延续上一篇内容,《数学之美》这本书我想吴军博士的初衷是非科班也能读懂,书中对数学知识的解释极为详细,所以我只将书中的核心思想抽取出来,方便今后很容易Get到点,有些篇章为介绍性文字,我也把重要的鸡汤拿出来喝一喝,为了将篇幅控制在可读范围内,每篇包含7个模块内容。
1.查询和网页的相关性
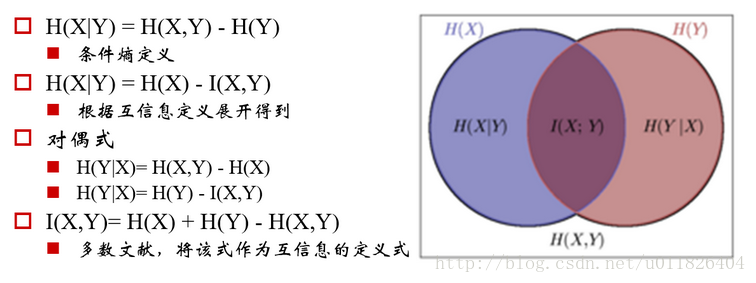
上篇中已经提到,网页的排名一般取决于两个因素:网页的质量与网页的相关性,PageRank就是衡量网页的质量一种经典方法,这里我们将介绍另一个关键技术:如何度量查询和网页的相关性。
首先人容易想到:出现搜索关键字次数多的网页相关性应该高,但这时篇幅短的网页就不干了,因此需要根据网页的长度对关键词次数进行归一化,这里就引出了之前常见的“单文本频率”(Term Frequency,简称TF),即除以网页的总字数。一般查询的关键词不止一个,最简单的是使用所有查询关键词的TF直接相加得到相关性,但这时又会出现问题,这些关键词的权重不应该一样,例如有些介词等TF大但对于相关性没有任何作用,因此应该将一些无关紧要的词权值设置为0,同时一个词的预测能力越强,赋予的权重应该越大,例如搜索:学生和敖威,显然自己名字的预测能力强,因为出现敖威两个字的网页很少(还是自己太菜…),一下子就能找到想要的网页。因此定义:
单文本频率(TF):网页中关键词出现的次数 / 网页的总字数。
逆文本频率指数(IDF): 若关键词w在Dw个网页中出现过,Dw越小,其权值应该越大, IDF=log2(D / Dw)(D表示全部网页数)。
这样所有查询关键词和网页相关性的计算公式就不是简单的相加,而是加权求和:
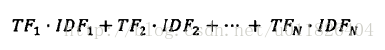
这就是声名远扬的TF-IDF计算公式,TF-IDF的概念被公认为信息检索中最重要的发明,有了这个我们就很容易度量关键词和网页的相关性。
2.Google AK-47
1.许多失败并不是因为人不优秀,而是做事的方法不对,一开始追求大而全的解决方案,之后长时间不能完成,最后不了了之。
2.改进方法都要能说清楚理由。
3.余弦定理与新闻分类
说起余弦定理与新闻分类,就想起了当初大一时的一位小伙伴拿着这个去糊弄APP创意大赛的评审,还忽悠到了一个三等奖。回到正题,新闻的自动分类是各大新闻网站的关键技术,即将互联网上发布的各种新闻按类别聚合在一起,这时需要计算两篇新闻之间的相似性。
词是传播新闻的载体,同一类新闻的用词都是相似的,如果使用一个词库,那一篇新闻则可以变成一个特征向量(包含为1,不包含为0),例如新闻只有两个词“数学 美丽”,则其对应的特征向量为…0 0 0 1 0 0 0 1 0 0 0…(特征向量长度为词库的大小),但并不是所有词的重要程度都一样,这时候我们前面定义的TF-IDF就派上用场了,现在我们并不是简单地用0和1来表示一个词,而是用计算词的TF-IDF值。


这时一篇新闻就成为了一个向量,向量中的每个数值代表它所对应的词对这篇新闻主题的贡献程度,两篇新闻主题是否接近,取决于这两个特征向量是否长的像,而计算向量之间的距离,余弦定理千呼万唤始出来~
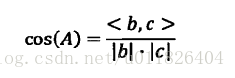
有了两篇新闻之间相似性的度量方法,再回到新闻分类上,若现在我们已经有了各种类别新闻的特征向量模板,则对于一条新闻,只需看它与哪个模板的余弦距离最小归类即可。若事先没有各种类别的标准模板,则可以计算所有待分类新闻两两之间的余弦值,将其中与每个新闻余弦距离最近的新闻合并为一个小类,再计算小类新的特征向量,一直向上迭代合并,设置一个到合适的余弦距离阈值停止迭代。
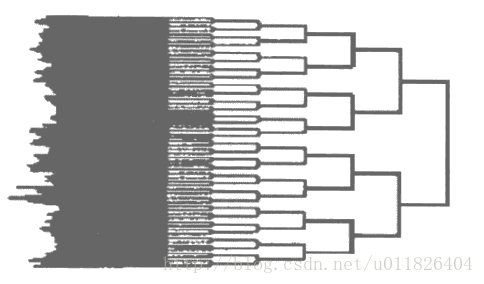
