Direct I/O 操作(二)
【上回书说到,LSU的CC位能够表示正在进行的传输的状态。】
中断和LSU释放
LSU的CC位能够表示正在进行的传输的状态,自然也能显示出执行过程中的错误,而且一点出错,与这些错误有关的中断将迅速被上报给CPU。在上报处理阶段不会提交新的任务。
错误上报给CPU后,LSU只有在以下几种情况下才会被释放:
- CPU对restart或者flush位进行写入
- 如果对于未提交给CPU的transaction的所有响应都已经被接收,或者在接收响应时发生了超时。一旦发送响应超时,就不会有额外的中断或者CC位置位,来处理这次响应超时。如果接收到了所有响应,LSU就会只清除当前运行的transaction,并载入正在等待的一套寄存器。如果CPU写入了flush位,并且收到了所有响应,CPU将会清除掉影存器中的所有transaction,这里的影存器是特定LSU的影存器,这里的transaction是有特定SRCID_MAP 的transaction。如果restart和flush的命令都没有收到,但是收到了所有响应,外设将会一直等待直到收到CPU的restart或者flush超时信号。LSU将会抛弃所有transaction,包括当前拥有同一SRCID_MAP 的transaction导致的错误。在这之后,LSU会自动装载下一组数据。如果这部分看不懂的话,后面还会有对错误处理的进一步解释。
有8个寄存器集,这允许对所有需要响应的transaction类型提供8个突出请求。对于多核设备来说,软件对这些寄存器进行管理,通过共享配置总线VBUSP来管理这些寄存器。单核设备能利用全部8个LSU块。
Figure2-11显示了一个NWRITE_R类型的transaction,图中包括该transaction的数据流和域映射。
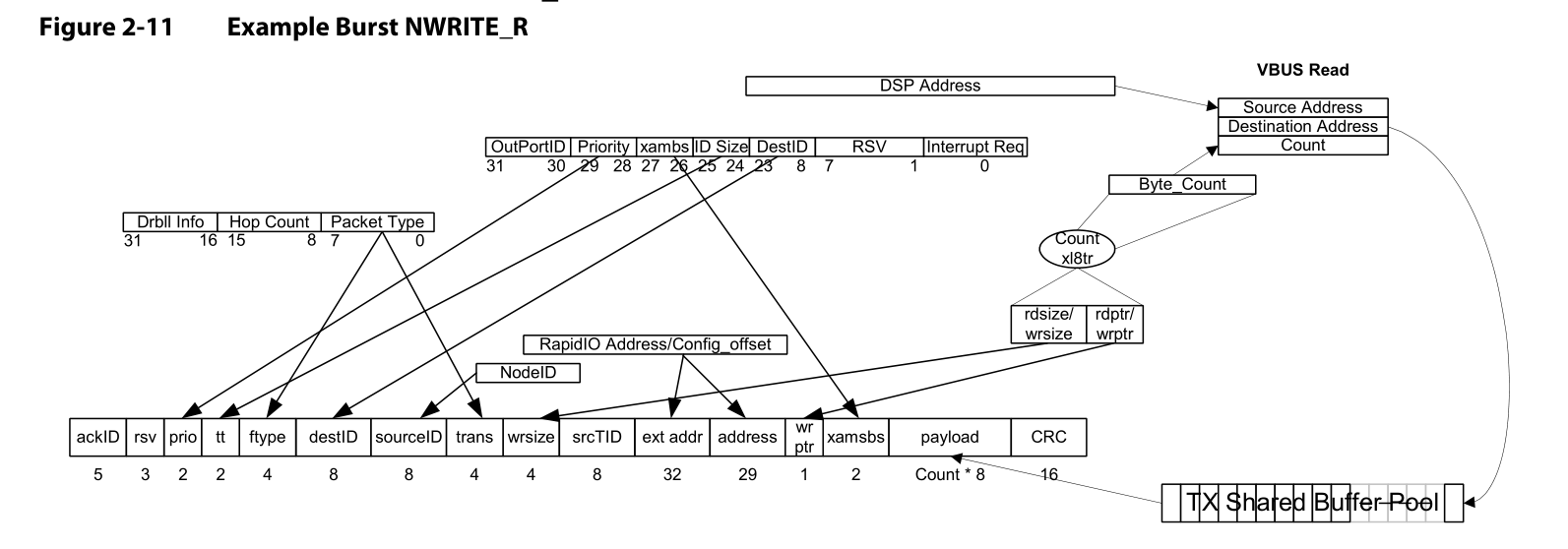
“写”类型的命令,它的payload(负载消息内容的一个指针)与来自控制/命令寄存器的header信息相结合,然后导入到TX SharedBuffer-Pool,即图中右下角所示。最终payload被传递到TX的FIFO队列中进行传输。
“读”类型的命令没有payload,所以就只有控制/命令寄存器的域被缓存,然后使用它来创建一个RapidIO NREAD 包,进而传递到TX FIFO队列进行传输。从接收接口传递相应的响应包时,READ响应包的payload在RX资源池中被缓存。提交和未提交给CPU的操作都基于OutPortID命令寄存器,这样设计是为了确定合适的输出口或者确定合适的输出队列。
数据以DMA时钟频率,向Load/Store模块发送。
具体数据路径描述
上面说的高大上的一堆话,总结一下Load/Store模块的作用就是产生directIO包。
