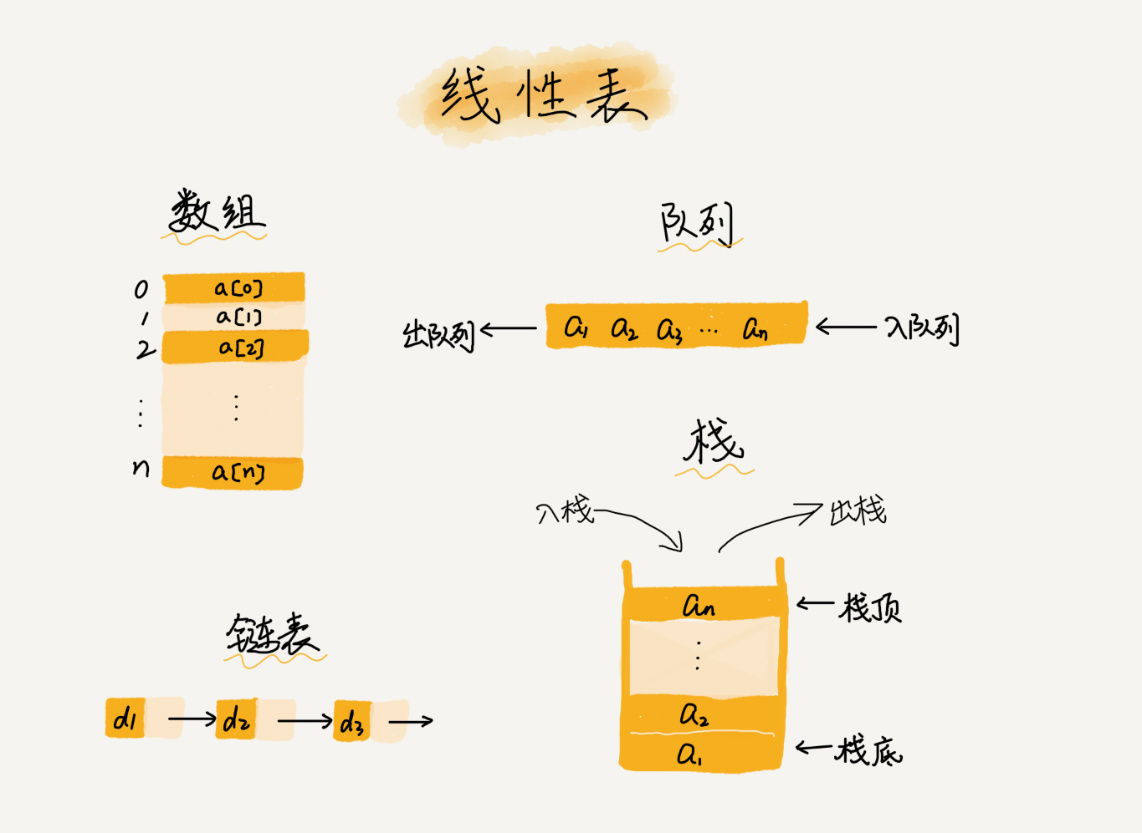
线性表,就像一条线连在一起的结构,每个线性表的数据最多有前后两个方向。常用的数组,链表,栈等都是线性表结构(图片使用王争老师的)
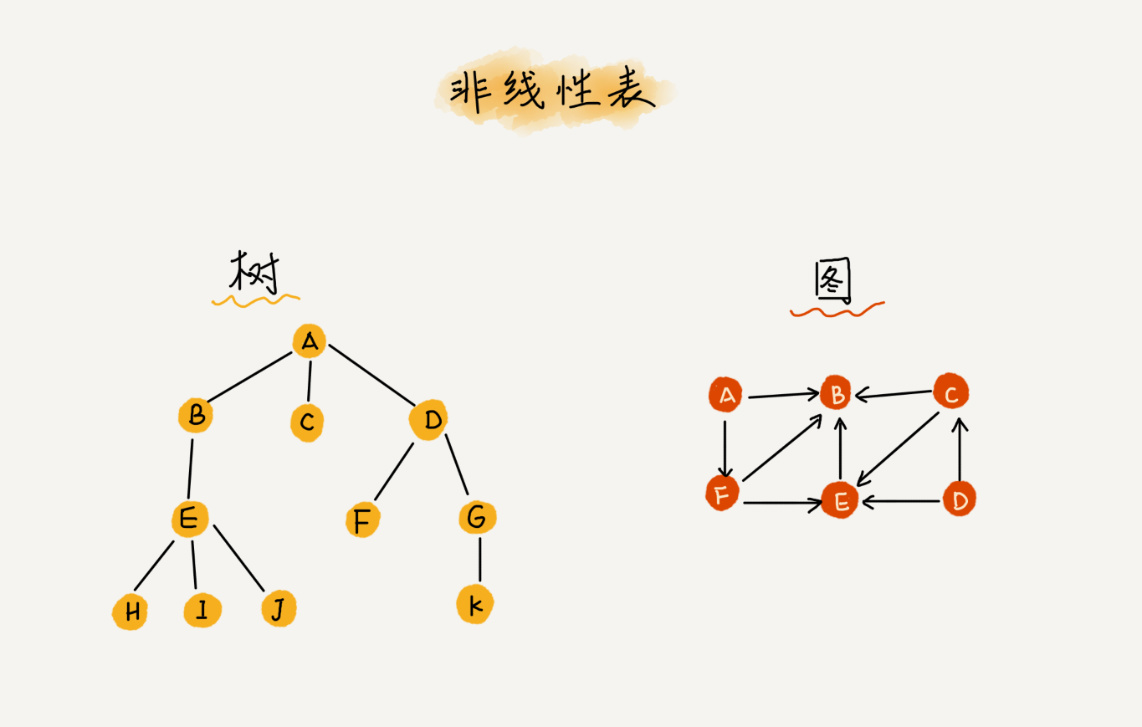
而与它相对立的非线性表,如二叉树,堆,图等,是因为在非线性表中,数据之间不是简单的前后关系。
数组的连续内存空间及相同数据类型,使其可以随机访问高效,可以通过下标直接访问到指定的数据。
公式是:
a[i]_address = base_address + i * data_type_size其中 data_type_size 表示数组中每个元素的大小,比如int 占用4个字节,那么data_type_size就是4字节
base_address是这个数组的内存首地址。
数组由于内存结构连续并且定长,为了保证他的连续性,插入,删除操作时低效(主要他要拷贝操作后的数据到一个新的数组,所以数组越大时间复杂度越高O(n));随意访问高效O(1)。
而我们常用的arraylist,之所以我们不关心他的容量问题是底层帮我们实现了扩容 ,到达arraylist容量上限会自动扩容1.5倍。
二维数组的寻址公式为:
对于 n*m 大小二维数组
a[i][j] i<n,j<m
a[i][j] = base_address + (i * m + j) * data_type_size数组的删除及插入也不是全部O(n),我们可以用一些优化方案
如果数组大小为n
插入优化
1. 如果数组无序,你要在第k位插入,如果k为首位复杂度就是O(n),如果k为末位,复杂度为O(1)
如果k为首位:数组本来就无序,我们可以把原来首位数据加到数组尾部,把要插入首位数据插到首位,这样时间复杂度立马变成O(1),插入其他位置雷同
但是如果数组有序,这就没有办法了,平均时间复杂度就是O(n)
删除优化
2. 我们现在要删除数组前三位数据,这样每一次的删除到会导致数组所有数据位置前移一位,时间复杂度O(n),
但是如果每次删除先不进行操作,而是先做一个标记删除,等积累到一定量的时候统一删除,这样多次O(n)就变成一个O(n)大大提高了操作效率(其实hbase delete也是相同思想,删除时墓碑标记,而执行大合并时才真正的进行删除操作;JVM的标记清楚算法也是同理)