这里用到的模块是request模块和beautifulsoup
首先我们需要打开Bilibili新番榜的审查元素
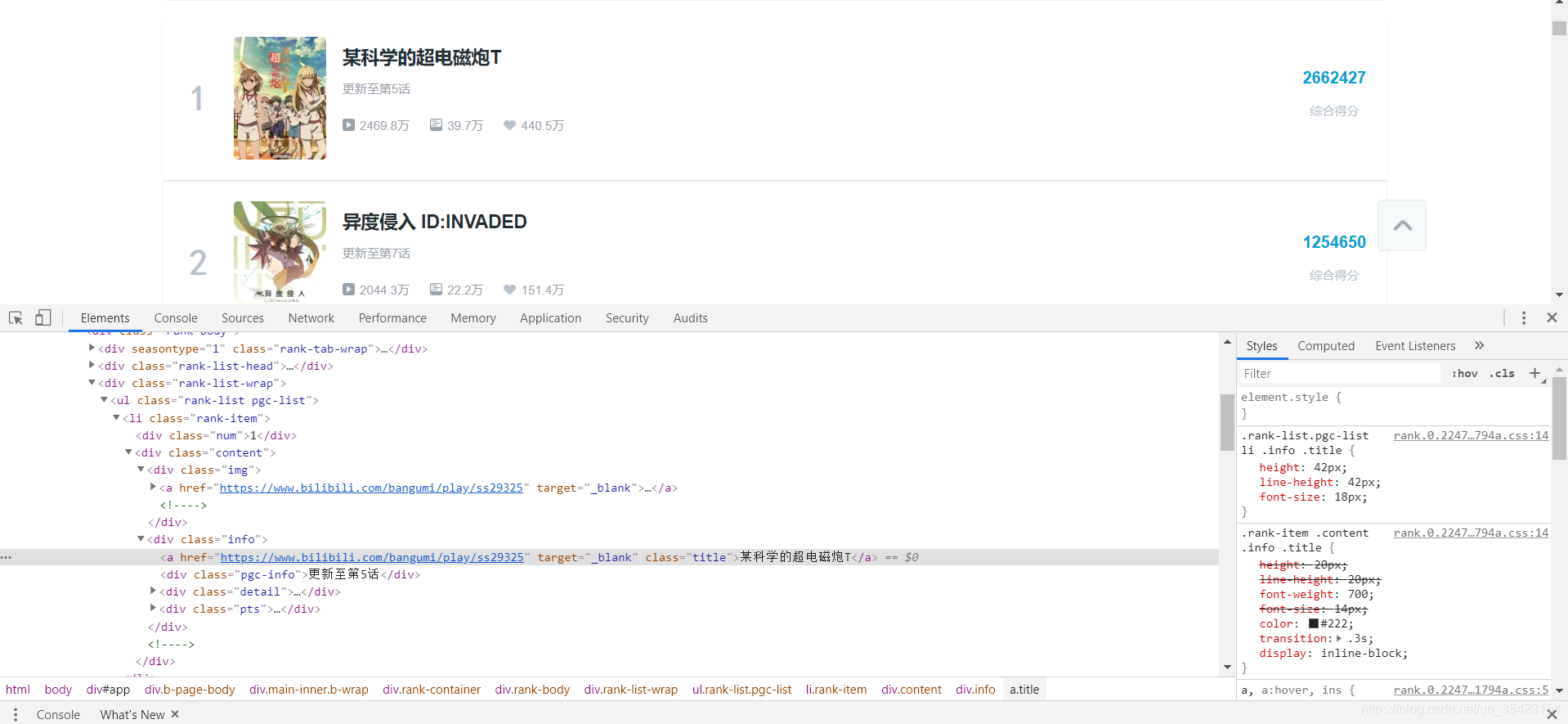
通过观察可以发现每一个动漫的信息都分别存在了li标签下的rank-item类中

而所有具体的信息都在里面的div标签下的info类中
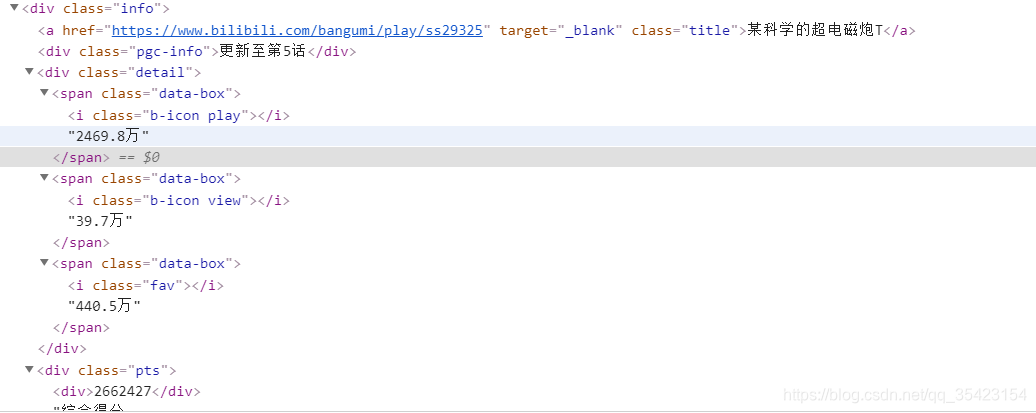
了解了所在位置就可以开始编写代码
首先设置代理及user-agent,然后下载页面上的内容,以text的格式返回
def get_html(url):
proxies = {"http": "36.25.243.51", "http": "39.137.95.70", "http": "59.56.28.199"}
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.130 Safari/537.36'}
response = requests.get(url, headers = headers, proxies = proxies)
return response.text
使用request模块大大简化了步骤,比起之前用的urllib简洁很多
之后我们需要用beautifulsoup4模块以html格式来对下载的数据进行解析,并用一个soup对象将他保存下来。然后再使用fand_all方法来找到所有li标签下的rank-item对象。然后再找到里面所有我们需要的内容,将他们全部加入到data列表中
def get_datas(text):
soup = bs4.BeautifulSoup(text, "html.parser")
data = []
animes = soup.find_all("li", class_= "rank-item")
for anime in animes :
title = anime.find('div','info').a.string
link = anime.find('div','info').a['href']
rank = anime.find('div','num').string
updata = anime.find('div', 'pgc-info').string
play = anime.find_all('span', class_='data-box')[0].text
view = anime.find_all('span', class_='data-box')[1].text
fav = anime.find_all('span', class_='data-box')[2].text
data.extend([rank, title, updata, play, view, fav, link])
return data
对于这个杂乱的数据,我们需要对这个列表进行分割,以七个元素为一组
def Slicing(iterable, n):
return zip(*[iter(iterable)] * n)
这个可能有点难理解,iter()是序列上的迭代器, n是每一组的长度 ,然后zip每次从这个迭代器中拉出一组,合成为一个新的列表,最后再将所有列表合成为一个列表。
def main():
url = "https://www.bilibili.com/ranking/bangumi/13/0/3?spm_id_from=333.851.b_62696c695f7265706f72745f616e696d65.51"
text = get_html(url)
datas = get_datas(text)
with open('Bilibili新番榜排行前五十.txt', 'a', encoding = "utf-8") as file:
for rank, title, updata, play, view, fav, link in Slicing(datas, 7):
file.write(''.join(['排名: ',rank,' 标题: ',title,' 集数: ',updata,' 观看数: ', play,' 评论数: ',view, ' 喜欢数: ', fav, ' 链接 :',link, '\n']))
if __name__ == "__main__":
main()
最后我们只需要将这些数据保存到文件中,以utf-8的格式解码,然后用’’.join将列表中的所有元素连接成字符串
实现效果

完整代码
import requests
import bs4
def get_html(url):
proxies = {"http": "36.25.243.51", "http": "39.137.95.70", "http": "59.56.28.199"}
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.130 Safari/537.36'}
response = requests.get(url, headers = headers, proxies = proxies)
return response.text
def get_datas(text):
soup = bs4.BeautifulSoup(text, "html.parser")
data = []
animes = soup.find_all("li", class_= "rank-item")
for anime in animes :
title = anime.find('div','info').a.string
link = anime.find('div','info').a['href']
rank = anime.find('div','num').string
updata = anime.find('div', 'pgc-info').string
play = anime.find_all('span', class_='data-box')[0].text
view = anime.find_all('span', class_='data-box')[1].text
fav = anime.find_all('span', class_='data-box')[2].text
data.extend([rank, title, updata, play, view, fav, link])
return data
def Slicing(iterable, n):
return zip(*[iter(iterable)] * n)
def main():
url = "https://www.bilibili.com/ranking/bangumi/13/0/3?spm_id_from=333.851.b_62696c695f7265706f72745f616e696d65.51"
text = get_html(url)
datas = get_datas(text)
with open('Bilibili新番榜排行前五十.txt', 'a', encoding = "utf-8") as file:
for rank, title, updata, play, view, fav, link in Slicing(datas, 7):
file.write(''.join(['排名: ',rank,' 标题: ',title,' 集数: ',updata,' 观看数: ', play,' 评论数: ',view, ' 喜欢数: ', fav, ' 链接 :',link, '\n']))
if __name__ == "__main__":
main()