这种接口不支持消息传递接口。插一句嘴,外向传送的DOORBELL(门铃)包也是通过这个接口产生的。每个LSU最多能支持16个SRCIDs,所以LSU0能够用SRCID0-15产生传输,LSU1能用SRCID16-31产生传输等等。每次LSU发出一个新的命令,就重新计算SRCID的数量,所以每次发出新的命令的时候,LSU1的SRCID总是从16开始的。
该模块的数据路径是以VBUSM总线作为DMA接口的。SRIO的payload最大值是256B,每个LSU都有可能产生多于一个VBUSM传输,为的是并行得到超过256B的payload。这些payload之后可以用UDI接口发送,当然为了区分这些传输,就要利用不同的SRCID,即使是发送给同一个LSU的,当响应包从UDI接口返回的时候还是能够分辨不同的transaction。
Figure2-12显示了发送数据的端口操作流程图。
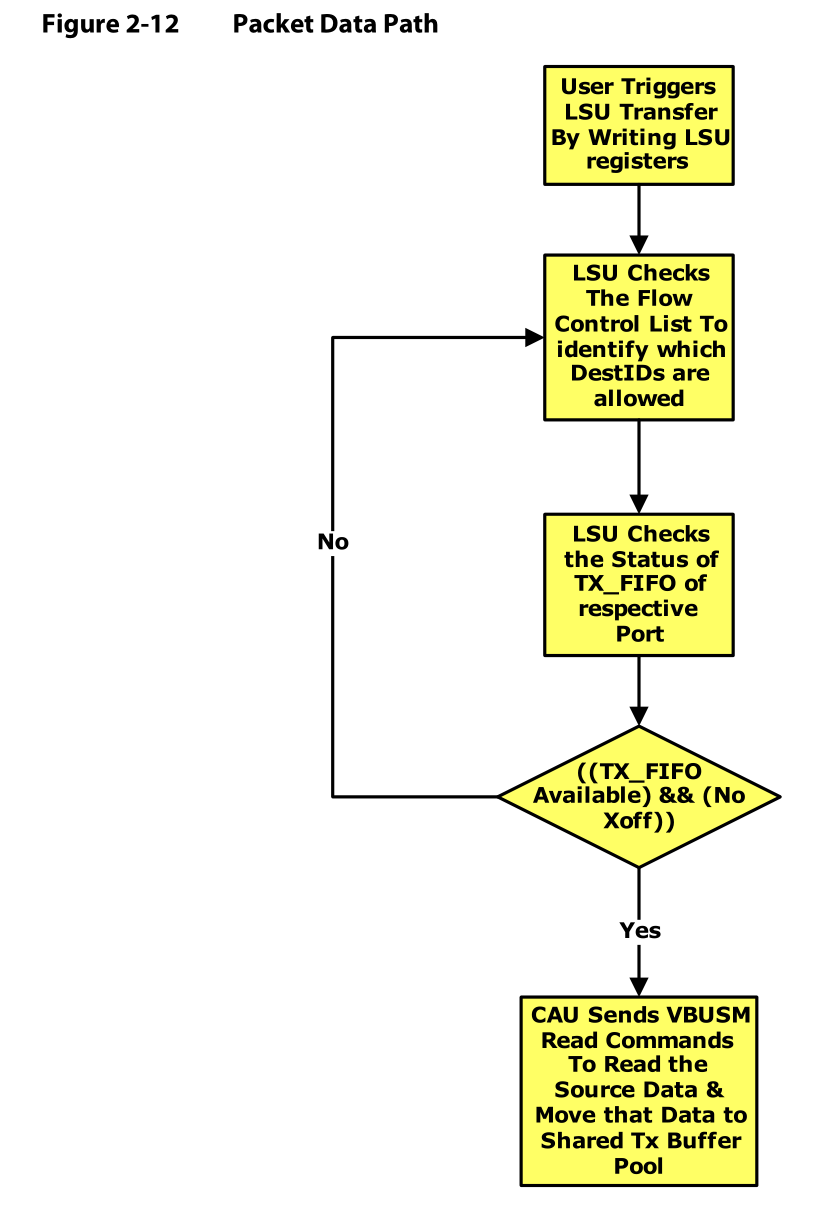
- 用户通过配置LSU寄存器出发LSU传输
- LSU检查流控列表来确定哪个DestID是可以用的
- LSU检查每一个port的TX_FIFO状态
- 如果TX_FIFO可用并且没有正在进行的传输,CAU就发送VBUSM Read Commands来读取来源信息,并且将来源信息移动到共享TX Buffer池;如果TX_FIFO可用和没有正在进行的传输,这两个条件有一个不存在,就回到检查流控列表确定DestID可用那一步。
CPU利用VBUSP配置总线和控制/命令寄存器。这些寄存器包含传输描述符,这些传输描述符需要初始化读/写包的产生。在传输描述符被初始化写好之后,就要确认流控状态。确认流控状态的模块检测命令寄存器的DESTID和PRIORITY域来确定流通道是否已经被占用,还有,TX FIFO的空闲状态也要被检查,该操作是通过检查命令寄存器的OutPortID实现的。只有在流控通道被打开,TX FIFO被分配缓存之后,才会产生一个VBUSM读命令,该读命令作用于将被移入到TXbuffer池的payload数据。数据以简单的顺序从共享buffer池移动到合适的输出TX FIFO,这种顺序基于VBUSM传输的completion情况。只要数据被传输到FIFO中,数据就一定能通过管脚发送。
Figure2-13显示了支持Load/store模块所需的数据路径和缓存。
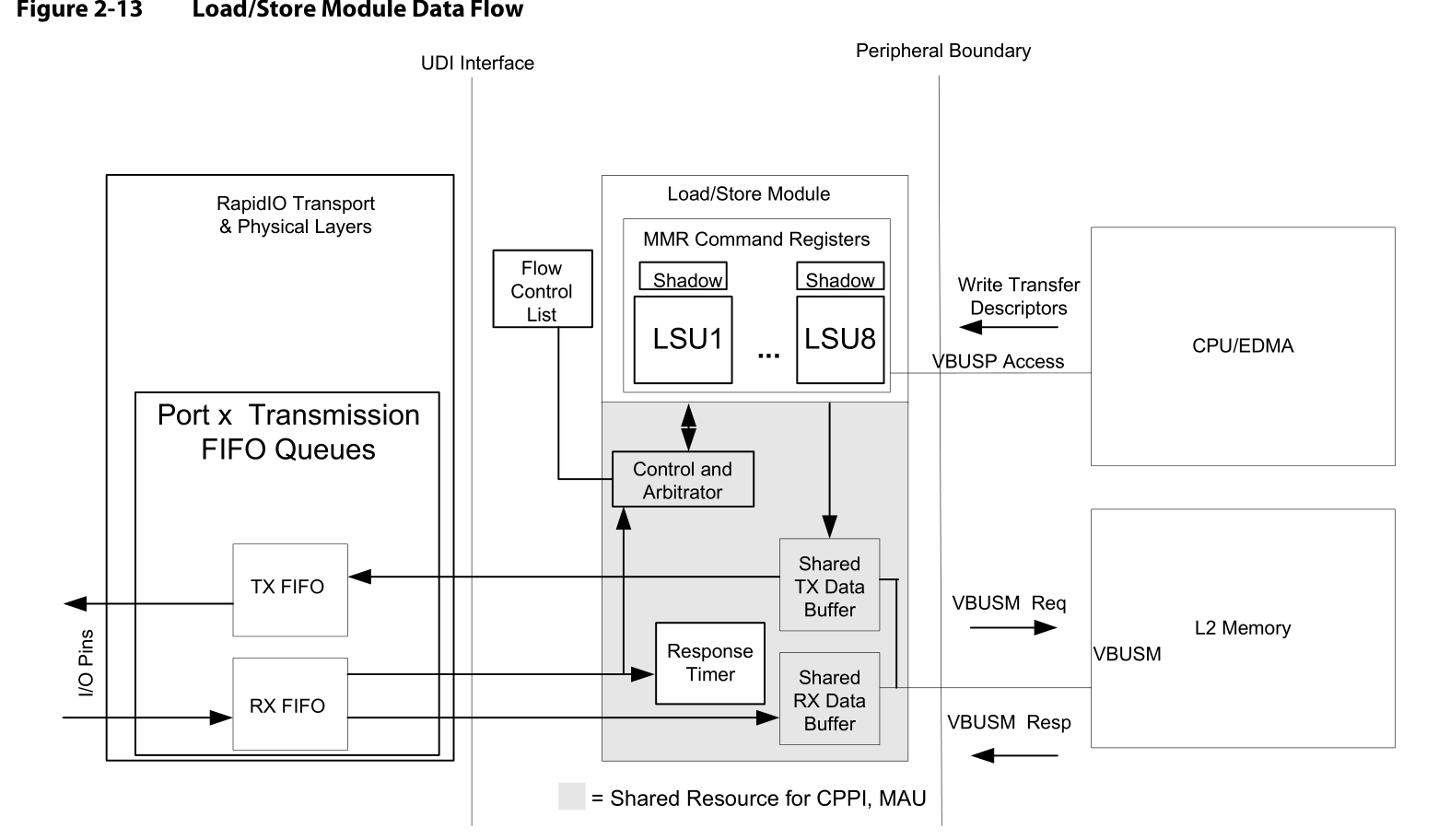
TX操作
写传输
Figure2-14显示了SRIO内部的缓存机制。
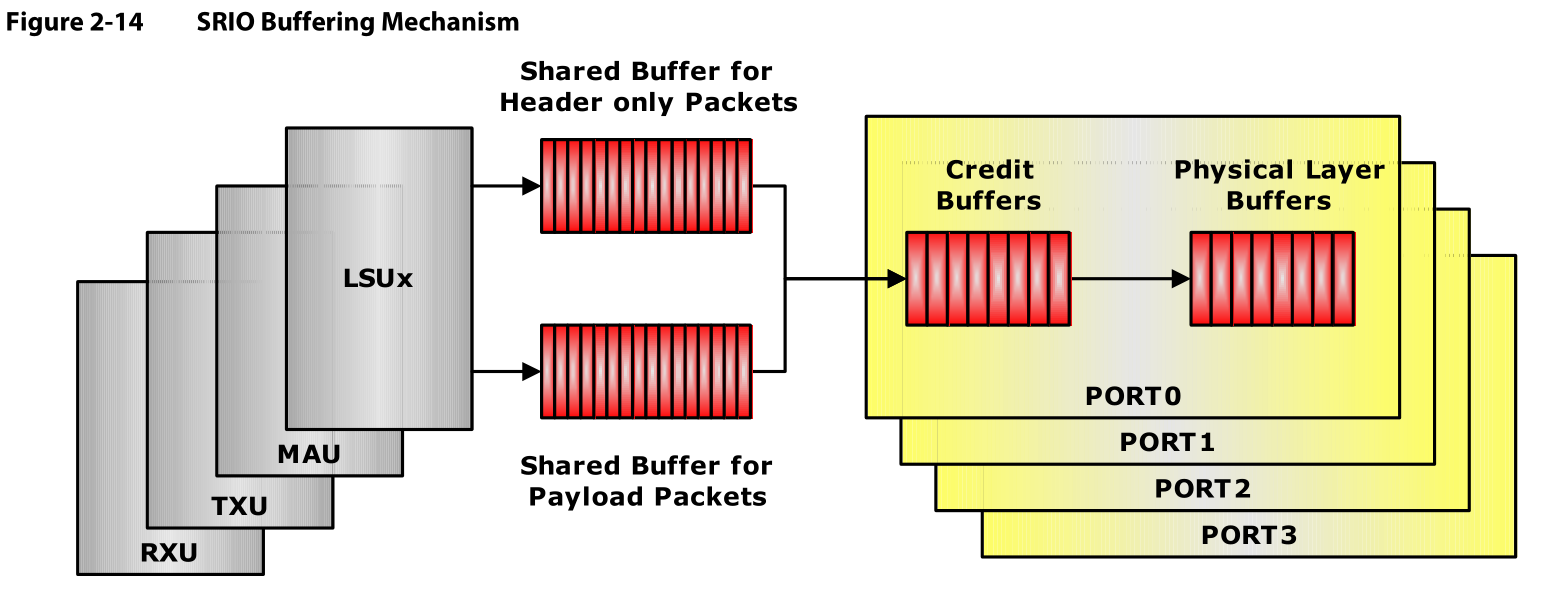
多核之间共用Shared TX Data Buffer。一个状态机在LSU和其他协议单元之间进行仲裁和分配可用的buffer。只有在来自VBUSM的payload的最后一个字节被写入Shared TX Data buffer之后,Load/Store模块才会把包送到TX FIFO,一旦包被送到TX FIFO,共享缓存就可以释放,并且用于其他transaction了。
