文章目录
Redis 原理篇
简介:
- redis是纯内存操作,读写速度快
- 核心业务是单线程模型,基于IO多路复用和事件派发
- 可通过两种持久化方式将信息存储到磁盘
由于版本的更迭,6.0版本开始引入多线程,但核心业务还是单线程
为什么核心业务不引入多线程:
- redis是纯内存操作,实际上影响性能的是网络延迟问题,是IO问题
- 引入多线程,频繁的上下文切换可能反而会消耗资源
- 多线程的机制原因,可能会带来安全性问题,必然要引入锁这样的安全手段
IO 模型
在说明redis所使用的IO模型之前,先介绍说明所有IO模型
推荐一个B站上的原理篇视频原理篇-27.Redis网络模型-Redis单线程及多线程网络模型变更_哔哩哔哩_bilibili
以下图片均来自视频截图
一次I/O涉及到两个状态:用户态、内核态
在设备上的表现:等待硬件设备的数据就绪 -> 数据存于内核缓冲区 ->数据从内核缓冲区拷贝到用户缓冲区
经历两个阶段:
- 等待数据就绪
- 将数据从内核缓冲区拷贝到用户缓冲区
-
BIO 阻塞IO: 两个阶段都会阻塞,一直等到数据就绪且数据拷贝完成才会停止阻塞去处理数据
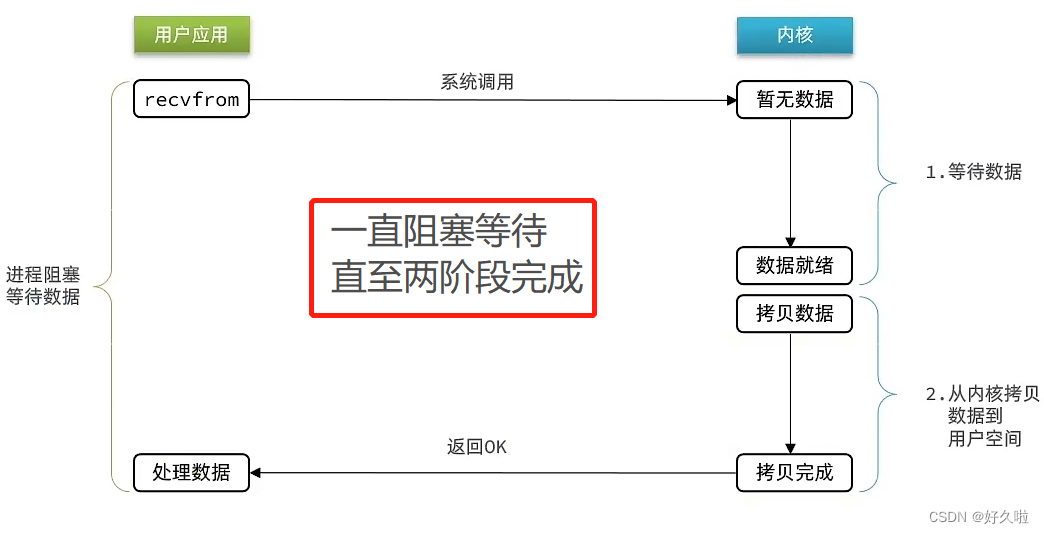
-
NIO 非阻塞IO:第一个阶段不断地轮询数据是否已经就绪,相比阻塞IO,第一个阶段不阻塞;第二个阶段仍然是阻塞等待状态
- 虽然第一个阶段是非阻塞,但没有提高性能,轮询机制会导致CPU空转,浪费CPU资源
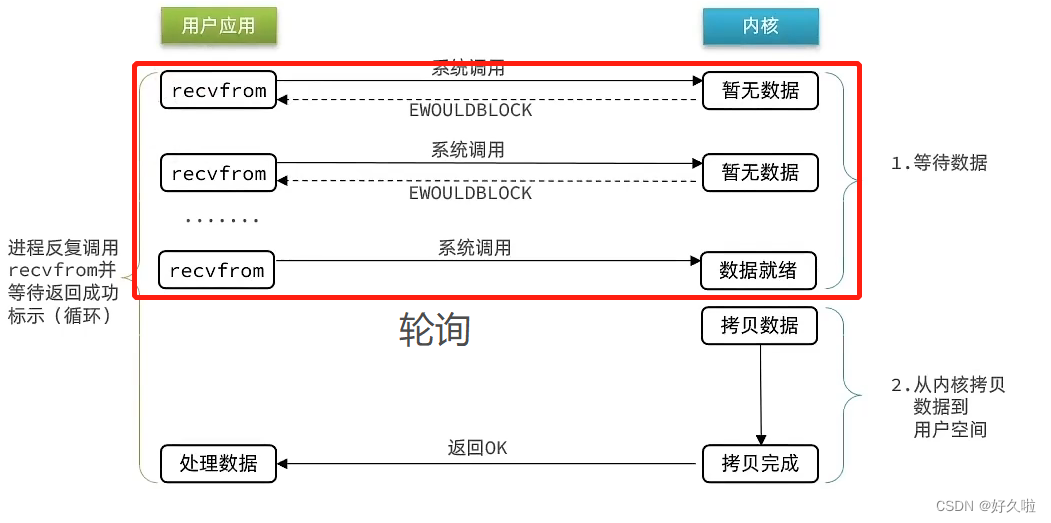
