最近一直在学习Lucene,今天分享一个个人的简单开源项目,可以将数据库中特定表的数据索引化,并支持了增量更新,近实时查询以及多线程索引建立的相关功能。
1.需求
为数据库中特定的表的数据提供全文检索功能,并且数据库的更新可以反映到全文检索的结果上(即近实时查询)。
2.实现思路
项目启动时使用多线程读取已经持久化在磁盘中的索引文件,并开启一个定时任务定期检索数据库中状态发生更改的数据,使用Lucene提供的RAMDirectory缓存这一部分数据,但为了保证内存使用不超过负荷需要在RAMDirectiory中缓存的document数量达到配置文件的指定数值后进行清理,并将清理的文档持久化到表数据对应的索引磁盘目录下。可以通过下面两个流程图进行简单的思路梳理。
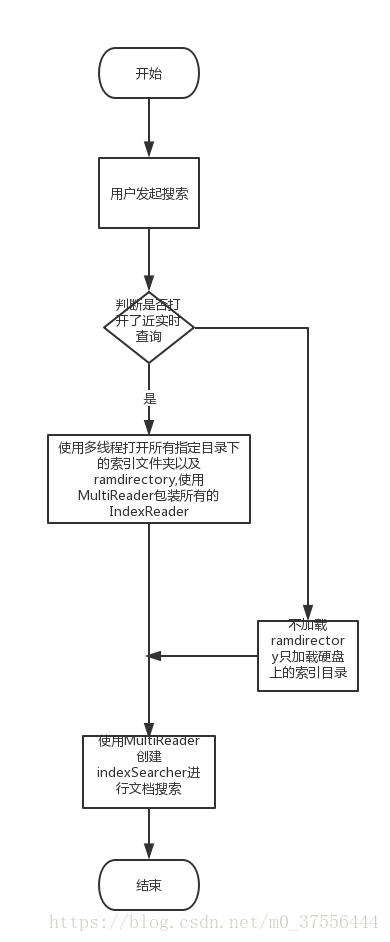
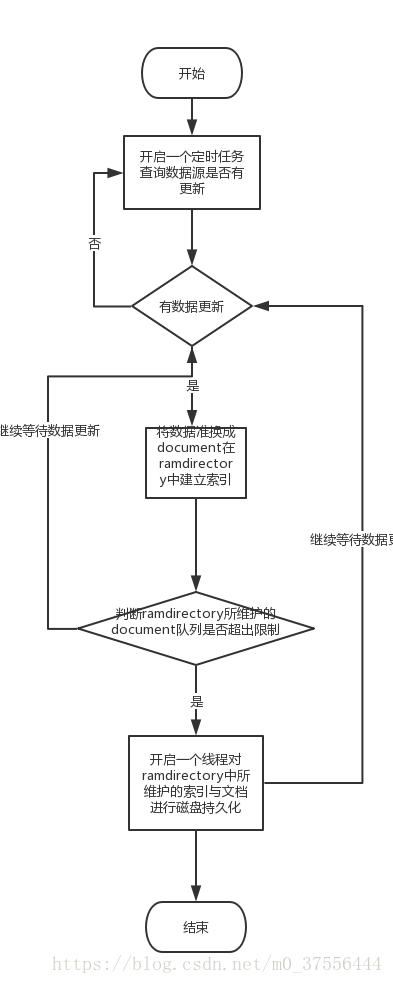
3.代码解析
1.HardDiskIndexReaderBuilderTask
首先我们需要从磁盘中加载已经持久化的索引目录,由于这样的索引目录通常情况下不止一个(通常一个表或者一个业务模块就会对应一个甚至多个索引目录)。所以为了加快索引的读取效率,使用多线程方式进行IndexReader的加载,使用Future异步获取结果。任务类代码如下:
package com.cfh.practice.searchengine.task;
import org.apache.lucene.index.DirectoryReader;
import org.apache.lucene.index.IndexReader;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.io.IOException;
import java.nio.file.Paths;
import java.util.concurrent.Callable;
/**
* @Author: cfh
* @Date: 2018/9/18 15:42
* @Description: 并行读取指定目录下的索引文件的任务类
*/
public class HardDiskIndexReaderBuilderTask implements Callable<IndexReader> {
final Logger log = LoggerFactory.getLogger(HardDiskIndexReaderBuilderTask.class);
//指定当前线程需要搜索的目录
String indexPath;
public HardDiskIndexReaderBuilderTask(String indexPath){
this.indexPath = indexPath;
}
@Override
public IndexReader call(){
try {
log.info("加载{}子目录下的索引", indexPath);
Directory directory = FSDirectory.open(Paths.get(indexPath));
IndexReader indexReader = DirectoryReader.open(directory);
log.info("{}子目录下的索引建立完成", indexPath);
return indexReader;
} catch (IOException e) {
e.printStackTrace();
}
return null;
}
}
2.IndexReaderLoader
IndexSearcher的构建类,使用线程池异步获取所有索引目录下的IndexReader之后包装成MultiReader进行多目录下索引的读取,同时根据需求返回实时或非实时的IndexSearcher供调用者调用。具体的实现细节请参考源码注释
package com.cfh.practice.searchengine.common;
import com.cfh.practice.searchengine.task.HardDiskIndexReaderBuilderTask;
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.cn.smart.SmartChineseAnalyzer;
import org.apache.lucene.index.*;
import org.apache.lucene.search.IndexSearcher;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.io.File;
import java.io.IOException;
import java.nio.file.Paths;
import java.util.ArrayList;
import java.util.List;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Future;
/**
* @Author: cfh
* @Date: 2018/9/18 16:02
* @Description: IndexSearcher的构建类,根据传入的参数决定是否需要开启近实时查询
*/
public class IndexReaderLoader {
String dirPath;
ExecutorService executorService;
Logger log = LoggerFactory.getLogger(IndexReaderLoader.class);
public IndexReaderLoader(String dirPath, ExecutorService executorService) {
this.dirPath = dirPath;
this.executorService = executorService;
//先在所有子目录下commit一遍防止读取时出现no segments异常
try {
writeAndCommit(dirPath);
} catch (Exception e) {
e.printStackTrace();
log.info("索引目录初始化出现错误:{}",e.getCause());
}
loadIndexReaderFromHardDisk(dirPath, executorService);
}
public void writeAndCommit(String dirPath) throws Exception{
log.info("初始化索引目录");
File rootPath = new File(dirPath);
File[] files = rootPath.listFiles();
for(File file : files){
if(file.exists() && file.isDirectory()){
Directory directory = FSDirectory.open(Paths.get(file.getPath()));
Analyzer analyzer = new SmartChineseAnalyzer();
IndexWriterConfig iWConfig = new IndexWriterConfig(analyzer);
