传送门: 传送门
backward是利用代价函数求取关于网络中每个参数梯度的过程,为后面更新网络参数做准备。求取梯度的过程也是一个矩阵运算的过程,后面会有详细介绍,本身求取梯度的过程并不是很复杂,而且网络中的各层求取梯度的过程都是相似的。下面就按照backward的运行顺序,从最后一层向前介绍caffe的backward的过程。
- softmax with loss layer:
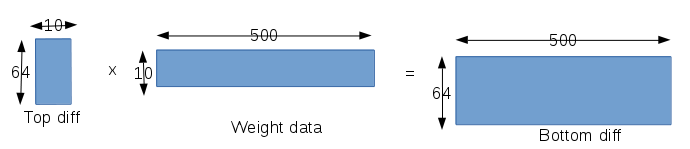
按理说每一层应该都要求一层梯度,其中包括对权值,对输入数据,对偏置分别求取梯度。但是在softmax with loss layer这一层求取梯度的一些过程被省去了,首先这一次只是一个激活函数层,没有权值和偏置参数,然后我们只需要对输入数据求取梯度,softmax with loss layer的输入数据其实表示的是原始输入数据相对于各个标签的打分,而对于代价函数对这个输入的梯度已经有专门的迭代算法来求解。参考:http://ufldl.stanford.edu/wiki/index.php/Softmax%E5%9B%9E%E5%BD%92。
caffe中的程序对应如下:-
for (int i = 0; i < outer_num_; ++i) { -
for (int j = 0; j < inner_num_; ++j) { -
const int label_value = static_cast<int>(label[i * inner_num_ + j]); -
if (has_ignore_label_ && label_value == ignore_label_) { -
for (int c = 0; c < bottom[0]->shape(softmax_axis_); ++c) { -
bottom_diff[i * dim + c * inner_num_ + j] = 0; -
} -
} else { -
bottom_diff[i * dim + label_value * inner_num_ + j] -= 1; //http://ufldl.stanford.edu/wiki/index.php/Softmax -
++count; -
} -
} -
} -
// Scale gradient -
Dtype loss_weight = top[0]->cpu_diff()[0] / -
get_normalizer(normalization_, count); -
caffe_scal(prob_.count(), loss_weight, bottom_diff);
-
- inner product layer:
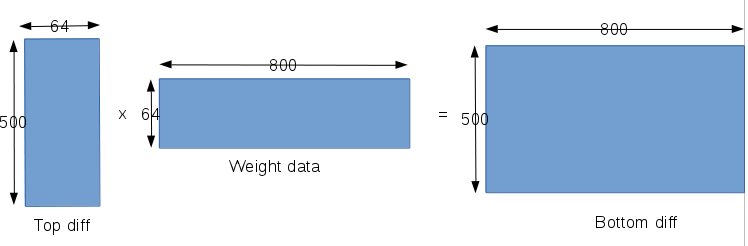
这是一层全连接层,包含权值,偏置参数,所以在这一层我们要求3个梯度值,第一是对偏置求取梯度,第二是对权值求取梯度,第三是对输入数据求取梯度,其中对输入数据求取的梯度和前面类似会反向传播到前一层。- 在对权值参数求取梯度之前,我们首先要明确当前层有多少个权值参数,权值参数相互之间又是什么结构的。该层网络的输入数据宽度是500,输出数据宽度是10,而且每个神经元都与输入全连接,所以该层网络应该有500x10个权值参数,那我们最终求得的对于权值的梯度应该也是有500x10个数据。而由于网络的训练以batch为单位,一个batch中又包含64个samples,所以对于500x10个权值参数中的一个,应该是对一个batch中的64个输出都有作用,所以我们求取关于某一个权值参数的梯度时,就要包含64个samples的数据。另外一方面根据weight_diff = top_diff * bottom_data(即该层输出对于输入的偏导,链式法则)。整个求取梯度的运算也是可以转化为矩阵运算的,这里caffe也是用一次矩阵运算计算对所有权值参数的梯度,caffe的矩阵构造如下:
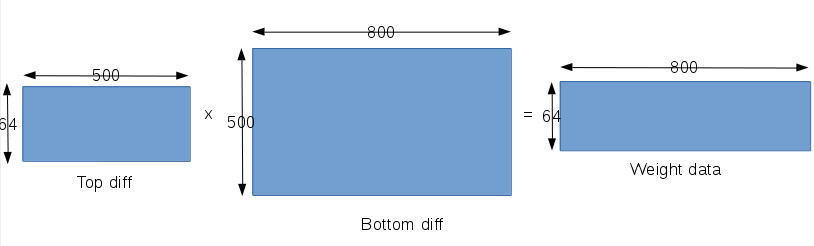