TX缓冲区在所有输出源之间动态共享,这些输出源包括LSU,TX CPPI,来自RX CPPI和MAU的响应包。所以缓存空间存储需要分段对带payload的包和不带payload的包进行处理。
一条消息最多有16个包,每个包的最大尺寸是256B,同时还可以有不带payload只含header的包。数据以接收的顺序离开共享缓存,离开时不需要确认包的优先级,但是数据离开TX FIFO时需要考虑到优先级。
对于提交的WRITE操作不需要RapidIO响应包,一个核有可能提交各种各样的输出请求。例如,一个单一的核可能在任何给定的时间内让流写数据包进行缓存,并且提供了输出源。在这个例子中,一旦数据包写入共享TX缓存池,LSU就会释放给影存器。如果请求被流控,外设将设置completion code status register并且使用中断位ICSR。当中断路由完成的时候,控制/命令寄存器就会被释放。
对于未提交的WRITE操作需要RapidIO响应包,任何给定的时间里每个核只能有一个向外的请求。消息包会写入TX缓存池,当然,一直到响应包路由到原来的模块,并且状态寄存器中恰当的completion code被设置之后,LSU才可以释放。在原子输出测试和交换包中有一种特殊情况,这种包是唯一 一种需要有带有payload的响应的Write类型的包,这种响应的payload被路由到LSU,然后payload被检查以确认信号是否被收到,随后对completion code进行适当的设置。payload并没有通过VBUSM传出外设。
所以一般的流程是:
- 通过VBUSP(配置总线)配置控制寄存器
- 流控确认
- TX FIFO(TX共享缓存池)可用确认
- VBUSM读取对数据payload的请求
- VBSUM在共享TX缓存区域响应给特定模块缓存的写数据
- VBSUM读响应被监控,等待payload的最后一位
- 命令寄存器的header数据写入共享TX缓存空间
- 将payload和header传递给TX FIFO
- 如果不需要RapidIO响应,载入下一个影存器
- 基于优先级从TX FIFO传递数据给外部
读传输
产生读传输的流程和产生带有响应的未提交的WRITE传输相似。不过还是有两个主要的不同,首先,READ包包含不带数据的payload;其次,READ响应是带payload的。所以读命令只需要TX缓存池中的一块无负载缓存,当然,还需要一块共享RX缓存,这块缓存不是在READ包传输开始之前就分配好的,因为这会造成其它输入包去其它模块的交通阻塞。
重复一遍,一直到响应包路由到原来的模块,并且状态寄存器中恰当的completion code被设置之后,LSU才可以释放。
