导语:在我们使用爬虫时,有些网站会限制每个 IP 的访问速度或访问次数,超出了它的限制IP 就会被封掉,对于访问次数限制的突破,就需要使用代理 IP了,使用多个代理 IP 伪装成不同的用户轮换着去访问目标网址可以有效地解决问题。
目录
代理池架构
必要性
互联网上有大量公开的免费代理,当然我们也可以购买付费代理,但我们如何保证我们的这个代理IP是可用的呢,总不能爬一会出一个代理超时,爬一会因为和别人共用一个代理IP导致被封。一旦选用的是一个不可用的代理ip,势必就会影响爬虫的工作效率。所以要提前做筛选,删除掉不可用的代理,只保留可用代理。 那么怎么实现呢?这就需要借助一个叫代理池的东西了。
功能架构图
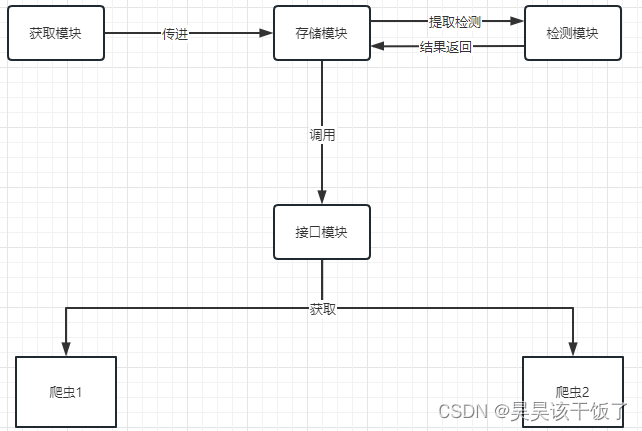
代理池各模块功能
获取模块
功能介绍
负责定时在从代理网站爬取代理。代理既可以是免费公开的,也可以是付费的, 形式上都是处理为 ip + port ,此模块尽量从优质代理处获取,以确保获取高匿代理,我这里使用了天启的优质ip,点这里可以注册,新人会送一千个代理IP的貌似(一般玩玩都够了),获取成功后将可用代理存储到存储模块。
根据需求我们选择好如下配置,生成api链接。 
打开链接是这个样子:

当然了,这个获取模块会实现这个功能,我们看代码。
代码示例
def get_ip():
url = 在天启注册后配置的api
res = requests.get(url)
# print(res.text)
for i in json.loads(res.text)["data"]:
print(i, type(i))
ip = {
"http": str(i["ip"]) + ":" + str(i["port"]),
"https": str(i["ip"]) + ":" + str(i["port"])
}
return ip
注意
我们拿到的代理是 {"ip":"117.57.91.154","port":40021} 这种样子的;
爬虫使用的代理要装成:
{'http': '163.125.104.6:40011', 'https': '163.125.104.6:40011'}
这种样子。
存储模块
功能介绍
存储模块负责存储爬取下来的代理。首先要保证代理不重复,标识代理的可用情况,其次要 动态实时地处理每个代理, 一种比较高效和方便的存储方式就是 Redis 的 Sorted set,即有序集合。
本次以教学为主,我们直接将代理ip放进一个list中即可,需要用的时候直接从列表中获取。
检测模块
功能介绍
负责定时检测存储模块中的代理是否可用。这里需要设置一个检测链接,最好是设置为要爬取的那个网站,这样更具有针对性。而对于一个通用型的代理,可以设置为百度等链接。
另外,需要标识每一个代理的状态,例如设置分数标识,100 分代表可用,分数越少代表越不 可用。经检测,如果代理可用,可以将分数标识立即设置为满分 100,也可以在原分数基础上 加1;如果代理不可用,就将分数标识减 1,当分数减到一定國值后,直接从存储模块中删除此代理。这样就可以标识代理的可用情况,在选用的时候也会更有针对性。
代码示例
在示例中,我们严格要求一些,如果代理ip不可用,就删除,如果代理IP可以使用,就返回
verif = requests.get("http://httpbin.org/ip", proxies=ip, timeout=2)
if verif.status_code == 200 and json.loads(verif.text)["origin"] == i["ip"]:
print("配置成功,返回代理:{0}".format(ip))
return iphttp://httpbin.org/ip 这是一个检测ip的网站,他可以返回你当前的ip地址,我们对这个网址发起一个requests请求,如果状态码是200,同时这个网站返回的是代理IP,就说明这个ip生效了,是有用的。如果状态码不是200,或者返回来的不是代理IP而是本机IP都说明代理未生效。
接口模块
功能介绍
用API提供对外服务的接口。其实我们可以直接连接数据库来获取对应的数据,但这样需要知道数据库的连接信息,并且要配置连接。比较安全和方便的方式是提供一个 Web API 接口,访问这个接口即可拿到可用代理。另外,由于可用代理可能有多个,所以可以设置一个 随机返回某个可用代理的接口,这样就能保证每个可用代理都有机会被获取,实现负载均衡。
对于本次练习来说,我们直接从维护的列表中提取一个元素即可
实战实例
- 访问天启api,获取代理IP信息
- 将返回数据组装成爬虫可用的格式
- 访问网站,测试代理ip是否可用
结果图:

虚拟用户
原理
当我们第一次访问某个网站时,我们是没有任何网站信息或者记录的,这时候我们是作为一个新人来访问这个网站;
当我们第二次访问某个网站时,我们是带着cookies等网站信息或者记录的,这时候我们是作为一个老人来访问这个网站。
说到这里有人应该明白了,我先使用代理ip访问网站,这个时候相当于一个新人,然后把cookies等信息全部保留下来一起存进虚拟用户池中,当我的爬虫项目拿到这个ip的时候,也拿到了这个IP曾经访问目标网站时存下来的cookies,我把ip和cookies一起带着过去,不就相当于是老人了。
话不多说,我们实战一下。
实战实例
# 任意header
head = {
'User-Agent': 'Mozilla/5.0 (Windows; U; Windows NT 6.1; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50',
'Accept-Encoding': 'gzip, deflate',
'Accept': '*/*',
'Connection': 'keep-alive',
'Accept-Language': 'zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2',
'Upgrade-Insecure-Requests': '1',
'Sec-Fetch-Dest': 'document',
'Sec-Fetch-Mode': 'navigate',
'Sec-Fetch-Site': 'none',
'Sec-Fetch-User': '?1'
}
ip = get_ip()
# 将ip信息放入虚拟用户user中
user = {"ip":ip}
print(user)
# 第一次访问百度
res = requests.get("http://www.baidu.com", headers=head, proxies=user["ip"])
#将百度返回的cookies装回user中
user["cookies"] = res.cookies.get_dict()
print(user)
# 第二次带着cookies访问百度
res = requests.get("http://www.baidu.com",
headers=head,
proxies=user["ip"],
cookies=user["cookies"])我们输出这两个user:

可以看到第二次的时候我们已经有了cookies信息。
该方法适用于某些必须要通过首页验证的网站,格外好用,将首页验证的逻辑与代理IP池构建在一起,每一个爬虫任务就不需要访问首页了
—— —— ——
欢迎点赞、收藏、评论区讨论交流
转载标明出处 谢谢 ~