IndexWriter indexWriter = new IndexWriter(directory, iWConfig);
indexWriter.commit();
indexWriter.close();
}
}
log.info("索引初始化完成");
}
private List<IndexReader> loadIndexReaderFromHardDisk(String dirPath, ExecutorService executorService){
List<IndexReader> readers = new ArrayList<>();
log.info("从根路径{}下加载索引", dirPath);
File rootPath = new File(dirPath);
File[] files = rootPath.listFiles();
log.info("路径{}下有{}个子目录", dirPath, files.length);
List<Future<IndexReader>> futures = new ArrayList<>();
for(File file : files){
if(file.isDirectory() && file.exists()){
Future<IndexReader> future = executorService.submit(new HardDiskIndexReaderBuilderTask(file.getPath()));
futures.add(future);
}
}
//异步获取读取到的索引的结果
for(Future<IndexReader> future : futures){
try {
IndexReader result = future.get();
readers.add(result);
log.info("读取完{}条索引", result.getRefCount());
} catch (InterruptedException e) {
e.printStackTrace();
} catch (ExecutionException e) {
e.printStackTrace();
}
}
return readers;
}
/**
* 获取非近实时的IndexSearcher
* 这种写法每次获取索引都需要读取一遍磁盘,一般只适用于对搜索实时性特别高的情况
* @return
*/
public IndexSearcher getUnRealTimeSearch() {
List<IndexReader> indexReaderList = loadIndexReaderFromHardDisk(dirPath, executorService);
IndexReader[] indexReaders = indexReaderList.toArray(new IndexReader[indexReaderList.size()]);
MultiReader multiReader = null;
try {
multiReader = new MultiReader(indexReaders);
} catch (IOException e) {
e.printStackTrace();
}
return new IndexSearcher(multiReader);
}
/**
* 获取近实时的IndexSearcher
* @return
*/
public IndexSearcher getRealTimeSearch(){
IndexReader reader = null;
try {
//使用RAMDirectory缓存的索引达到近实时查询的功能
reader = DirectoryReader.open(RAMDirectoryControl.getRAMDirectory());
List<IndexReader> indexReaderList = loadIndexReaderFromHardDisk(dirPath, executorService);
indexReaderList.add(reader);
IndexReader[] indexReaders = indexReaderList.toArray(new IndexReader[indexReaderList.size()]);
MultiReader multiReader = new MultiReader(indexReaders);
return new IndexSearcher(multiReader);
} catch (IOException e) {
e.printStackTrace();
}
//若出现异常则降级为获取非实时的IndexSearcher
return getUnRealTimeSearch();
}
}
这样的写法其实有一个问题,我为了索引查询的实时性每次获取IndexSearcher时都对持久化在磁盘目录下的索引文件进行了读取, 实际使用的时候可以使用缓存的IndexReaders并定期对IndexReaders进行更新(以牺牲实时查询的准确率为代价换取性能上的提升)。
3.IndexReaderLoaderConfig
IndexReaderLoader的配置类,配置IndexReaderLoader随容器启动而注入。没什么好说的注意bean名(默认是@bean注解的方法名)不要重复即可。
package com.cfh.practice.searchengine.config;
import com.cfh.practice.searchengine.common.IndexReaderLoader;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import java.io.IOException;
import java.util.Properties;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
/**
* @Author: cfh
* @Date: 2018/9/18 23:22
* @Description: 配置并注入IndexReaderLoader
*/
@Configuration
public class IndexReaderLoaderConfig {
Logger log = LoggerFactory.getLogger(IndexReaderLoaderConfig.class);
@Bean
public IndexReaderLoader indexReaderLoader(){
log.info("开始注入IndexReaderLoader");
Properties properties = new Properties();
try {
properties.load(this.getClass().getClassLoader().getResourceAsStream("lucene_index.properties"));
} catch (IOException e) {
e.printStackTrace();
log.info("出现错误,注入失败");
}
