一、应用场景
假设你有一个商品的数据库,比如:
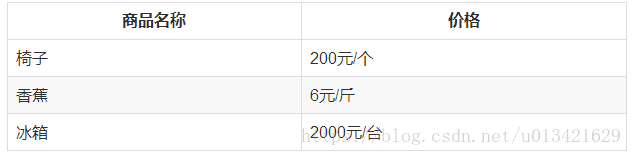
现在通过用户的输入来检索商品的价格。
方法一:直接匹配法
最简单的方法就是通过字符串进行匹配,比如,用户输入“椅子”,就用“椅子”作为关键字进行搜索,很容易找到椅子的价格就是200元/个。
方法二:语义相似法
但有时用户输入的是“凳子”,如果按照字符串匹配的方法,只能返回给用户,没有此商品。但实际上可以把“椅子”的结果返回给用户参考。这种泛化的能力,通过简单的字符串匹配是显然不能实现的。
“凳子”跟“椅子”的语意更相近,跟“香蕉”或“冰箱”的语意相对较远。在商品搜索的过程中,可以计算用户输入的关键字与数据库中商品名间的相似度,在商品数据库中找出相似度最大的商品,推荐给用户。
这种相近的程度就是词语的相似度。在实际的工程开发中可以通过word2vec实现词语相似度的计算。
二、使用gensim自带的word2vec包进行词向量的训练步骤
1、下载安装gensim,pip install gemsim
# 载包
from gensim.models import Word2Vec
from gensim.models.word2vec import LineSentence2、输入分词之后的维基语料进行词向量训练。
# 训练模型
sentences = LineSentence('F:/下载/content/comment.replay.weibo.txt')
model = Word2Vec(sentences, size=128, window=5, min_count=5, workers=8)
3、保存好咱们辛辛苦苦训练好的模型
# 保存模型
model.save('F:/下载/content/word_embedding_20180906')4、加载训练好的模型。
# 加载模型
model = Word2Vec.load("F:/下载/content/word_embedding_20180906")
5、测试词语之间的相似度
# 使用模型
items = model.most_similar('世界杯')
for i,j in items:
print(i,j)
kk=model.similarity('大奶', '大奶单')
print(kk)6、结果返回
奥运会 0.8269997835159302
欧洲杯 0.8262652158737183
美洲杯 0.8016794919967651
世青赛 0.7844665050506592
联合会杯 0.7776272296905518
亚运会 0.7528035640716553
亚青赛 0.7478761076927185
欧青赛 0.7465620040893555
东亚杯 0.7276486158370972
决赛圈 0.7204309701919556
0.7981703438609271
7、下面是全部代码:
训练word2vec模型:
# -*- encoding=utf-8 -*-
# 载包
from gensim.models import Word2Vec
from gensim.models.word2vec import LineSentence
# 训练模型
sentences = LineSentence('F:/下载/content/comment.replay.weibo.txt')
model = Word2Vec(sentences, size=128, window=5, min_count=5, workers=8)
# 存储咱们辛辛苦苦训练好的模型
model.save('F:/下载/content/word_embedding_20180906')
# # 加载模型
model = Word2Vec.load("F:/下载/content/word_embedding_20180906")
# # 使用模型
items = model.most_similar('高赔')
for i,j in items:
print(i,j)
运行结果:
高倍 0.7645919322967529
高配 0.7200379371643066
博单 0.6984660625457764
长串 0.6976152658462524
高培 0.6964673399925232
多串 0.6796765327453613
博冷 0.679004430770874
低倍 0.6455676555633545
低配 0.6336328387260437
2c1 0.6292942762374878
Process finished with exit code 0