前言
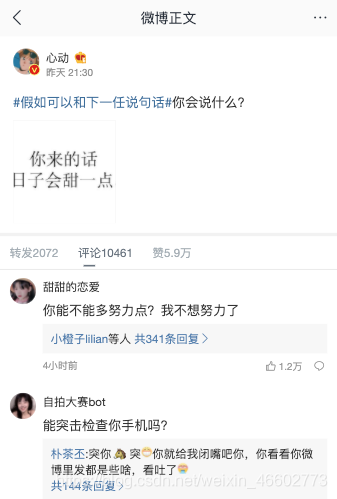
#假如可以和下一任说句话#
今天在午休逛微博看到这个话题很感谢趣,但是午休时间短,上班又没得办法看,怎么办?
想了一下还得Python出马,抓取下来存成TXT,下班路上慢慢看!不多说开始盘它。
开始
用Charles抓包工具分别获取了手机客户端,网页,手机版网页的api,,发现用https://m.weibo.cn手机网页版的页面比较好抓。
1.打开话题页面链接https://m.weibo.cn/detail/4497711464486426很容易就看到了API接口
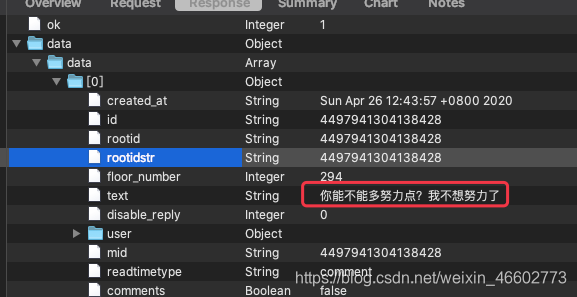
先记录一下链接:
https://m.weibo.cn/comments/hotflow?id=4497711464486426&mid=4497711464486426&max_id_type=0
页面往下翻了一下发现必须登录,否则只能获取前10多条,先登录一下。
登录成功后看到有一个接口https://m.weibo.cn/api/config频繁调用,看了一下发现,
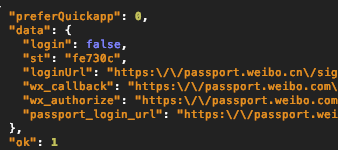
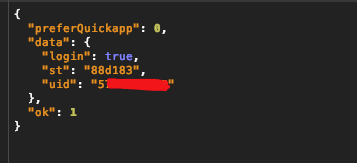
UID这个感觉是用户的唯一ID,先记录一下。
登录后页面就往下滚动了,滚动几次接口调用如下:
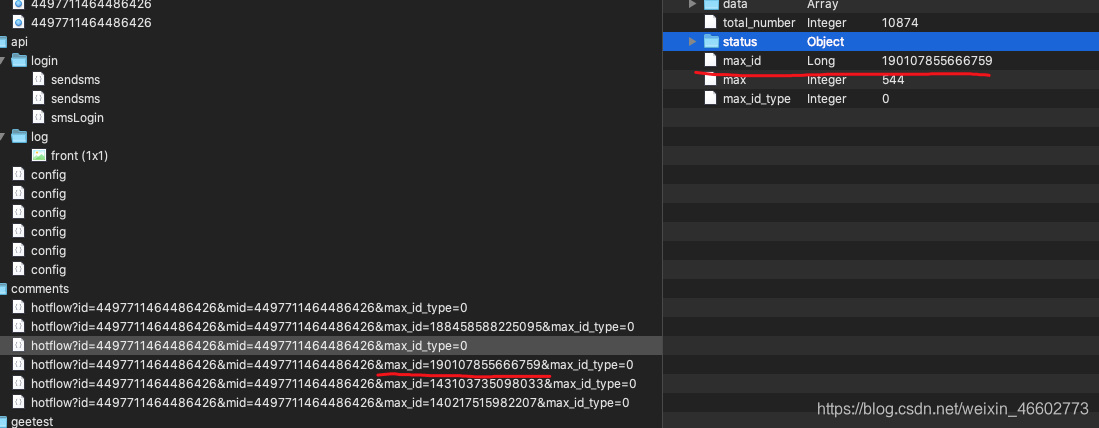
发现很有规律,下一组数据的请求就是加上max_id ,max_id是上一组数据中返回的。
继续对比几次请求的请求头,发现登录前后的cookie 变化:
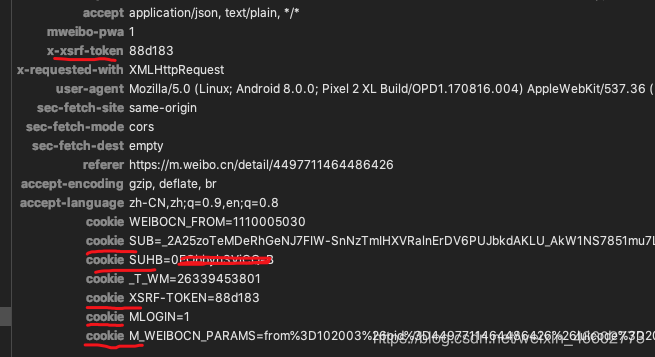
其中 x-xsrf-token:c8519b 正是前边config接口返回的st参数。
ojbk,接下来该python出马了。
import requests
import re
import ssl
import time
def fuckWeiBo(weibo_id, url, headers, number, name):
ssl._create_default_https_context = ssl._create_unverified_context
# 先获取授权码
session = requests.session()
web_data = session.get("https://m.weibo.cn/api/config", headers=headers) #F12查看data信息
js_con = web_data.json()
# 设置Header
headers["x-xsrf-token"] = js_con['data']['st']
#申明一个用于存储手动cookies的字典
#将CookieJar转为字典:
res_cookies_dic = requests.utils.dict_from_cookiejar(web_data.cookies)
#将新的cookies信息更新到手动cookies字典
res_cookies_dic["MLOGIN"] = '1'
res_cookies_dic["SUB"] = '自己抓啊自己抓'
res_cookies_dic["SUHB"] = '自己抓啊自己抓'
res_cookies_dic["SCF"] = '自己抓啊自己抓'
res_cookies_dic["XSRF-TOKEN"] = js_con['data']['st']