String indexMainPath = properties.getProperty("index_main_path");
int coreThread = new Integer(properties.getProperty("reader_load_core_thread_size")).intValue();
ExecutorService executorService = Executors.newFixedThreadPool(coreThread);
log.info("IndexReaderLoader注入完成");
return new IndexReaderLoader(indexMainPath, executorService);
}
}
4.DataSourceFlushTask
既然有了建立索引的任务类,那么理所应当的拥有可以刷新数据源操作索引的相关任务类。由于数据源可能有多个,所以将一些公共行为抽象到了父类中,子类只需要实现updateIndex()方法指定从哪个数据源怎么刷新数据以及getIndexWriter()方法即如何获取IndexWriter即可。主要的逻辑集中在consume方法上,即根据RAMDirectoy的使用情况对刷新的数据进行消费。一些细节上的问题在源码都有详细注释应该不难理解
package com.cfh.practice.searchengine.task;
import com.cfh.practice.searchengine.common.Consts;
import com.cfh.practice.searchengine.common.RAMDirectoryControl;
import com.cfh.practice.searchengine.util.ObjectTransferUtil;
import com.cfh.practice.searchengine.util.SearchUtils;
import org.apache.lucene.document.Document;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.index.Term;
import org.apache.lucene.search.*;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.io.IOException;
import java.util.LinkedList;
import java.util.List;
/**
* @Author: cfh
* @Date: 2018/9/18 16:54
* @Description: 定时询问数据源查看是否有新入库尚未建立索引的数据,对这部分数据建立索引并写入RAMDirectory
*/
public abstract class DataSourceFlushTask implements Runnable{
//持久化磁盘的路径
String persistenceIndexDirPath;
IndexWriter indexWriter;
final Logger logger = LoggerFactory.getLogger(DataSourceFlushTask.class);
public DataSourceFlushTask(String persistenceIndexDirPath) {
this.persistenceIndexDirPath = persistenceIndexDirPath;
}
public DataSourceFlushTask() {
}
/**
* 更新索引
*/
protected abstract void updateIndex();
protected void consume(List flushList, Class clazz, Logger log) {
//首先创建一个可以查询出所有doc的Query用于检测RAMDirectory中已经存储了多少篇doc
Query query = new MatchAllDocsQuery();
IndexSearcher searcher = null;
try {
searcher = RAMDirectoryControl.getRAMIndexSearcher();
} catch (IOException e) {
logger.info("e:",e.getCause());
e.printStackTrace();
}
if(searcher == null){
logger.info("searcher is null");
return;
}
TopDocs topDocs = SearchUtils.getScoreDocsByPerPageAndSortField(searcher, query, 0, new Long(Consts.RAMDDirectory.RAM_LIMIT_DOC).intValue(), null);
//从topDocs中获取到当前RAMD中的doc数
long currentTotal = topDocs.totalHits;
logger.info("RAMDirectory currentTotal:{}", currentTotal);
//刷新的文档超出限制情况下的处理逻辑
if(currentTotal + flushList.size() > Consts.RAMDDirectory.RAM_LIMIT_DOC){
logger.info("RAMDirectory余量不足");
long pulCount = Consts.RAMDDirectory.RAM_LIMIT_DOC - currentTotal;
List<Document> docs = new LinkedList<>();
if(pulCount <= 0){//内存已经撑爆的情况
log.info("开始将RAMDirectory中的document持久化到磁盘中");
TopDocs allDocs = SearchUtils.getScoreDocsByPerPageAndSortField(searcher, query, 0, (int)currentTotal, null);
ScoreDoc[] scoreDocs = allDocs.scoreDocs;
for(ScoreDoc scoreDoc : scoreDocs){
Document doc = null;
try {
doc = searcher.doc(scoreDoc.doc);
} catch (IOException e) {
e.printStackTrace();
}
String pollId = doc.get("id");
String clazz1 = doc.get("clazz");
//将内存中的文档删除
RAMDirectoryControl.deleteAppointDocument(pollId, clazz1);
//将内存中的文档持久化到磁盘
IndexWriter indexWriter = getIndexWriter();
if(indexWriter == null){
return;
}
if(doc.get("clazz").equals(clazz.getName())){