事实上,当我们将新闻数值化以后,新闻的分类就变成了聚类任务,有特征向量模板的分类实质上就是聚类中心不变的K-Means,而不断向上迭代合并实质上就是层次聚类法的思想。
4.两个分类问题与奇异值分解
主成分分析(PCA)和矩阵的奇异值分解(SVD)可以说是矩阵论的经典应用,之前花了几个日夜才弄出点头绪。由上面我们知道:一篇文档可以表示成一个特征向量,如果有词库大小为M,N篇文档,则可以表示成一个词项-文档矩阵(M*N)。

矩阵的奇异值分解将原矩阵分解为三个矩阵的乘积:
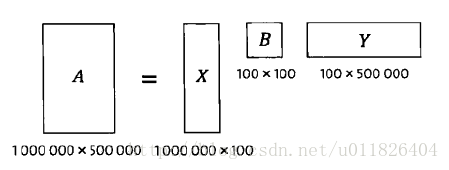
简单来理解,SVD就是在两个维度上的PCA,X矩阵是关于词的主成分,将词项进行合并压缩;Y矩阵是关于文档的主成分,将文档进行合并压缩。合并压缩可以理解为将一些相似的合并在一起,冗余和无关紧要的去掉。这样X矩阵就是对词义分类的结果,Y矩阵就是对文档分类的结果,一次奇异值分解就可以同时完成近义词分类和文档的分类,另外还可以得到每个主题类和每个词义类的相关性。
(吴军老师这里可能是写反了,看到网上书友同样的困惑才敢这样说,毕竟高下立判~.~orz)
5.信息指纹及其应用
正如人有其独特的指纹一样,一段信息也应该有它的“指纹”作为它的唯一识别。在网络爬虫中,我们要将下载过的URL使用散列表记录下来,这时问题来了,若直接将URL以字符串(整数)的形式储存,既浪费储存空间,又耗费大量的查找时间,但若将URL转化为一个随机数,这时效率将大大提升,这个随机数就称为信息指纹。产生信息指纹的关键算法称为伪随机数产生算法,它可以将任意长的整数转换成特定长度的伪随机数。
信息指纹的一个特征是不可逆性,无法根据信息指纹推出原有信息,就比如:信息指纹可以判断两个URL是否相同,但是无法复原URL信息。常用的算法有MD5或SHA-1标准,生活中最常见的应用便是登录密码,出于安全性服务器数据库中储存的都是加过密的密码,当你输入登录密码后,它会再将这个密码加密一次,然后再比对与原有的加密密码是否相同,这样即便非大神级黑客攻击了数据库,也无法对密码复原。
由于信息指纹的独特性,它可以很容易运用到相似性判定中,例如判断两个集合是否相同,只需将各个集合中元素的信息指纹相加,若两个集合的信息指纹和相等,则两个集合等价。YouTube的反盗版则是分别提取两段视频的关键帧,计算这些关键帧的信息指纹,变成判定两个集合是否相等的问题。
简单来理解信息指纹,就是将一段信息(文字、图片、视频、音频)随机地映射到一个二进制高维空间中的一个点上,其坐标便是一串二进制数字,只要处理得好,这串二进制数便成为了原来信息独一无二的信息指纹。
6.搜素引擎的反作弊
我们已经知道网页的排名取决于两个因素:网页的质量与网页的相关性,这时就会有人在专门在这上面做文章。早期最常见的作弊方法是重复关键词,由于IDF是一个固定值,TF随机关键词频次的增加不断增大,那如果将一个网页反复地刷关键词,这样网页的相关性就会大大提升。
有了网页排名(PageRank)之后,作弊者发现如果一个网页被其它网页链接的越多,则其质量越高,这样就有了专门卖链接的生意,比如建立成千上万的空壳子网站,上面只放客户网页的链接。搜索引擎反作弊的工作便是尽可能消除这些干扰,使得排名公正。
7.最大熵模型
对于一个随机变量X,当X满足均匀分布时,其信息熵最大。最大熵模型的原则是:1.承认已知事物(知识);2.对未知事物不做任何假设,没有任何偏见。 在这样情况下,概率分布最均匀,概率分布的信息熵最大,因此我们将其称为“最大熵模型”。
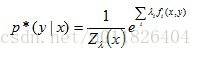
最大熵模型在形式上十分简单,但是在参数的训练上十分复杂,且涉及到诸多的数学知识,这里不能再深入了…
(具体可看July和邹博的东西)