- 对输入数据求取梯度,对输入数据求取梯度的时候,我们又要明确单个输入数据是和哪些神经元连接,在caffe中的lenet模型中都是全连接,即输入连接到所有的神经元上,在这种情况下,求取关于单个输入的梯度就要包含所有的神经元,具体一点就是包含所有神经元对应在这单个输入的权值。同时又要考虑网络训练是以batch为单位的,即我们要处理64个样本,在对输入数据求取梯度上,caffe构造的矩阵如下:
- 在对权值参数求取梯度之前,我们首先要明确当前层有多少个权值参数,权值参数相互之间又是什么结构的。该层网络的输入数据宽度是500,输出数据宽度是10,而且每个神经元都与输入全连接,所以该层网络应该有500x10个权值参数,那我们最终求得的对于权值的梯度应该也是有500x10个数据。而由于网络的训练以batch为单位,一个batch中又包含64个samples,所以对于500x10个权值参数中的一个,应该是对一个batch中的64个输出都有作用,所以我们求取关于某一个权值参数的梯度时,就要包含64个samples的数据。另外一方面根据weight_diff = top_diff * bottom_data(即该层输出对于输入的偏导,链式法则)。整个求取梯度的运算也是可以转化为矩阵运算的,这里caffe也是用一次矩阵运算计算对所有权值参数的梯度,caffe的矩阵构造如下:
- relu layer:
这一层是inner product layer的激活函数层,caffe把每层网络的加权求和和激活函数分成两层网络来对待,在这层函数里面由于没有权值和偏置,所以我们也只是需要对输入数据求取梯度即可。而由于激活函数采用的是relu函数,所以对输入求取梯度也比较简单,我们利用的结果就是softmax with loss layer层求取的梯度结果进行链式求导的,程序如下:-
if (propagate_down[0]) { -
const Dtype* bottom_data = bottom[0]->cpu_data(); -
const Dtype* top_diff = top[0]->cpu_diff(); -
Dtype* bottom_diff = bottom[0]->mutable_cpu_diff(); -
const int count = bottom[0]->count(); -
Dtype negative_slope = this->layer_param_.relu_param().negative_slope(); -
for (int i = 0; i < count; ++i) { -
bottom_diff[i] = top_diff[i] * ((bottom_data[i] > 0) -
+ negative_slope * (bottom_data[i] <= 0)); -
} -
}
-
- inner product layer:
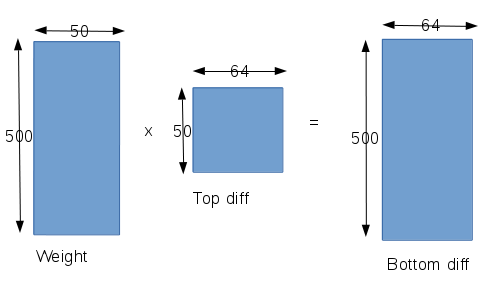
这一层和前面说的类似,也是一个全连接层,要分别对权值,偏置,输入分别求取梯度,其中对输入参数的梯度会反向传播到前一层。- 对权值的梯度:和前面分析类似,该层的输入宽度是800,输出数据宽度是500,所以权值参数共有800x500个。而每个权值又回涉及到一个batch中的所有的64个输入样本,所以caffe对权值梯度的矩阵构造如下:
- 对输入数据的梯度:输入总共有64个样本,每个样本的宽度是800,所以对输入数据的梯度也是64x800,而由于网络是全连接,所以每个输入数据又会和该层所有500个神经元连接,所以每个输入数据都会和500个权值有联系,所以对单个输入数据求梯度就会设计500个权值,所以在caffe中矩阵构造如下:
- 对权值的梯度:和前面分析类似,该层的输入宽度是800,输出数据宽度是500,所以权值参数共有800x500个。而每个权值又回涉及到一个batch中的所有的64个输入样本,所以caffe对权值梯度的矩阵构造如下:
- pooling layer:
下采样层根据下采样方式的不同,求取梯度的方式也不同,对于pooling层,只需要对输入参数求梯度即可,poling层是没有权值和偏置参数的。然后再把梯度反向传播给前一层。在lenet中,pooling层采用的下采样方法是PoolingParameter_PoolMethod_MAX,即在pooling核区域选取一个最大值作为下采样的像素值。那么对于输入求取梯度就很容易了,即对输入的梯度其实就是输出梯度中对应位置的梯度。关于这个位置信息是在forward过程中存储起来的。 - convlution layer:
卷积层包含权值参数,偏置参数,所有对卷积层的梯度计算包含计算对权值的梯度,对偏置的梯度,对输入参数的梯度,同样对输入参数的梯度也会反向传播到前一层中。- 对权值参数的梯度:在该层卷积层上,卷积核的大小是5x5,总共有50个卷积核,所以权值参数共有50x25个。输入数据宽度是20x12x12,输出数据宽度是50x8x8。所以对于一个卷积核卷积一幅图像,每一个卷积参数就会和8x8=64个输入相乘,而同时有20幅图像和该卷积核相连接,所以对于一个样本,一个卷积核中的一个权值参数就会和20x8x8的输入相乘;而一个batch中又有64个样本,所以一个权值参数总共和64x20x8x8个输入相乘。这时如果想一次求取所有对权值参数的梯度就比较困难,caffe中是逐样本对权值参数求梯度。然后再把所有的样本中的对于权值的梯度相加。对于单个样本caffe构造的矩阵如下图所示:
从上图我们发现一个问题,就是该层权值参数总共有50x25个,为何Weight diff却是50x500呢,难道实际上权值参数有50x500个吗,原因还要从farword过程中的卷积矩阵开始说起,在forward过程中,我们想一次把一个卷积核卷积20个不同的输入都计算出来,那么在矩阵相乘的时候,我们就需要把卷积核的参数复制20个,然后完成矩阵相乘,500其实就表示20个相同的5x5卷积核的权值参数。另外上面的计算过程要循环64次,对应一个batch中的64个样本。 - 对输入的梯度:由于该层有50个卷积核,而且卷积核和输入也是全连接的,所以每一个输入都会被50个卷积核的卷积涉及到。所以对于每一个输入梯度的计算都会涉及50个卷积核的对应权值参数,caffe构造的矩阵如下:
对于Bottom diff的数据宽度500情况和上面类似,就是该层的输入其实是20x12x12,而卷积核大小是5x5,所以对于20个输入每一个位置的卷积,都会有20x25=500个数据参与卷积。64和输出尺寸8x8对应,表示在12x12的输入上移动了8x8次,即一张输入上卷积了64次。
- 对权值参数的梯度:在该层卷积层上,卷积核的大小是5x5,总共有50个卷积核,所以权值参数共有50x25个。输入数据宽度是20x12x12,输出数据宽度是50x8x8。所以对于一个卷积核卷积一幅图像,每一个卷积参数就会和8x8=64个输入相乘,而同时有20幅图像和该卷积核相连接,所以对于一个样本,一个卷积核中的一个权值参数就会和20x8x8的输入相乘;而一个batch中又有64个样本,所以一个权值参数总共和64x20x8x8个输入相乘。这时如果想一次求取所有对权值参数的梯度就比较困难,caffe中是逐样本对权值参数求梯度。然后再把所有的样本中的对于权值的梯度相加。对于单个样本caffe构造的矩阵如下图所示:
- pooling layer:
这一层和上面类似,这里不再介绍。 - convolution layer:
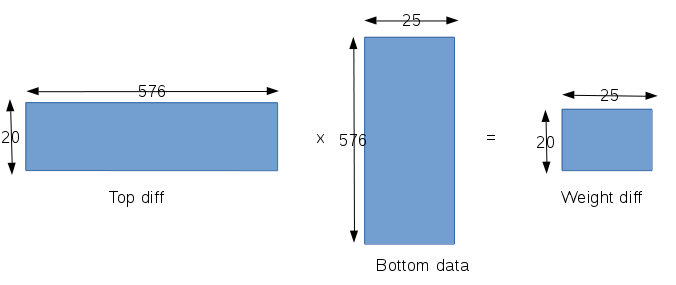
该层是对原始输入数据做第一次卷积,所以这里只对权值参数和偏置参数计算梯度,而输入参数就不用计算梯度了,因为这已经是第一层,输入是原始像素了,所以也就不需要进行反向传播了。该层的输入是28x28的原始像素,输出是20个24x24的卷积后的图像,卷积核的大小是5x5。- 该层的权值参数共有20x25个,类似,每一个权值参数都会涉及到24x24=576个数据,所以在caffe中矩阵的构造如下:
有关偏置梯度的计算都没有写出来,偏置梯度的计算本身也不复杂,就没有必要写了。计算完每个参数的梯度之后,下面就是利用梯度对参数进行更新了,这也是深度学习中很重要的一部分,在以后的文章中回重点总结。
- 该层的权值参数共有20x25个,类似,每一个权值参数都会涉及到24x24=576个数据,所以在caffe中矩阵的构造如下: