除了上篇文章(https://blog.csdn.net/Jeeson_Z/article/details/81409730)提到的 UA检测 外
反爬措施还有 IP检测
IP检测
有些网站当检测到同一个IP连续快速访问时,可能会把这个IP拉黑,封锁掉
爬虫的速度贼快,有极大的可能被网站封锁
IP代理
相当于一个 中介
你把请求给他,他帮你安排不同的IP访问,相当于是很多不同的IP在访问,从而避免被封锁
这个 中介 按质量不同,有免费的和收费的
作为案例选取 免费的 66免费代理网(http://www.66ip.cn/)
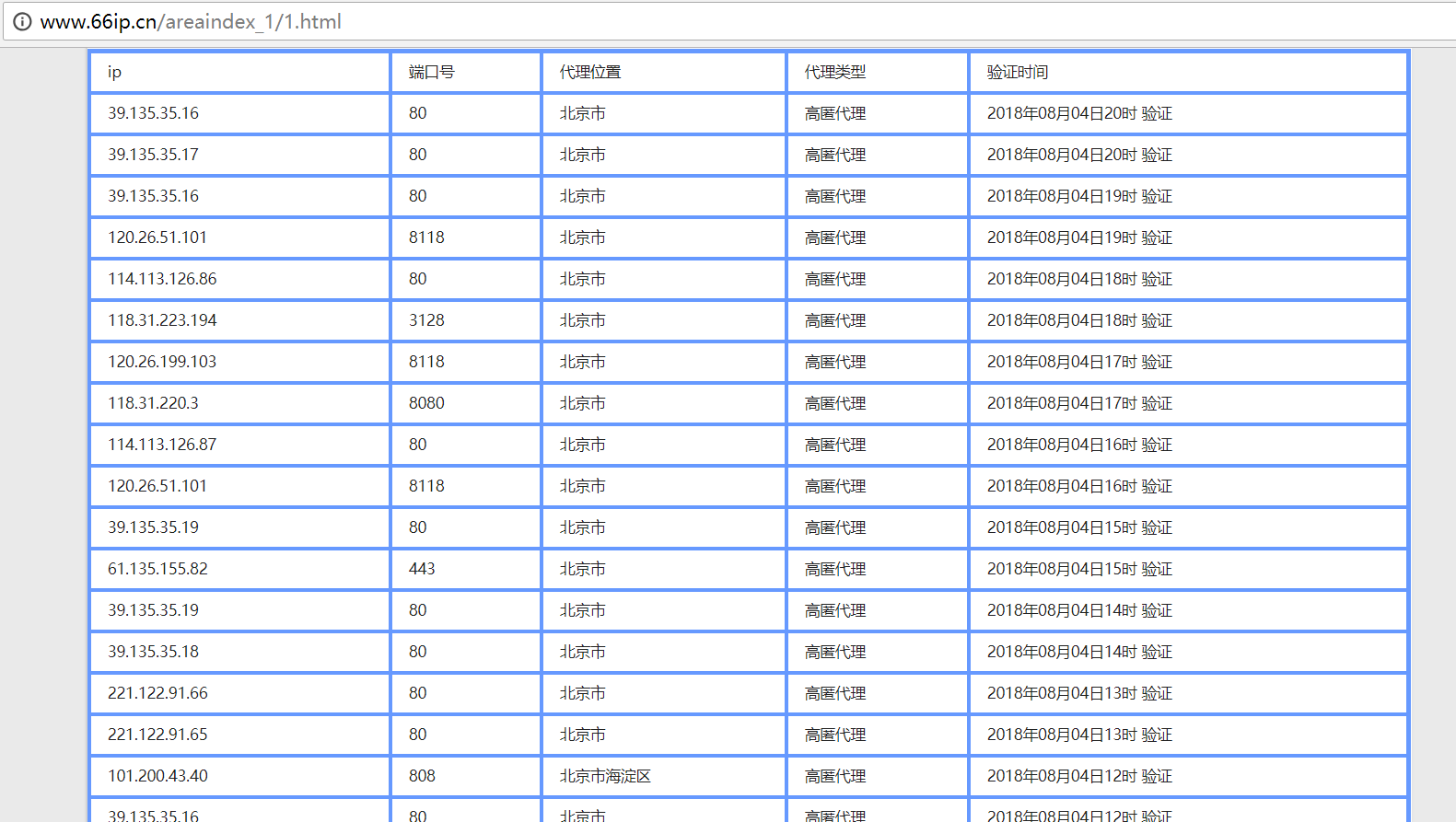
例如选用上表第一条 39.135.35.16:80 作为代理(代理得加上 端口号)
依然访问直接放回请求头的工具网站:http://httpbin.org/get
# 导入requests请求库
import requests
# 要访问的网址
url = 'http://httpbin.org/get'
# 填入代理IP和端口
proxy = '39.135.35.16:80'
# 构造完整的代理链接(url)
proxies = {
# HTTP协议的完整url
# 格式:协议+IP+目录
'http': 'http://' + proxy,
# HTTPS协议简单来说就是HTTP协议的安全版
'https': 'https://' + proxy,
}
# proxies参数设置代理
rsp = requests.get(url, proxies=proxies)
# rsp = requests.get(url)
print(rsp.text)结果如下:(注意:IP可能会不能用,如果不能用,则换一个就好)
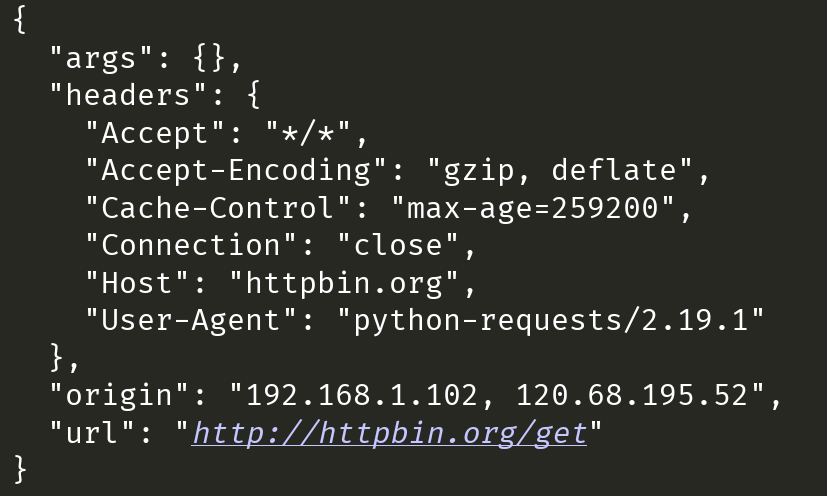
维护IP代理池
一个 IP 代理池首先肯定需要很多 IP 地址,所以第一步是要将代理网站给出的 IP 爬取下来
并不是所有的 IP 都能用,所以要先 测试一下
测试完后 保存到数据库
然后提供一个 接口 方便获取
注意:有些第一次测试不能用但不代表以后不可用,所以我们 为每个IP设置一个分数,代表可用程度
1. 每个 IP 初始分数为 10
2. 如果能用,则为设置为 100
3. 如果不能用,则分数 -1
4. 如果分数为 0 ,则移除
连接数据库
自己先建一个用于存放 IP 的数据库
然后连接到数据库并创建操作游标
