1、爬虫心得
- 1、我们在写爬虫程序的时候可以采用面向对象的方式进行代码构造,使得代码结构更加清晰
- 2、放我们发现某个网站的PC端网页比较难爬的时候,我们可以查看其手机端是否好爬
- 3、本爬虫程序解析的文件为json数据文件
2、爬虫页面展示
-
原始json数据

-
通过json解析工具解析获得的数据
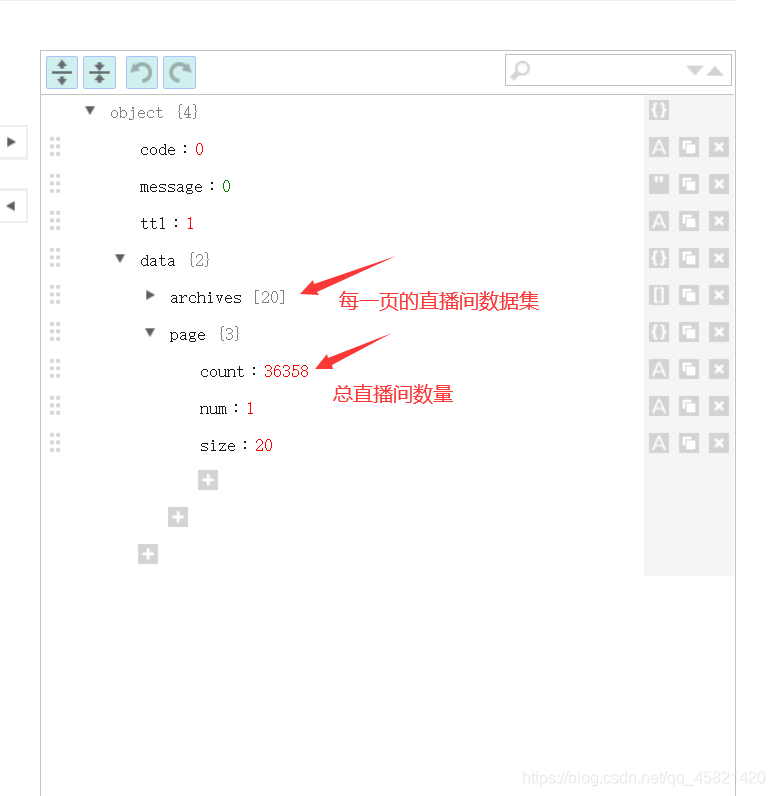
-
每一个直播的详情数据
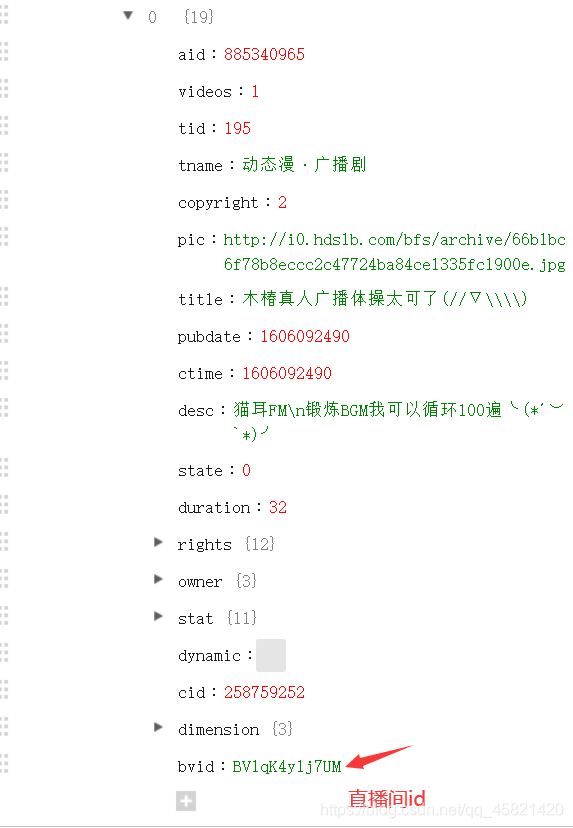
3、代码实操
import requests
import json
class BilibiliSpider():
def __init__(self):
self.start_url = 'http://api.bilibili.com/x/web-interface/newlist?rid=195&type=0&pn=1&ps=20'
self.url_base = 'http://api.bilibili.com/x/web-interface/newlist?rid=195&type=0&pn={}&ps=20'
self.headers = {
"User-Agent":" Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.111 Safari/537.36"}
# 通过映射来获取分类信息(每一个数字代表着不同的分类)
self.type_map = {
195:'国创'}
def parse_url(self,url):
print(url)
response = requests.get(url,self.headers)
return response.content.decode()
def get_content_list(self,html_str):
html_dict = json.loads(html_str)
archives_list = html_dict['data']['archives']
item_list = []
for archives in archives_list:
item = {
}
item['type'] = self.type_map[archives['tid']]
item['aid'] = archives['aid']
item['tname'] = archives['tname']
item['title'] = archives['title']
item['desc'] = archives['desc']
item['like'] = archives['stat']['like']
item['dislike'] = archives['stat']['dislike']
item['duration'] = archives['duration']
item['tv_url'] = 'https://www.bilibili.com/'+archives['bvid']
item_list.append(item)
return item_list
def save_content_list(self,item_list):
with open('bilibili.txt','a',encoding='utf-8') as f:
for item in item_list:
f.write(json.dumps(item,ensure_ascii=False,indent=2))
print('保存成功')
# 此函数首相通过起始url获取总直播间数量来构造页码方便翻页爬取
def get_page_count(self,start_url):
html_str = self.parse_url(start_url)
html_dict = json.loads(html_str)
item_count = html_dict['data']['page']['count']
page_size = html_dict['data']['page']['size']
page_count = item_count // page_size + 1 if item_count % page_size > 0 else item_count / page_size
return page_count
def run(self):
page_count = self.get_page_count(self.start_url)
for page_num in range(1,page_count+1):
html_str = self.parse_url(self.url_base.format(page_num))
content_list = self.get_content_list(html_str)
self.save_content_list(content_list)
if __name__ == '__main__':
bilibilispider = BilibiliSpider()
bilibilispider.run()
以上就是博主在爬取当当网所有图书的案例 希望可以帮助你们
关注我 分享更多爬虫案例