因此一般的流程是这样的:
- 通过配置总线VBUSP配置命令寄存器
- 流控确认
- 分配TX FIFO缓存
- 命令寄存器中的header数据写入到共享TXbuffer
- 传递header数据给TX FIFO
- 基于优先级从TX FIFO相外部传递数据
- 当数据返回UDI接口时,通过VBUSM总线将数据发送出去
对于所有的传输,共享TX缓存都会在包被推送到TX FIFO之后就立即释放,如果接收到了一个未提交传输(non-posted transaction)的ERROR或者RESPONSE信号,CPU必须重新配置REG6或者重新开始这个传输。
包分段
LSU对向外的请求有两种分段方法。一种是请求的Byte_Count超过256B,另一种是请求的RapidIO地址是非64位的。这两种情况下,向外的请求都要被分解成多个RapidIO请求包。例如,CPU相对外部的RapidIO设备进行1KB的存储操作,配置好LSU寄存器之后,CPU对REG5命令寄存器进行了一个简单的写入操作,然后外设硬件将存储操作分为4个RapidIO写包,每个都是256B大,然后计算每个包的64位RapidIO地址,WRSIZE和 WDPTR。在所有提交包传递给TX FIFO之后,释放LSU。对于未提交操作,像CPU载入,在LSU释放之前,必须受到所有的包响应。
RX操作
响应包的类型一直是RapidIO包类型13。所有带有传输类型的响应包不等于0b0001,并且不超过128个SRCTID以接收顺序路由给LSU。这些包是否带有payload取决于相应的请求包。由于RapidIO交换系统的性质,响应包可以以任何顺序到达。数据payload(如果有的话)和数据header是从RX FIFO移动到共享RX缓存中去。包的TargetID域用以确定等待响应的核和相应的寄存器。记住,每个核只能有一个外向请求。通过VBUSM总线操作,所有的payload数据从共享RX缓存池移动到存储区域。
MAU管的是所有进来的DirectIO包,包括 NREAD,SWRITE, NWRITE 和 NWRITE_R 传输。不支持进来的原子操作,如果进来会以ERROR的形式响应。对于DirectIO包,MAU负责路由DOORBELL消息给中断处理器,MAU也负责包的前向传输。
所有进来的DirectIO包包含一个存储地址域,该地址是设备的存储映射,决定数据将会写在哪里或者从哪里读取数据。不支持通过外设翻译RX地址。RapidIO包的地址将被应用于DMA传输。这种方式需要DirectIO传输知道目标设备的映射地址信息。当然,我们必须知道对目标地址的覆盖写,是没有一种硬件保护机制的。这种保护必须在系统级的软件层面进行管理。一些存储访问可能在设备级层面被限制到监督协议中,即设备自身带有监督协议,来管理存储访问。大多数存储访问通过用户允许就能使用。MAU给每一个接收到的DMA传递来的包配置用户许可证,除非包的SOURCEID和RIO_SUPRVSR_ID的值相匹配。如果匹配RIO_SUPRVSR_ID的值,就会被颁发监督许可证。