res_cookies_dic["M_WEIBOCN_PARAMS"] = '自己抓啊自己抓'
cookiesJar = requests.utils.cookiejar_from_dict(res_cookies_dic, cookiejar=None,overwrite=True)
session.cookies = cookiesJar
baseURL = url
count = 0 #设置一个初始变量count为0来进行计数
max_id = ""
max_id_type = "0"
with open(name + ".txt", "a", encoding="utf8") as f:
while count < number:
# 不要抓太快
time.sleep(1)
try:
url = ''
# 第一组评论不需要加max_id
if count == 0:
url = baseURL + weibo_id + '&mid=' + weibo_id + '&max_id_type=' + str(max_id_type)
else:
url = baseURL + weibo_id + '&mid=' + weibo_id + '&max_id=' + str(max_id) + '&max_id_type=' + str(max_id_type)
web_data = session.get(url, headers=headers)
js_con = web_data.json()
# 获取连接下一页评论的max_id
max_id = js_con['data']['max_id']
max_id_type = js_con['data']['max_id_type']
comments = js_con['data']['data']
for comment in comments:
comment = comment["text"]
label = re.compile(r'</?\w[^>]*>', re.S) #删除表情符号
comment = re.sub(label, '', comment) #获得评论
f.write(comment + '\n')
f.write('\n')
count += 1 #count = count + 1
print("已获取" + str(count) + "条评论!")
except Exception as e:
print("出错了", e)
continue
if __name__ == "__main__":
headers = {
'User-Agent': 'Mozilla/5.0 (Linux; Android 8.0.0; Pixel 2 XL Build/OPD1.170816.004) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.122 Mobile Safari/537.36',
"x-log-uid": '自己抓啊自己抓',
}
url = 'https://m.weibo.cn/comments/hotflow?id='
name = "假如可以和下一任说句话"
weibo_id = '4497711464486426' # 要爬取的微博id
number = 10000 # 设置爬取评论量
fuckWeiBo(weibo_id, url, headers, number, name)
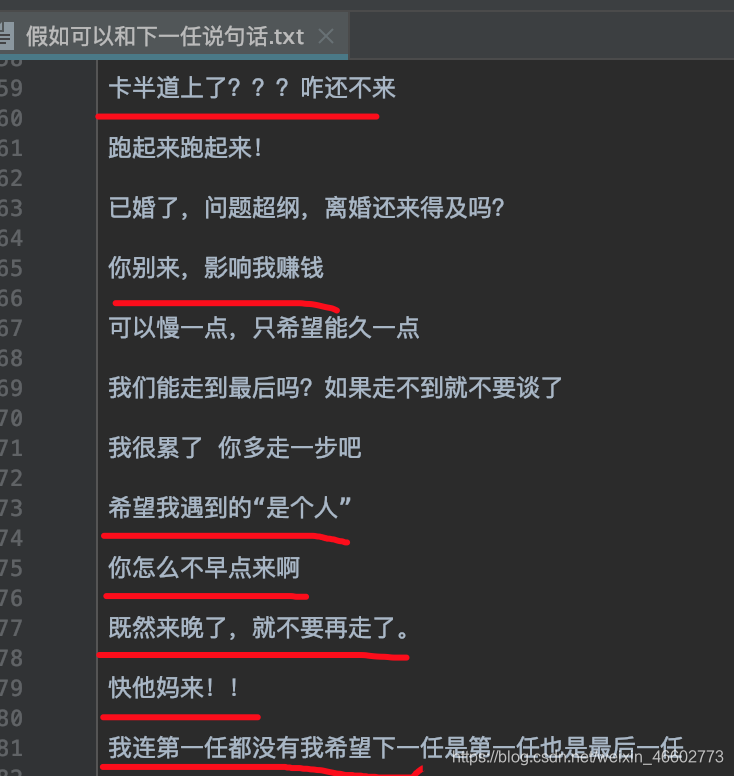
结论:大部分评论都是单身狗!单身狗!!单身狗!!!