persistenceData(getIndexWriter(), doc);
}
}
try {
//一次持久化过程之后再commit而不是每写入一篇document就commit
getIndexWriter().commit();
} catch (IOException e) {
e.printStackTrace();
}
//使用一个递归将更新的数据塞进已经进行过清理的RAMDirectory中
consume(flushList, clazz, log);
}else{//内存仍有余量但无法存储当次数据所有内容的情况
List<Document> subHalfList = flushList.subList(0, (int)pulCount);
consume(subHalfList, clazz, log);
List<Document> rearHalfList = flushList.subList((int)pulCount, flushList.size());
consume(rearHalfList, clazz, log);
}
}else{//未超出限制,直接放入RAMDirectory
logger.info("RAMDirectory余量充足可以直接存入");
for(Object object : flushList){
try {
Document document = ObjectTransferUtil.bean2Doc(object, clazz);
IndexWriter rwIndexWriter = RAMDirectoryControl.getRAMIndexWriter();
//先删除旧的document防止重复
BooleanQuery.Builder builder = new BooleanQuery.Builder();
builder.add(new TermQuery(new Term("id", document.get("id"))), BooleanClause.Occur.MUST);
builder.add(new TermQuery(new Term("clazz", document.get("clazz"))), BooleanClause.Occur.MUST);
rwIndexWriter.deleteDocuments(builder.build());
//再写入新的document
rwIndexWriter.addDocument(document);
rwIndexWriter.commit();
} catch (Exception e) {
e.printStackTrace();
log.info("bean转文档出错,未放入RAMD中");
}
}
}
}
protected void persistenceData(IndexWriter indexWriter, Document document){
try {
//先删再增防止文档发生重复
//先删除旧的document防止重复
BooleanQuery.Builder builder = new BooleanQuery.Builder();
builder.add(new TermQuery(new Term("id", document.get("id"))), BooleanClause.Occur.MUST);
builder.add(new TermQuery(new Term("clazz", document.get("clazz"))), BooleanClause.Occur.MUST);
indexWriter.deleteDocuments(builder.build());
indexWriter.addDocument(document);
//indexWriter.commit();
} catch (IOException e) {
e.printStackTrace();
}
}
protected abstract IndexWriter getIndexWriter();
@Override
public void run(){
updateIndex();
}
}
在对刷新的数据建立索引时直接使用了ObjectTransferUtil.bean2Doc(object, clazz)这个方法,使用反射的方式全自动的建立索引。如果使用者对需要建立的索引有特殊的需求可以替换这个方法为自己的实现进行索引建立。源码实现如下
5.ObjectTransferUtil
package com.cfh.practice.searchengine.util;
import org.apache.lucene.document.Document;
import org.apache.lucene.document.StringField;
import org.apache.lucene.document.TextField;
import javax.print.Doc;
import java.io.File;
import java.lang.reflect.Field;
/**
* @Author: cfh
* @Date: 2018/9/18 22:06
* @Description: 对象之间相互转换的util类
*/
public class ObjectTransferUtil {
/**
* 将指定的bean转换为document
* @param object
* @param clazz
* @return
*/
public static Document bean2Doc(Object object, Class clazz) throws Exception{
Field[] fields = clazz.getDeclaredFields();
Document document = new Document();
for (Field field : fields){
String fieldName = field.getName();
//设置可以访问类中的私有属性,也可以通过invoke字段对应的标准get方法进行获取
field.setAccessible(true);
String fieldContent = field.get(object).toString();
//当索引的长度超过多少时选择分词
if(fieldContent.getBytes().length > 50){
document.add(new TextField(fieldName, fieldContent, org.apache.lucene.document.Field.Store.NO));
}else{
document.add(new TextField(fieldName, fieldContent, org.apache.lucene.document.Field.Store.YES));
}
}
//标识document对应的实体类型的索引字段,为文档防重以及文档实体相互转换提供信息支持
document.add(new StringField("clazz", clazz.getName(), org.apache.lucene.document.Field.Store.YES));