复位和掉电
通过reset,Load/Store模块将所有寄存器的域置为默认状态的值,等待CPU的处理。
如果DirectIO协议在应用中不被支持,那么Load/Store模块就可以掉电。例如,如果使用Message协议进行传输,那么就可以对Load/Store模块进行掉电操作,以达到省电的目的,在这种情况下命令寄存器应该掉电并设置为不能访问。在掉电状态下,这些模块的时钟就要被gate掉。
特殊情况
对于这些特殊情况,大家在遇到时再去查手册即可,不必了解过深,此处只写出目录,以保证在出错时能够按图索骥。
时间用尽
输入错误响应
软件处理基于LSU错误的SRCID中断
门铃的输入重试响应
时序
对于 传输来说,任何时候LSU都能准备就绪。在传输确定时序之前,下面的情况要被提供。
优先级,CRF:只有最高等级的优先级和CRF的传输才会为每个port考虑时序
流控:transaction的DESTID不应该被流控
未提交传输的SRCID:如果这个SRCID正在被一个未提交传输使用,而新的为提交传输来自同一个SRCID,那么新的传输就会被挂起,直到旧的传输完成
SRIO VBUSM总线限制:VBUSM接口最多支持4个写和4个读传输同时进行,VBUSM被MAU、LSU和TXU共享,如果LSU想在VBUSM接口发送一个命令,那么VBUSM接口应该处于空闲状态。
FIFO : FIFO中应该有足够的空间容纳一次传输
如果多个LSU达到了以上条件,scheduler将以环形签字方式决定谁先谁后。
错误处理
不同的错误都会发生,表现为RIO_LSU_STAT_REGx的CC位所报告的不同的值。还有,如果Int_req和Sup_gcomp(只影响良好的完成中断)位无效,位在LSU_REG4中被置位,中断就会路由回CPU或者DMA。为每个特定的SRCID在REG3中产生信息,在8个LSU中都是这样的情况。在这些设备中错误信息只在每个LSU上可用。当然如果不同的核在使用LSU,LSU就会中断所有的核,即使这个完成情况只是针对于某个单一的核。因此,区分每个核的LSU中断非常重要,因为EDMA专用于LSU,所以每个核都有自己的信息也很重要。RIO_LSU_SETUP_REG1寄存器是用来确定是否LSU在被EDMA使用。只有在LSU没有在工作时,该寄存器才是可以编辑的。
Figure2-15是RIO_LSU_SETUP_REG1寄存器的图,Table2-14是RIO_LSU_SETUP_REG1寄存器的功能描述。

可以看到RIO_LSU_SETUP_REG1有两种域,一种是LSUx_edma,当LSUx_edma位是0的时候,表示好的完成(good completion)将基于SRCID被驱动给中断;当LSUx_edma位是1的时候,表示好的情况中断将被驱动给LSU的特定位。