# 导入数据库驱动模块 import pymysql # 编写数据库部分 # 一句话连接数据库 db = pymysql.connect(host='localhost', user='root', password='123456xun', db='csdn', charset='utf8mb4') # 利用cursor()方法创建一个操作游标 cursor = db.cursor() # 编写所需要的sql语句 sql_insert = 'INSERT INTO proxy(ip, port, score) VALUES (%s, %s, %s)' sql_delete = 'DELETE FROM proxy WHERE score=0' sql_select = 'SELECT ip,port FROM proxy WHERE score=100'
既然要爬取,就要写爬虫,老规矩
我们按照 下载源码、解析数据、保存数据 三大步来进行爬取
对应的工具分别是用于访问下载的 requests库,用于解析的 BeautifulSoup库、用于保存的 pymysql驱动模块
爬取函数
# 导入requests请求库 import requests # 导入解析库 from bs4 import BeautifulSoup # 编写爬取部分 def crawl_66(): # 代理网站的地址的格式 # 根据观察url,发现各省的代理IP页面由数字控制 # 所以我们先用占位符{}代替这个数字的位置 url = 'http://www.66ip.cn/areaindex_{}/1.html' # 定义用于存放IP的列表 ipes = [] # 共34个省 for page in range(35): # 先填占位符生成一个省的url url = url.format(page) # get()方法访问,得到一个Response对象 rsp = requests.get(url) # Response对象的text属性得到源码 text = rsp.text # 用BeautifulSoup()方法将源码生成能被解析的lxml格式文件 soup = BeautifulSoup(text, 'lxml') # 用find()找放置IP的表 table = soup.find(name='table', attrs={'border': '2px'}) # 用find_all()找到所以的IP ip_list = table.find_all(name='tr') # 循环遍历每个IP for addr in ip_list: # 观察源码发现第一个tr里的内容不是IP,所以跳过 if addr == ip_list[0]: continue # 获取IP ip = addr.find_all(name='td')[0].string # 获取端口 port = addr.find_all(name='td')[1].string # 设置初始分数 init_score = 10 # 利用IP和端口拼接一个代理url proxy_url = 'http://' + ip + ':' + port # 调用检测模块,获取分数 score = test(proxy_url, init_score) # 用一个字典保存一个IP的各种信息 ip_addr = { 'ip': ip, 'port': port, 'score': score, } # 将此条IP添加到IP列表 ipes.append(ip_addr) # 将IP列表返回 return ipes
上面模块调用了检测函数
下面就来写 检测函数 ,以尝试访问百度为例
# 编写检测部分 # 接受代理url和分值 def test(url, init_score): # 如果此条url的分数都被减到0了,就删除它 if init_score == 0: cursor.execute(sql_delete) db.commit() # 以访问百度作为测试 test_url = 'https://www.baidu.com/' # 编写代理url proxy = { 'http': url, } # proxies参数填写代理 rsp = requests.get(test_url, proxies=proxy) # 判断返回码是否等于200,200表示成功 if rsp.status_code == 200: # 成功就把分数设置为100 score = 100 else: # 否则分数减一 score = init_score - 1 # 返回分数 return score
以上代码每次都用requests访问,效率十分低,有兴趣的朋友可以自个琢磨怎么优化
当IP、端口、分数都设置好了以后
就该 保存到数据库 了
# 导入数据库驱动模块 import pymysql # 编写储存部分 def save_ip(): # 从爬取函数获取代理IP信息 ipes = crawl_66() # 遍历每条信息 for ip in ipes: # 赋值并执行mysql保存语句 cursor.execute(sql_insert, (ip['ip'], ip['port'], ip['score'])) # 提交操作 db.commit() # 关闭数据库 db.close()
保存完毕之后,爬虫要怎么使用呢?