return document;
}
}
下面提供一个任务类的具体实现类,对TV表的数据进行刷新
5.TvFlushTask
package com.cfh.practice.searchengine.task;
import com.cfh.practice.searchengine.pojo.Tv;
import com.cfh.practice.searchengine.service.TvService;
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.cn.smart.SmartChineseAnalyzer;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.index.IndexWriterConfig;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.beans.factory.annotation.Autowired;
import java.io.IOException;
import java.nio.file.Paths;
import java.util.List;
/**
* @Author: cfh
* @Date: 2018/9/18 17:12
* @Description: 刷新存储了tv相关信息的数据源
*/
public class TvFlushTask extends DataSourceFlushTask{
final Logger log = LoggerFactory.getLogger(TvFlushTask.class);
//IndexWriter indexWriter;
//注入数据源
@Autowired
TvService tvService;
public TvFlushTask(String persistenceIndexDirPath) {
super(persistenceIndexDirPath);
}
@Override
protected void updateIndex() {
//获取数据源中新刷新的数据
List<Tv> flushList = tvService.flushDataSource();
if (flushList != null && flushList.size() != 0){
log.info("数据源发现更新数据,共{}条", flushList.size());
consume(flushList, Tv.class, log);
}else{
log.info("数据源无更新,当次任务结束");
}
}
/**
* 使用单例模式获取IndexWriter
* @return
* @throws Exception
*/
@Override
protected IndexWriter getIndexWriter(){
if (indexWriter == null) {
synchronized (TvFlushTask.class) {
try {
Directory directory = FSDirectory.open(Paths.get(persistenceIndexDirPath));
Analyzer analyzer = new SmartChineseAnalyzer();
IndexWriterConfig iWConfig = new IndexWriterConfig(analyzer);
iWConfig.setOpenMode(IndexWriterConfig.OpenMode.CREATE_OR_APPEND);
indexWriter = new IndexWriter(directory, iWConfig);
} catch (IOException e) {
e.printStackTrace();
return null;
}
}
}
return indexWriter;
}
}
6.TvService
我这里是通过检查表中的一个字段检查是否有数据刷新,并在刷新出数据后改变该字段的状态,所以需要一个事务操作
package com.cfh.practice.searchengine.service;
import com.cfh.practice.searchengine.common.IndexReaderLoader;
import com.cfh.practice.searchengine.dao.TvMapper;
import com.cfh.practice.searchengine.pojo.Tv;
import com.cfh.practice.searchengine.util.SearchUtils;
import org.apache.lucene.document.Document;
import org.apache.lucene.search.IndexSearcher;
import org.apache.lucene.search.Query;
import org.apache.lucene.search.ScoreDoc;
import org.apache.lucene.search.TopDocs;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import org.springframework.transaction.annotation.Transactional;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
/**
* @Author: cfh
* @Date: 2018/9/19 09:39
* @Description:
*/
@Service
public class TvService {
@Autowired
TvMapper tvMapper;
@Autowired
IndexReaderLoader indexReaderLoader;
/**
* 刷新数据源,同时将已刷新的数据的刷新状态修改,所以需要放在一个事务中
* @return
*/
@Transactional
public List<Tv> flushDataSource() {
List<Tv> results = tvMapper.flushDataSource();
/**
* 改变已刷新的数据的数据状态
*/
for (Tv tv : results) {
tv.setIsUpdate(0);
tvMapper.updateByPrimaryKey(tv);
}
return results;
}
public List<Tv> fulltexrSearchInAppointIndex(String field, Query query, boolean realTimeSearch, int pageNum, int pagePer){
IndexSearcher indexSearcher = null;
if (realTimeSearch){
indexSearcher = indexReaderLoader.getRealTimeSearch();
} else{
indexSearcher = indexReaderLoader.getUnRealTimeSearch();