另一种域是 Timeout_cnt,如果该域是00,表示在一次错误情况之后,在该传输被丢弃和新的传输开始之前,时间码只变了一次;如果该域是01,表示在一次错误情况之后,在该传输被丢弃和新的传输开始之前,时间码只变了两次,以此类推。
对于每一个传输下面的中断都会产生。软件决定使用这些中断中的哪个并且看情况路由到其它地方:
- 基于table2-14中的setup位的,每个LSU或者SRCID的好的完成
-在LSU_REG4中定义的每个SRCID的错误完成
如果发生LSU没有自动装载下一个影存器中的内容,那么它就需要软件的介入。当CPU得到一个中断, 它就会读取相关的RIO_LSU_STAT_REGx位,了解error的细节。目前软件可以做到如下情况:
软件可以选择不理这个中断
在这种情况下,有一个时钟将会失效。LSU将会抛弃所有的传输,包括当前来自同一个SRCID的传输。然后LSU会自动装载下一组影存器中的内容,如果LSU是为一个EDMA配置的,LSU还会发送一个完成中断给EDMA,这会使能EDMA自动的装载下一组寄存器。
软件修复这个问题(例如使能为XOffed的port),并且将相关的LSU的restart位置1 ,LSU将会中断当前传输并装载下一组影存器。
软件决定清除当前传输
在这种情况下,软件将LSU的flush位置1,所有来自同一个SRCID的传输包括当前还在影存器中的传输都会被清除。这会花费超过一个时钟周期来完成清除工作。
在以上的几种情况下,LSU_REG6的flush位和restart位都是写模式。
DirectIO编程注意事项
下面的代码段中显示了LSU的编辑细节,这里用的是CSL 寄存器层的API来演示读和写操作。
/*******************************************************************************************************************************/
/***** 步骤1:锁定LSU ************************************************************************************************/
/*******************************************************************************************************************************/
/* 同时检测FULL位和BUSY位,确定影存器是否空闲和未锁定*/
