前面的几篇我们了解了爬虫的大致过程
源码下载 + 数据解析 + 数据保存
对应粘贴了 requests、BeautifulSoup、re 的介绍连接、演示了利用 pymysql 模块连接并保存到 MySQL 的过程
但在下载源码中会遇到各种问题,这次来讲最简单的反爬策略:UA禁止
UA(User-Agent)是什么?
User-Agent:翻译是用户代理,其实就是用户的身份
当用浏览器随便访问一个网站时(chrome为例)
通过开发者工具-->network,选择一个请求的Headers,查看 Request Headers 的 User-Agent

可以看出后面跟了些浏览器的名字
这就代表了 用户的身份是浏览器
爬虫的UA有什么问题?
先说一个工具网站:http://httpbin.org/get
扫描二维码关注公众号,回复:
3264189 查看本文章

这个网站直接返回请求头信息
用浏览器打开时User-Agent是这样的,后面是浏览器信息

下面我们用爬虫来访问
# 导入requests请求模块
import requests
# 要访问的网站的链接
# http://httpbin.org/get是个工具网站,直接返回请求头的信息
url = 'http://httpbin.org/get'
# 用get()方法访问得到一个Response对象
response = requests.get(url)
# 打印返回内容
print(response.text)
结果是这样:
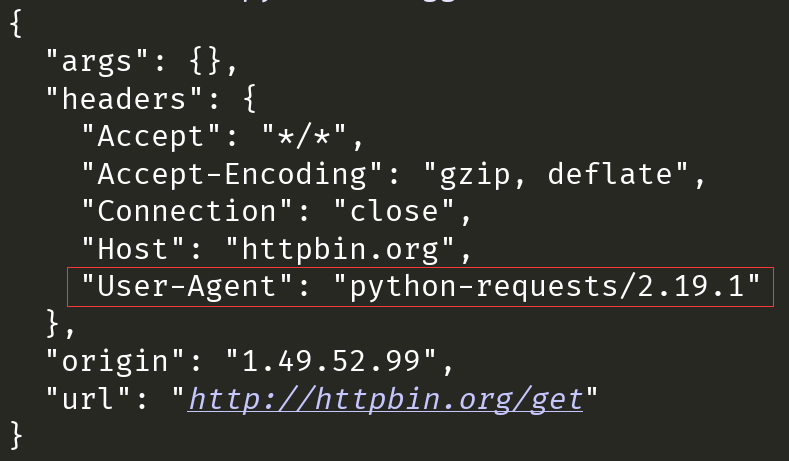
发现了吗?python代码特别 傻,直接告诉人家 自己是个爬虫
很多网站监测到是个爬虫在访问,就会禁止
比如 知乎
我们尝试用爬虫访问
# 导入requests请求模块
import requests
# 要访问的网站的链接
url = 'https://www.zhihu.com/'
# 用get()方法访问得到一个Response对象
response = requests.get(url)
# 打印返回内容
print(response.text)结果如下:

很明显这不是我们想要的源码,还直接给错误码 400
所以遇到 400 就要考虑是不是爬虫被禁了
怎么解决?
既然网站是通过 User-Agent 辨认身份的,那我们将 User-Agent 改成浏览器就行了
通过修改 UA 把爬虫伪装成浏览器,就是 UA 伪装了
我们通过编写请求头headers,将浏览器的 User-Agent 粘贴过来
# 导入requests请求模块
import requests
# 要访问的网站的链接
url = 'https://www.zhihu.com/'
# 自己编写请求头
headers = {
'User-Agent': '"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36'
}
# 用get()方法,headers参数是请求头
response = requests.get(url, headers=headers)
# 打印返回内容
print(response.text)结果就没有 400 了