}
TopDocs topDocs = null;
if (pageNum == 1){
topDocs = SearchUtils.getScoreDocsByPerPageAndSortField(indexSearcher, query, 0, pagePer, null);
} else {
int begin = pageNum * (pagePer - 1);
topDocs = SearchUtils.getScoreDocsByPerPageAndSortField(indexSearcher, query, begin, pageNum, null);
}
List<Tv> searchResult = new ArrayList<>();
for (ScoreDoc scoreDoc : topDocs.scoreDocs){
Document document = null;
try {
document = indexSearcher.doc(scoreDoc.doc);
} catch (IOException e) {
e.printStackTrace();
}
if(document == null){
continue;
}
Tv tv = tvMapper.selectByPrimaryKey(new Long(document.get("id")));
searchResult.add(tv);
}
return searchResult;
}
public void addData(Tv tv){
tvMapper.insert(tv);
}
}
7.RAMDirectoryControl
由于我们多出需要使用RAMDirectory,建立一个Contro类对其进行管理
package com.cfh.practice.searchengine.common;
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.cn.smart.SmartChineseAnalyzer;
import org.apache.lucene.index.*;
import org.apache.lucene.search.*;
import org.apache.lucene.store.RAMDirectory;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.io.IOException;
/**
* @Author: cfh
* @Date: 2018/9/18 16:47
* @Description: RAMDirectory相关控制类
*/
public class RAMDirectoryControl {
private static RAMDirectory ramDirectory;
private static IndexWriter indexWriter;
Logger log = LoggerFactory.getLogger(RAMDirectoryControl.class);
public RAMDirectoryControl(){
log.info("init RAMDirectoryControl");
ramDirectory = new RAMDirectory();
indexWriter = getRAMIndexWriter();
log.info("finish init RAMDirectoryControl");
}
public static RAMDirectory getRAMDirectory(){
return ramDirectory;
}
public static IndexSearcher getRAMIndexSearcher() throws IOException{
IndexReader reader = null;
IndexSearcher searcher = null;
try {
reader = DirectoryReader.open(ramDirectory);
} catch (IOException e) {
e.printStackTrace();
}
searcher = new IndexSearcher(reader);
return searcher;
}
/**
* 使用单例模式获取IndexWriter
* @return
*/
public static IndexWriter getRAMIndexWriter(){
if(indexWriter == null){
synchronized (IndexWriter.class){
//使用中文分词器
Analyzer analyzer = new SmartChineseAnalyzer();
IndexWriterConfig iWConfig = new IndexWriterConfig(analyzer);
//以追加模式写入索引
iWConfig.setOpenMode(IndexWriterConfig.OpenMode.CREATE_OR_APPEND);
try {
indexWriter = new IndexWriter(getRAMDirectory(), iWConfig);
//初始化时需要commit一次防止出现no segment异常
indexWriter.commit();
indexWriter.close();
/*
这里必须要重新new一个IndexWriterConfig,如果直接使用原先的会抛
Caused by: java.lang.IllegalStateException: do not share IndexWriterConfig instances across IndexWriters异常
*/
iWConfig = new IndexWriterConfig(analyzer);
iWConfig.setOpenMode(IndexWriterConfig.OpenMode.CREATE_OR_APPEND);
indexWriter = new IndexWriter(getRAMDirectory(), iWConfig);
} catch (IOException e) {
e.printStackTrace();
}
}
}
return indexWriter;
}
/**
* 根据指定的id信息删除document
* @param id id
* @param clazz 用于防止id相同的附加信息
*/
public static void deleteAppointDocument(String id, String clazz){
BooleanQuery.Builder builder = new BooleanQuery.Builder();
builder.add(new TermQuery(new Term("id", id)), BooleanClause.Occur.MUST);
builder.add(new TermQuery(new Term("clazz", clazz)), BooleanClause.Occur.MUST);
try {
getRAMIndexWriter().deleteDocuments(builder.build());