value = CSL_FEXTR(SRIO_REGS->LSU[Lsuno].LSU_REG6, 31, 30);
while (value != 0)
{
value = CSL_FEXTR(SRIO_REGS->LSU[Lsuno].LSU_REG6, 31, 30);
}
/***** 存储LTID域,以得到LSU影存器号码*****/
LTID = CSL_FEXT(SRIO_REGS->LSU[Lsuno].LSU_REG6, SRIO_LSU_REG6_LTID);
/***** 存储LCB位来确认完成码的有效性*****/
LCB = CSL_FEXT(SRIO_REGS->LSU[Lsuno].LSU_REG6, SRIO_LSU_REG6_LCB);
/*******************************************************************************************************************************/
/***** 当前LSU被锁定,所有核都会看到BUSY位是1***********/
/*******************************************************************************************************************************/
/*******************************************************************************************************************************/
/***** 步骤2:配置LSUx_REG 0 – 4 ********************************************************************************/
/*******************************************************************************************************************************/
/***** 为目标DSP缓存编辑地址*****/
SRIO_REGS->LSU[Lsuno].LSU_REG0 = CSL_FMK( SRIO_LSU_REG0_ADDRESS_MSB,0 );
SRIO_REGS->LSU[Lsuno].LSU_REG1 = CSL_FMK( SRIO_LSU_REG1_ADDRESS_LSB_CONFIG_OFFSET,(int )&rcvBuff[0] );
/***** 为源DSP缓存编辑地址*****/
