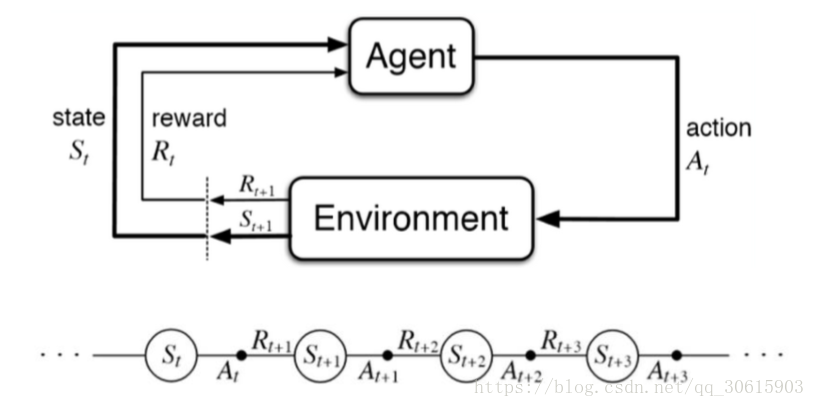
2.强化学习算法分类
在模型已知的MDP情况下,已知MDP的状态转移概率和回报函数的动态规划方法有四种:
- 线性规划方法 利用线性规划求解值函数
- Policy Iteration 策略迭代的方式,求解最优策略。
- Value Iteration 值迭代为了得到各个状态下采取什么动作能够的得到最大奖励。
- 广义策略迭代方法 关注点是每一步的最优行动。
3.强化学习主要算法
Q_Learning
强化学习值迭代主要算法,主要通过环境获得当前环境s_t下选取对应动作a获取的r,然后将其构建成一张Q表

Sarsa
Sarsa的计算Q(s1, a2) 现实的时候, 是去掉maxQ的,遵循说道做到原则, 取而代之的是在 s2 上我们实实在在选取的 a2 的 Q 值. 最后像 Q learning 一样, 求出现实和估计的差距 并更新 Q 表里的 Q(s1, a2).

Deep Q Network(DQN)
因为DQN采用了神经网络来计算Qvalue所以就可以替换掉Qlearning中的Q-table,根据状态s和动作a直接来计算相应Q值,然后进行值迭代。DQN 在玩游戏上应用广泛适用于状态空间和动作空间过大的场景

Policy Grandient
policy grandient与以往的算法不同,它并非通过计算Q(s,a)值来选择动作,而是直接输出行为,他的好处是可以在一个连续的区间内挑选动作,普通的Qlearning在无穷多动作下计算值是困难的

Actor Critic
Actor-Critic 的 Actor 是由 Policy Gradients演变而来, 他能在连续动作中选取合适的动作, 而 Q-learning 做这件事会瘫痪.又因为Actor Critic 是根据Q-learning 或者其他的 以值为基础的学习法来的 , 能进行单步更新, 而传统的 Policy Gradients 则是回合更新, 这降低了学习效率.
Critic被用来学习奖惩机制,就是环境和奖励之间的联系,所以可以对actor的动作进行反馈,使得Actor每一步都在更新。同时还可以衍生出可以分布式运行的A3C

Deep Deterministic Policy Gradient (DDPG)
将DQN 网络加入进 Actor Critic 系统中, 这种新算法叫做 Deep Deterministic Policy Gradient, 成功的解决的在连续动作预测上的学不到东西问题,DDPG分为两个部分策略 Policy 的神经网络 和基于 价值 Value 的神经网络, 但是为了体现 DQN 的思想, 每种神经网络我们都需要再细分为两个动作估计值网络,和状态估计值网络

这些算法主要来源于morvan老师的教学视频和DeepMind的公开课,算法详细内容与公式推导见接下来的详细讲解