getRAMIndexWriter().commit();
} catch (IOException e) {
e.printStackTrace();
}
}
}
可以看到我们这里对IndexWriter的获取使用了单例模式
8.DataSourceaFlushExecutor
数据源刷新任务的执行类,完成初始化后即开启一系列定时任务对一个或多个数据源进行刷新
package com.cfh.practice.searchengine.common;
import com.cfh.practice.searchengine.task.DataSourceFlushTask;
import java.util.List;
import java.util.concurrent.Executors;
import java.util.concurrent.ScheduledExecutorService;
import java.util.concurrent.TimeUnit;
/**
* @Author: cfh
* @Date: 2018/9/18 23:03
* @Description: 开启一个定时任务定时检索数据源并进行索引的增量更新
*/
public class DataSourceFlushExecutor {
List<DataSourceFlushTask> dataSourceFlushTaskList;
//指定定时任务的间隔时间
long fixRate;
public DataSourceFlushExecutor(List<DataSourceFlushTask> dataSourceFlushTaskList, long fixRate) {
this.dataSourceFlushTaskList = dataSourceFlushTaskList;
this.fixRate = fixRate;
init();
}
public void init(){
ScheduledExecutorService executor = Executors.newScheduledThreadPool(dataSourceFlushTaskList.size());
for(DataSourceFlushTask task : dataSourceFlushTaskList){
executor.scheduleAtFixedRate(task, fixRate, fixRate, TimeUnit.MILLISECONDS);
}
}
}
9.DataSourceFlushExecutorConfig
定时刷新任务的相关配置类。做一些初始化配置,并让定时任务随容器的启动而启动。
package com.cfh.practice.searchengine.config;
import com.cfh.practice.searchengine.common.DataSourceFlushExecutor;
import com.cfh.practice.searchengine.common.RAMDirectoryControl;
import com.cfh.practice.searchengine.task.DataSourceFlushTask;
import com.cfh.practice.searchengine.task.TvFlushTask;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
import java.util.Properties;
/**
* @Author: cfh
* @Date: 2018/9/18 23:21
* @Description: 配置数据源刷新线程池并加入并开启定时任务
*/
@Configuration
public class DataSourceFlushExecutorConfig {
Logger log = LoggerFactory.getLogger(DataSourceFlushExecutorConfig.class);
@Bean
public DataSourceFlushExecutor dataSourceFlushExecutor(TvFlushTask tvFlushTask){
log.info("开始注入DataSourceFlushExecutor");
List<DataSourceFlushTask> tasks = new ArrayList<>();
Properties properties = new Properties();
try {
properties.load(getClass().getClassLoader().getResourceAsStream("lucene_index.properties"));
} catch (IOException e) {
e.printStackTrace();
log.info("DataSourceFlushExecutor注入失败");
}
long flushFixRate = new Long(properties.getProperty("flush_fix_rate")).longValue();
log.info("flush_fix_rate:{}", flushFixRate);
tasks.add(tvFlushTask);
log.info("DataSourceFlushExecutor注入完成");
return new DataSourceFlushExecutor(tasks, flushFixRate);
}
@Bean(name = "tvFlushTask")
public TvFlushTask tvFlushTaskConfig(){
log.info("开始注入TvFlushTask");
Properties properties = new Properties();
try {
properties.load(this.getClass().getClassLoader().getResourceAsStream("lucene_index.properties"));
} catch (IOException e) {
e.printStackTrace();
}
String indexTvPath = properties.getProperty("index_tv_path");
log.info("indexTvPath:{}", indexTvPath);
log.info("TvFlushTask注入完成");
return new TvFlushTask(indexTvPath);
}
@Bean
public RAMDirectoryControl ramDirectoryControl(){
return new RAMDirectoryControl();
}
}
4.项目开源地址
项目开源在github上啦,有想学习或者要提出意见指出错误的小伙伴都可以去看一看github地址。关于luecen的系统性学习就此告一段落了。接下来就是在实际使用过程中挖坑填坑的过程了。即将到来的11月份也将开始自己第一份全职实习,希望自己能够顶住压力,也希望大家都可以不断的提升自己,迎接生活中无处不在的挑战。