SRIO_REGS->LSU[Lsuno].LSU_REG2 = CSL_FMK( SRIO_LSU_REG2_DSP_ADDRESS, (int )&xmtBuff[0]);
/***** 编辑payload大小并且在编程实现完成之后不会响铃*****/
SRIO_REGS->LSU[Lsuno].LSU_REG3 = CSL_FMK( SRIO_LSU_REG3_BYTE_COUNT,byte_count )|
CSL_FMK( SRIO_LSU_REG3_DRBLL_VAL, 0);
/***** 从Port0发送数据,只在错误情况下产生中断 *****/
SRIO_REGS->LSU[Lsuno].LSU_REG4 = CSL_FMK( SRIO_LSU_REG4_OUTPORTID,0 )|
CSL_FMK( SRIO_LSU_REG4_PRIORITY,0 )|
CSL_FMK( SRIO_LSU_REG4_XAMBS,0 )|
CSL_FMK( SRIO_LSU_REG4_ID_SIZE,1 )|
CSL_FMK( SRIO_LSU_REG4_DESTID,0xBEEF )|
CSL_FMK( SRIO_LSU_REG4__REQ,1 )|
CSL_FMK( SRIO_LSU_REG4_SUP_GINT, 1)|
CSL_FMK( SRIO_LSU_REG4_SRCID_MAP, 0);
/*******************************************************************************************************************************/
/*****步骤3:开始传输****************************************************************************/
/*******************************************************************************************************************************/
SRIO_REGS->LSU[Lsuno].LSU_REG5 = CSL_FMK( SRIO_LSU_REG5_DRBLL_INFO,0x0000 )|
CSL_FMK( SRIO_LSU_REG5_HOP_COUNT,0x00 )|
CSL_FMK( SRIO_LSU_REG5_PACKET_TYPE,type );在步骤3之后,如果确定不会有其它核使用这个LSU,就没必要为下一次LSU操作检查BUSY位,只需要检查FULL位并且锁定LSU,为下一组影存器的写入做好准备。
参考文献
PS:欢迎大家与我讨论文章中的问题,包括反对我的观点。