第三周学习笔记
本周学习内容
1.CS229
第六讲,朴素贝叶斯算法
主要内容
- 朴素贝叶斯(Naive Bayes)
- 神经网络(Neural Network)
- 支持向量机(Support Vector Machine)
第七讲,最优间隔分类器问题
主要内容
- 支持向量机(从Intuition到凸优化)
- 拉格朗日乘数法(Lagrange Multipliers)
- 对偶问题的导出
- Karush-Kuhn-Tucker(KKT条件)
值得注意的地方
1.对偶问题导出的意义
原问题虽然已经能够转化成凸优化问题,导出对偶问题的意义在于之后使用核方法,将特征向量映射到高维空间中,从而解决一些在原空间拥有非线性决策边界的问题。
第八讲,顺序最小优化器
主要内容
- 核函数,从线性不可分映射到线性可分
- L1 norm软间隔SVM,为了针对非线性可分的问题以及降低少数异常数据对超平面位置的影响
- 坐标上升法(coordinate assent)
- SMO算法(sequential minimal optimization)
值得注意的地方
1.高斯核
高斯核将原特征向量映射到了无限维向量空间中,但不需要显式计算出特征向量,因为对偶问题使得优化问题中只有特征向量的内积形式,只需要在内积之间作映射即可,核函数具有计算复杂度低、无需显式计算特征向量的特点。
2.为什么线性高斯核 可以得到 个特征?
首先明确什么是一个特征,一个特征是
展开成为关于
的多元多项式中的一项
于是原问题转化为,
展开合并后有多少项
于是原问题转化为,从
个物品中可重复地选择
个物品不排列有多少种选法
因此有
个特征
3.核函数的应用
核函数不仅仅是SVM中特有的,任何可以将问题中关于特征向量的计算转化为内积形式的算法都可以使用核函数,使得我们以较小的时间代价来在高维空间中寻找超平面。
2.实验
Logistic Regression 和 Locally weighted Logistic Regression的比较
实验题目:Logistic Regression 和 Locally weighted Logistic Regression的比较
实验目的:了解两个算法的特点
实验步骤:
1.生成数据集:
生成非线性可分的数据集,以1为半径画圆作为Ground Truth,保证两类样本比例约为1:1,如图所示
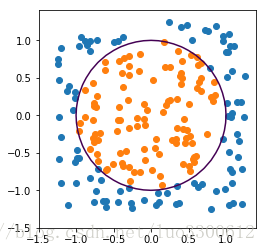
2.使用logistic回归拟合数据集,选择不同的正则化参数

3.选择局部加权Logistic回归的权值计算方法:
4.根据Ground Truth随机生成测试集
5.测试两个算法的准确率
实验结果
1.直接使用Logistic回归存在很大的欠拟合,为防止过拟合的正则化参数失去意义。
2.两个算法的准确率如表所示(LR表示Logistic Regression,LWLR表示Locally Weighted Logistic Regression)
| 方法 | LR | LWLR | LWLR | LWLR | LWLR | LWLR | LWLR |
|---|---|---|---|---|---|---|---|
| 准确率 | 48% | 78% | 93% | 94% | 91% | 88% | 49% |
结论
1.在原始特征下,LWLR相比LR能够更好地处理线性不可分的数据集,因为某些数据集虽然整体线性不可分,但在局部上线性可分,这就很好地利用了LWLR对预测值周围给予更多关注的优点。
2.LWLR相比LR的时间和空间成本更高,需要对每个预测值进行一次计算,且需要一直保存数据集,而后者只需要保存学习到的权值。
Naive Bayes
实验题目:朴素贝叶斯和拉普拉斯平滑
实验目的:学习朴素贝叶斯
实验步骤:
1.数据集:
西瓜数据集3.0
2.分割训练集测试集
3.使用朴素贝叶斯
4.使用Laplace平滑
实验结果
1.直接使用朴素贝叶斯得到75%准确率
2.使用Laplace平滑得到50%准确率
结论
数据集过小,限制了算法的应用
本周不足之处
未能实现上周所说的目标
下周计划
继续学习CS229,以5课为目标