转载请标明出处:http://blog.csdn.net/wuzqchom/article/details/75792501
计划分为三个部分:
浅谈Attention-based Model【原理篇】(你在这里)
浅谈Attention-based Model【源码篇】
浅谈Attention-based Model【实践篇】
0. 前言
看了台大的李宏毅老师关于Attention部分的内容,这一部分讲得挺好的(其实李宏毅老师其它部分的内容也不错,比较幽默,安利一下),记录一下,本博客的大部分内容据来自李宏毅老师的授课资料:Attention-based Model。如发现有误,望不吝赐教。
1. 为什么需要Attention
最基本的seq2seq模型包含一个encoder和一个decoder,通常的做法是将一个输入的句子编码成一个固定大小的state,然后作为decoder的初始状态(当然也可以作为每一时刻的输入),但这样的一个状态对于decoder中的所有时刻都是一样的。
attention即为注意力,人脑在对于的不同部分的注意力是不同的。需要attention的原因是非常直观的,比如,我们期末考试的时候,我们需要老师划重点,划重点的目的就是为了尽量将我们的attention放在这部分的内容上,以期用最少的付出获取尽可能高的分数;再比如我们到一个新的班级,吸引我们attention的是不是颜值比较高的人?普通的模型可以看成所有部分的attention都是一样的,而这里的attention-based model对于不同的部分,重要的程度则不同。
2. Attention-based Model是什么
Attention-based Model其实就是一个相似性的度量,当前的输入与目标状态越相似,那么在当前的输入的权重就会越大,说明当前的输出越依赖于当前的输入。严格来说,Attention并算不上是一种新的model,而仅仅是在以往的模型中加入attention的思想,所以Attention-based Model或者Attention Mechanism是比较合理的叫法,而非Attention Model。
没有attention机制的encoder-decoder结构通常把encoder的最后一个状态作为decoder的输入(可能作为初始化,也可能作为每一时刻的输入),但是encoder的state毕竟是有限的,存储不了太多的信息,对于decoder过程,每一个步骤都和之前的输入都没有关系了,只与这个传入的state有关。attention机制的引入之后,decoder根据时刻的不同,让每一时刻的输入都有所不同。
再引用tensorflow源码attention_decoder()函数关于attention的注释:
“In this context ‘attention’ means that, during decoding, the RNN can look up information in the additional tensor attention_states, and it does this by focusing on a few entries from the tensor.”
3. Attention
对于机器翻译来说,比如我们翻译“机器学习”,在翻译“machine”的时候,我们希望模型更加关注的是“机器”而不是“学习”。那么,就从这个例子开始说吧(以下图片均来自上述课程链接的slides)

刚才说了,attention其实就是一个当前的输入与输出的匹配度。在上图中,即为
和
的匹配度(
为当前时刻RNN的隐层输出向量,而不是原始输入的词向量,
初始化向量,如rnn中的initial memory),其中的match为计算这两个向量的匹配度的模块,出来的
即为由match算出来的相似度。好了,基本上这个就是attention-based model 的attention部分了。那么,match什么呢?
对于“match”, 理论上任何可以计算两个向量的相似度都可以,比如:
- 余弦相似度
- 一个简单的 神经网络,输入为 和 ,输出为
- 或者矩阵变换
(Multiplicative attention,Luong et al., 2015)
现在我们已经由match模块算出了当前输入输出的匹配度,然后我们需要计算当前的输出(实际为decoder端的隐状态)和每一个输入做一次match计算,分别可以得到当前的输出和所有输入的匹配度,由于计算出来并没有归一化,所以我们使用softmax,使其输出时所有权重之和为1。那么和每一个输入的权重都有了(由于下一个输出为“machine”,我们希望第一个权重和第二个权权重越大越好),那么我们可以计算出其加权向量和,作为下一次的输入。
这里有一个问题:就是如果match用后面的两种,那么参数应该怎么学呢?
如下图所示:

那么再算出了 之后,我们就把这个向量作为rnn的输入(如果我们decoder用的是RNN的话),然后d第一个时间点的输出的编码 由 和初始状态 共同决定。我们计算得到 之后,替换之前的 再和每一个输入的encoder的vector计算匹配度,然后softmax,计算向量加权,作为第二时刻的输入……如此循环直至结束。

再看看Grammar as a Foreign Language一文当中的公式:
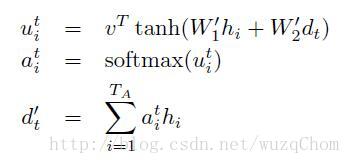
上面的符号表示和前面描述的不太一样,经统一符号的公式如下:
得到
之后,就可以作为第t时刻RNN的input,而
可以作为t时刻RNN的隐状态的输入,这样就能够得到新的隐状态
,如此循环,直到遇到停止符为止。
上式 为一个向量, 即为t时刻的decoder隐状态向量和第i个输入的相似度(未归一化)。
在第一个式子当中的 里面的内容,tensorflow对于第一部分的实现是采用卷积的方式实现,而第二部分使用的是线性映射函数linear实现。
向量的长度即为attention_vec_size,tensorflow 中直接把输入向量的长度设置为attention向量的长度,你要设置其他的值也可以,这里比较奇怪,tensorflow没有将其作为函数的参数,难道设成和输入的向量相同的效果更好?(有知情者也烦请告知)
4. 遗留问题
本来我们已经结束了,但是仔细想想,其实还有一个地方有所疑问。就是加入match是一个简单地神经网络或者一个矩阵,神经网络的权值和矩阵里面的值怎么来?
其实这些都是可以BP的时候就可以自动学到的。比如我们明确输出是什么,在第一时刻的时候,那就会调整
和
的值,进而就会调整所有的
值,之前说过
是match的输出,如果match是后两种的话,就会进而调整match中的参数。
文本处理方面的注意力机制是在神经机器翻译首先提出,附文献:
DzmitryBahdanau,KyunghyunCho,andYoshuaBengio.Neuralmachinetranslationbyjointlylearning to align and translate. arXiv preprint arXiv:1409.0473, 2014.