这就需要编写一个 接口
# 接口部分 def api(): # 定义一个用于存放IP的列表 proxies = [] # 执行mysql查询语句 cursor.execute(sql_select) # fetchall()方法获取查询结果,返回一个元组 result = cursor.fetchall() # 遍历每条结果 for addr in result: # 获取IP ip = addr[0] # 获取端口 port = addr[1] # 拼接出代理IP的url proxy = { 'http': 'http://' + ip + ':' + port, 'https': 'https://' + ip + ':' + port, } # 将此条代理添加到列表 proxies.append(proxy) # 返回列表 return proxies
这里作为案例就不编写爬虫来调用它了
编写 代码入口
# 代码入口 if __name__ == '__main__': # 从储存函数开始 save_ip()
全部代码
# 导入requests请求库
import requests
# 导入解析库
from bs4 import BeautifulSoup
# 导入数据库驱动模块
import pymysql
# 编写数据库部分
# 一句话连接数据库
db = pymysql.connect(host='localhost', user='root', password='123456xun', db='csdn', charset='utf8mb4')
# 利用cursor()方法创建一个操作游标
cursor = db.cursor()
# 编写所需要的sql语句
sql_insert = 'INSERT INTO proxy(ip, port, score) VALUES (%s, %s, %s)'
sql_delete = 'DELETE FROM proxy WHERE score=0'
sql_select = 'SELECT ip,port FROM proxy WHERE score=100'
# 编写检测部分
# 接受代理url和分值
def test(url, init_score):
# 如果此条url的分数都被减到0了,就删除它
if init_score == 0:
cursor.execute(sql_delete)
db.commit()
# 以访问百度作为测试
test_url = 'https://www.baidu.com/'
# 编写代理url
proxy = {
'http': url,
}
# proxies参数填写代理
rsp = requests.get(test_url, proxies=proxy)
# 判断返回码是否等于200,200表示成功
if rsp.status_code == 200:
# 成功就把分数设置为100
score = 100
else:
# 否则分数减一
score = init_score - 1
# 返回分数
return score
# 编写爬取部分
def crawl_66():
# 代理网站的地址的格式
# 根据观察url,发现各省的代理IP页面由数字控制
# 所以我们先用占位符{}代替这个数字的位置
url = 'http://www.66ip.cn/areaindex_{}/1.html'
# 定义用于存放IP的列表
ipes = []
# 共34个省
for page in range(35):
# 先填占位符生成一个省的url
url = url.format(page)
# get()方法访问,得到一个Response对象
rsp = requests.get(url)
# Response对象的text属性得到源码
text = rsp.text
# 用BeautifulSoup()方法将源码生成能被解析的lxml格式文件
soup = BeautifulSoup(text, 'lxml')
# 用find()找放置IP的表
table = soup.find(name='table', attrs={'border': '2px'})
# 用find_all()找到所以的IP
ip_list = table.find_all(name='tr')
# 循环遍历每个IP
for addr in ip_list:
# 观察源码发现第一个tr里的内容不是IP,所以跳过
if addr == ip_list[0]:
continue
# 获取IP
ip = addr.find_all(name='td')[0].string
# 获取端口
port = addr.find_all(name='td')[1].string
# 设置初始分数
init_score = 10
# 利用IP和端口拼接一个代理url
proxy_url = 'http://' + ip + ':' + port
# 调用检测模块,获取分数
score = test(proxy_url, init_score)
# 用一个字典保存一个IP的各种信息
ip_addr = {
'ip': ip,
'port': port,
'score': score,
}
# 将此条IP添加到IP列表
ipes.append(ip_addr)
# 将IP列表返回
return ipes
# 编写储存部分
def save_ip():
# 从爬取函数获取代理IP信息
ipes = crawl_66()
# 遍历每条信息
for ip in ipes:
# 赋值并执行mysql保存语句
cursor.execute(sql_insert, (ip['ip'], ip['port'], ip['score']))
# 提交操作
db.commit()
# 关闭数据库
db.close()
# 接口部分
def api():
# 定义一个用于存放IP的列表
proxies = []
# 执行mysql查询语句
cursor.execute(sql_select)
# fetchall()方法获取查询结果,返回一个元组
result = cursor.fetchall()
# 遍历每条结果
for addr in result:
# 获取IP
ip = addr[0]
# 获取端口
port = addr[1]
# 拼接出代理IP的url
proxy = {
'http': 'http://' + ip + ':' + port,
'https': 'https://' + ip + ':' + port,
}
# 将此条代理添加到列表
proxies.append(proxy)
# 返回列表
return proxies
# 代码入口
if __name__ == '__main__':
# 从储存函数开始
save_ip()github 地址:https://github.com/JeesonZhang/pythonspider/blob/master/v06.py