大数据流式计算第一课—从Storm开始
## **前言** ##
大数据(Big Data)又称为巨量资料,指需要新处理模式才能具有更强的决策力、洞察力和流程优化能力的海量、高增长率和多样化的信息资产。“大数据”概念最早由维克托·迈尔·舍恩伯格和肯尼斯·库克耶在编写《大数据时代》中提出,指不用随机分析法(抽样调查)的捷径,而是采用所有数据进行分析处理。大数据有4V特点,即Volume(大量)、Velocity(高速)、Variety(多样)、Value(价值)——来自互动百科
这几天在老师指导下,开始对大数据流式计算进行初步接触了。因为结合着目前大数据发展方向以及常见问题,选择了研究大数据分布式计算中的实时数据处理方面的内容,有别于基于Hadoop等引领的大数据批量计算,在此主要应用Storm来分析其不能解决的流式计算问题(主要考虑数据的实时性问题)。
流式大数据的主要特征有:
- 实时性
- 易失性
- 无序性
- 突发性
- 无限性
普遍的研究问题无非是,找到一个“低延迟、高吞吐、持续稳定性、弹性可伸缩”的理想模型,在这个基础上优化各层结构或者算法实现,来实现正确或者是说更加优化的、合理的流式计算结果。当然,大数据分析计算本来就是通过分析和计算数据,获取大数据得来的价值所在。
Storm采用主从式的系统架构,是一个免费开源、分布式、高容错的实时计算系统。介绍可参考:[参考](http://xiaoxin2009.github.io/storm--%E6%9C%80%E7%81%AB%E7%9A%84%E6%B5%81%E5%BC%8F%E5%88%86%E5%B8%83%E5%BC%8F%E7%B3%BB%E7%BB%9F.html%20%E2%80%9C%E5%8F%82%E8%80%83%E2%80%9D)
## Storm 环境搭建##
在了解了基本的Storm系统结构及其组件后,我花了几天时间反复在自己的PC机上倒腾,最后总算勉强搭建好了Storm的基本环境了。Storm系统涉及到本地和集群模式,这里是安装本地示例(单机版)。
首先我的电脑是win10系统,而由于前期学习开发Android及Java等,配置好了java环境。当时的jdk版本为1.8版本的,而后来在网上各种博客或者网站上逛完之后,发现Storm环境很有可能不兼容jdk1.8及以上的,只有1.7(含)版本以下才可。老师一开始告诉说,我也发现现在Storm集群环境基本上是全平台兼容的,但无奈Windows环境的各种环境变量太过麻烦,尝试过多次之后选择了在虚拟机中Linux系统中搭载该环境了。我这里用的是CentOS 7版本的,若有其他版本的系统自行斟酌,大同小异而已。
特别说明:这里列出两种系统环境下搭建Storm环境的参考方法,也感谢两位的博客。
win环境下搭载Storm
CentOS环境下搭载Storm
需要安装的包及工具
- CentOS 7
- JDK 1.7
- Storm 0.9.6
- Zookeeper 3.4.9
- Python 2.7 (CentOS 7默认安装)
## 安装java环境 ##
CentOS 7中默认已经安装好了jdk是1.6及1.7,为了区别其默认安装的是jdk还是jre,这里在终端中继续使用yum命令安装(普通用户登录即可)
sudo yum install java-1.7.0-openjdk java-1.7.0-openjdk-devel默认安装在:/usr/lib/jvm/java-1.7.0-openjdk. 然后我们配置一下JAVA_HOME环境变量,这里显然比win下要方便的多:
vim ~/.bashrc更改最后一行加入代码:
export JAVA_HOME=/usr/lib/jvm/java-1.7.0-openjdk如下保存即可:

接着在终端实现效果,输入:
source ~/.bashrc至此Java环境配置完毕,可以输入用 “java –verion”检查。

## 安装Zookeeper ##
进入Apache官网可以下载Zookeeper的官方安装包(Zookeeper -3.4.9.tar.gz):
http://mirrors.cnnic.cn/apache/zookeeper/stable/
直接在CentOS系统下载,下载后默认保存,执行如下命令(此处切换回root用户,切记!!!):
sudo tar -zxf ~/下载/zookeeper-3.4.9.tar.gz -C -/usr/local ##若有别的版本(如3.4.8)将名字对应更换即可
cd /usr/local
sudo mv zookeeper-* zookeeper
sudo chown -R (括号这里输入你的系统普通用户名即可) ./zookeeper 然后切换回普通用户,执行:
cd /usr/local/zookeeper
mkdir tmp
cp ./conf/zoo_sample.cfg ./conf/zoo.cfg
vim ./conf/zoo.cfg我们在这里将文档当中的 dataDir=/tmp/zookeeper 路径更改为 dataDir=/usr/local/zookeeper/tmp .
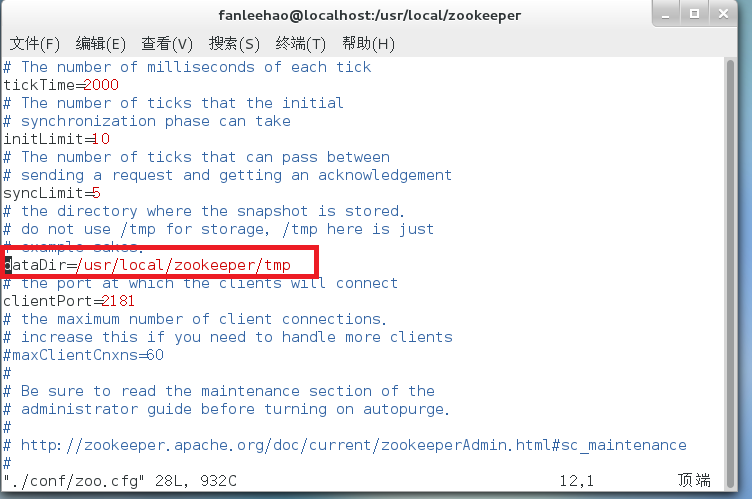
接着执行:
./bin/zkServer.sh start如果出现如下界面,则表示配置成功:

## 安装Storm ##
我们下载并安装Storm,下载地址:
http://www.apache.org/dyn/closer.lua/storm/apache-storm-0.9.6/apache-storm-0.9.6.tar.gz。
下载后执行如下命令进行安装Storm(此处切换回root用户):
sudo tar -zxf ~/下载/apache-storm-0.9.6.tar.gz -C /usr/local
cd /usr/local
sudo mv apache-storm-0.9.6 storm
sudo chown -R (括号这里填系统的普通用户名即可) ./storm #此命令为文件授权 接着配置Storm(切换回普通用户):
cd /usr/local/storm
vim ./conf/storm.yaml打开文档后,修改其中的 storm.zookeeper.servers 和 nimbus.host 两项,取消掉注释且都修改值为 127.0.0.1,如下:

配置完成后,输入命令启动Storm。先启动 nimbus 后台进程:
./bin/storm nimbus效果:

再打开另一个终端,执行 supervisor 后台进程:
/usr/local/storm/bin/storm supervisor效果:

此命令启动后,终端也将被占用。我们用 jps 命令在另一个终端中来检查是否成功启动,若成功则如下图效果。(QuorumPeeMain 是 zookeeper 的后台进程,若显示 config_value 表明 nimbus 或 supervisor 还在启动中):

至此,本地Storm环境已经搭建完毕!
Storm环境搭建好以后,就可以执行一些经典实例了,而今后的进一步课题研究也将从这里开始,这里就不再赘述了,自行寻找在Linux上运行Storm的方式方法。
参考来源: