版权声明:本文为博主原创文章,转载请注明出处。 https://blog.csdn.net/mao_xiao_feng/article/details/73718388
ok,最后一篇我们来讲如何对某一个具体的数据集来做可视化分析。
现在我们要引入一个以matplotlib作为基础的更高级的api:Seaborn,Seaborn有什么用?简单地说,就是用更少的语句,画出更好看的图。
Seaborn的下载:
sudo pip install seaborn首先用一个例子介绍seaborn的简单用法:
import matplotlib.pyplot as plt
%matplotlib inline
import numpy as np
import pandas as pd
import seaborn as sns
sns.set()
data = np.random.multivariate_normal([0, 0], [[5, 2], [2, 2]], size=2000)
print data.shape
data = pd.DataFrame(data, columns=['x', 'y'])
for col in 'xy':
plt.hist(data[col], normed=True, alpha=0.5)用sns.set语句做一个初始化,接下来就可以用plt的函数来绘制seaborn美化过后的图了,这里用numpy生成二维的正态分布,然后转换成pandas的序列格式(其实这里我试过不转也可以,因为本来就可以接受np格式的参数)
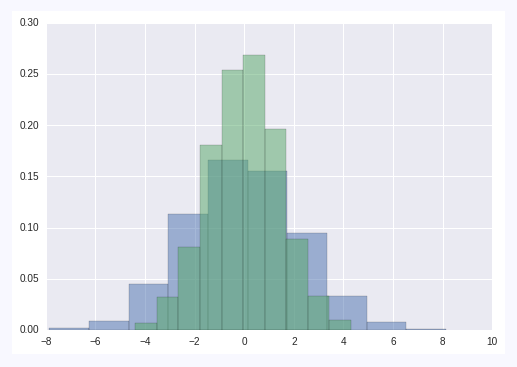
for col in 'xy':
sns.kdeplot(data[col], shade=True)还可以采用KDE绘图的方法转换成连续的函数,调用方式是sns.kdeplot

另外使用sns.distplot可以把离散绘图和KDE绘图结合起来,放在一个图表里面,更加直观。
sns.distplot(data['x'])
sns.distplot(data['y'])对二维数据,我们也可以作处理:
sns.jointplot("x", "y", data, kind='kde')得到一个直观图,这里我们会发现,它在绘制联合分布的同时还绘制了边缘分布,非常形象。
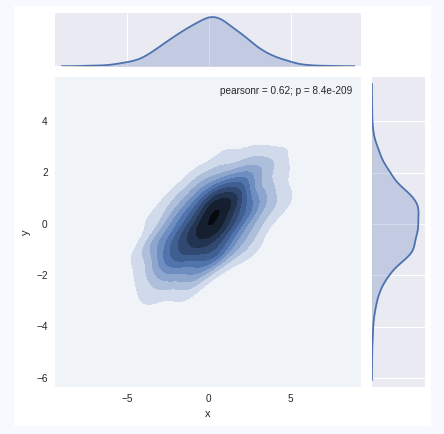
具体数据集的多元分析
接下来我们上具体的数据集吧。前面说过的iris数据集是一个很适合来做可视化例子的数据集,因为它不大,操作起来很简便,同时它也是多维数据,怎么处理多维数据呢?先导入iris,seaborn里面已经自带了这个数据集,我们将它导入进来:
iris = sns.load_dataset("iris")
iris.head()这里返回的iris是pandas的Dataframe格式,使用head函数,是输出这个数据的前五行,如下
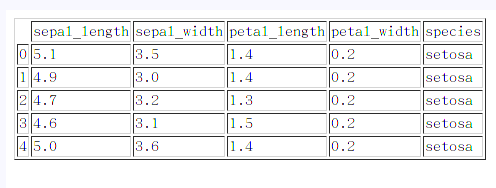
这个数据集的最后一列是label,前四行是属性,然后用pairplot来绘图:
sns.pairplot(iris, hue='species', size=2.5)这里hue是指我们的标签,画图的时候会以的不同得颜色来区分,pairplot还有很多的参数,不一一介绍了,产生的图是这样的:
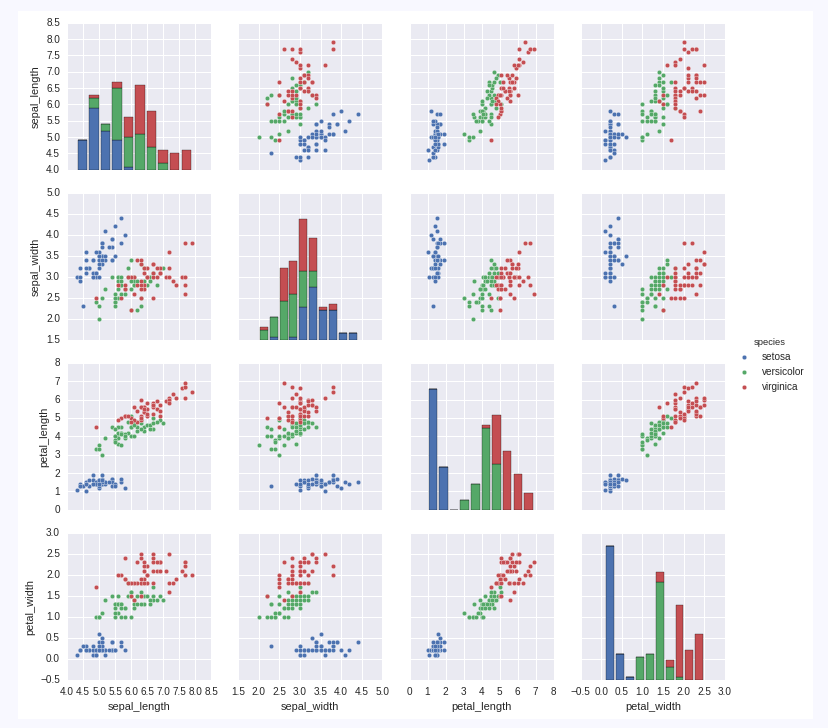
从这张图我们就可以很直观的看出各个变量之间的关系,甚至从petal_length和petal_width我们就可以把其中一类分出来。