具体过程可参考 https://blog.csdn.net/wy250229163/article/details/52729608
和http://wuchong.me/blog/2015/04/04/spark-on-yarn-cluster-deploy/
此处我只写自己遇到的坑,遇到同样问题的同学可以参考一下。
1:如何在虚拟机上搭建一个分布式的网络,也就是如何构建虚机的网络。
虚机间的网络我选择的不是桥接而是自定义(特定虚拟网络)
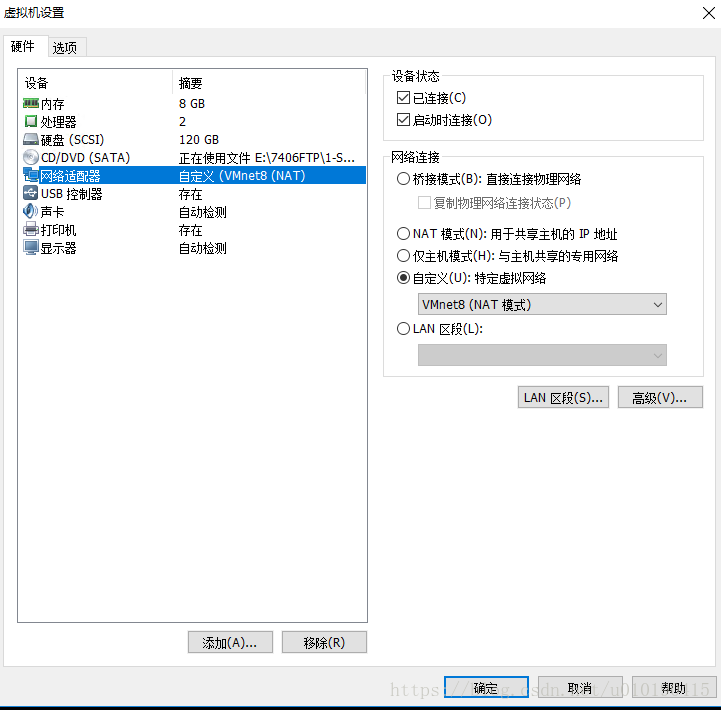
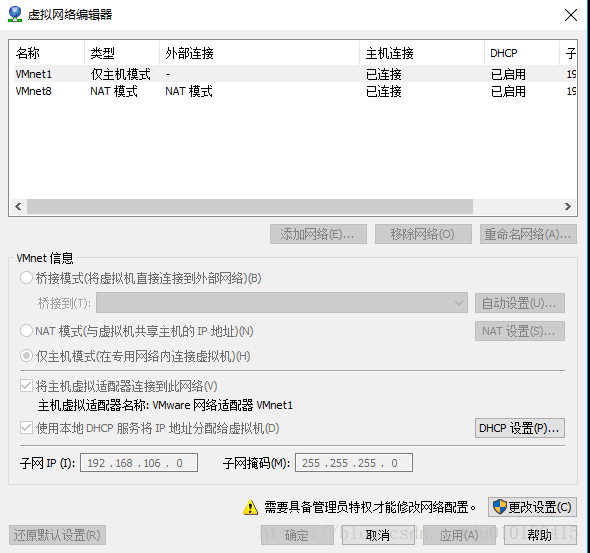
更改VMnet8的TCP/IPv4中的IP地址和子网掩码以及默认网关(网关一般最后是以 .2 结尾),将所有虚机的网络适配器都设置为自定义选中其中的VMnet8就行了,这样就将所有虚机设置在同一个网络中了,断开虚机的网络,重连一下就会得到新的IP地址。具体如何设置master和slave1与slave2等请参考上面两个博客。
2 Hadoop 配置过程中一个小坑,请多加注意。
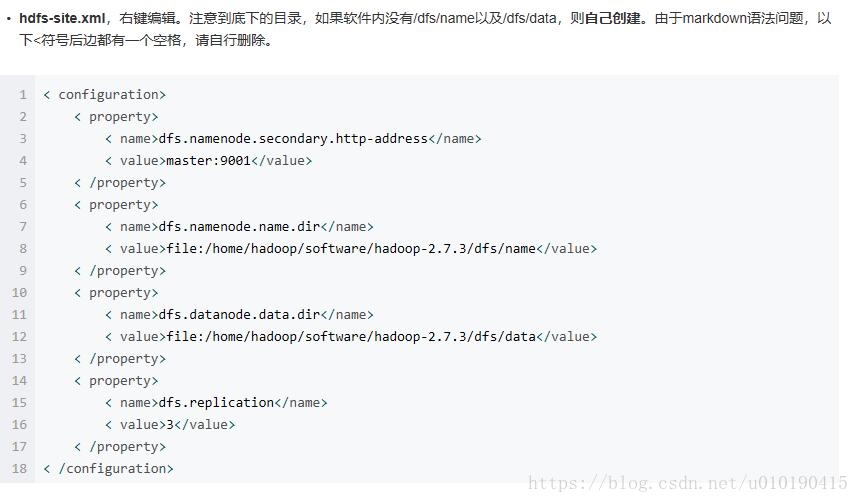
其中在配置hdfs-site.xml与core-site.xml 需要新建两个目录tmp和dfs/data,dfs/name(这个是文件夹,我当初傻啦吧唧的设置成文档,真怀疑自己脑子是不是有坑),还有一点就是在下面的文件配置中有这样两个语句:< value>file:/home/hadoop/software/hadoop-2.7.3/tmp
</value>、 < value>file:/home/hadoop/software/hadoop-2.7.3/dfs/name</value> 、< value>file:/home/hadoop/software/hadoop-2.7.3/dfs/data</value> 请注意!!!请这样理解:<value>file:/home/电脑用户名(例如我的是 qds)/后面的就是根据自己电脑路径设置。一定要切记这个hadoop是博主电脑的用户名,不要被误导了,是在不确定可以在配置完成之后,鼠标移到这个路径上,按住ctrl+左键一下,如果显示没有该路径说明你设置的有问题,如果跳转到你指定的文件夹说明成功了。否则在验证hadoop启动时你会发现节点都是unhealthy的!请一定要留意路径是否设置正确,是否路径中忘记添加电脑用户名!!!