第六周学习笔记
本周的主要学习工作
1.CS229
第十七讲,离散与维数灾难
主要内容
- 离散化
- 为MDP学习模型
- 拟合值迭代算法(Fitted value iteration),连续状态空间的强化学习算法
值得注意的地方
1.未知的 和
即便我们能够通过值迭代或策略迭代来解决MDP问题,但对于一些实际问题,我们不知道 和 的具体值,这时我们可以通过采样,在寻找策略的过程中同时模拟出真实的模型
第十八讲,线性二次型调节控制
笔记
- 有限边界MDP(Finite horizon MDPs),过程终止于step T,用T取代MDP五元组中的 ,并且假设策略和转移概率是非平稳的(依赖时间的),回报函数同时依赖于状态和动作
- 有限边界的动态规划算法
- 线性二次型法则(linear quadratic regulation)
- Bacardi离散方程
值得注意的地方
1.有限边界MDP为什么没有
有限边界MDP和 的意义都在于让MDP过程是有限的,所以两者往往不同时使用
2.对物理模型的模拟
可以通过我们关注的点的的一阶泰勒展式来对物理模型进行线性估计。
2.实验
实验题目:走迷宫
实验目的:学习策略迭代,值迭代算法以及就地值迭代算法
实验过程:
1.描述
在一个5*5的迷宫中,有两个特殊的格点,分别是A(1,2)和B(1,4),当走到A点时,会自动移动到A’(5,2),并获得+10奖励,当走到B点时,会自动移动到B’(3,4),并获得+5奖励,任何试图走出边界的行为会得到-1的奖励,其他情况均获得0奖励, =0.9
2.分别使用策略迭代,值迭代和就地值迭代算法
实验结果:
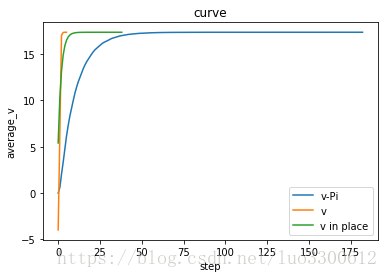
从图中可见,值迭代算法的收敛速度>就地值迭代算法>策略迭代算法
下周目标
完成CS229的学习,并做好总结