阻塞IO和非阻塞IO其实差别在于无数据时地处理方案 ,在单线程情况下,如果正在处理的正好数据未就绪,线程就会阻塞。
IO多路复用与以上两种模型的差别在于去监听数据是否在已经就绪,从而去避免无效的等待
- IO多路复用模型 :监听多个文件描述符FD(是对所有文件的唯一标识),一旦检测到有FD数据已就绪,再去进行第二个阶段,第二个阶段仍然是阻塞状态;多路可以理解为多个FD, 复用即复用一个线程
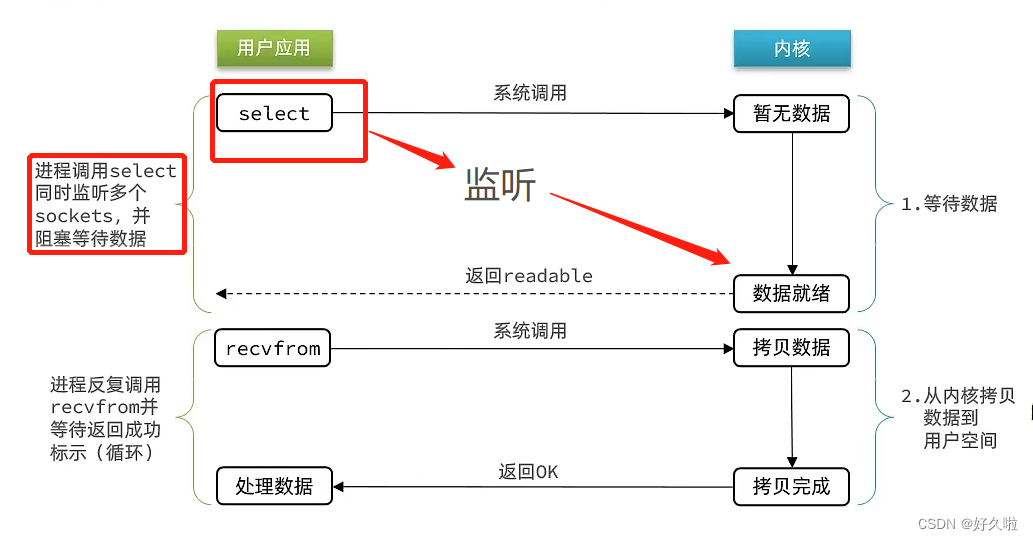
IO多路复用实际上有三种实现方案
-
1.1 select :
- 在用户空间使用到了长度为1024的bitmap数据结构,对要监听的FD对应的比特位进行置1,bitmap拷贝到内核空间,由内核空间去监听是否有数据就绪
- 当有数据就绪时,会去遍历所有的FD查看是哪个FD数据就绪并将数据未就绪的FD的bit位置0,返回一个就绪FD数量,同时还有一个另外的操作:bitmap会从内核空间拷贝到用户空间;没有则返回结果0
- 用户空间根据返回的结果数量,去遍历bitmap,得到FD,进行数据读取
- 总结:O(N)的无差别轮询复杂度,能够知道有IO事件发生,但不知道是哪些FD;且bitmap共1024个bit位,因此监听数量有限不能超过1024;select结束,数据还要从内核空间拷贝到用户空间
-
1.2 poll :
- 大致与select流程一样,只是bitmap的长度可自定义,解决了连接数量问题
- 仍存在两次数据拷贝,且只知道有数据就绪,不知道是哪个,需要在用户空间再遍历一次;如果监听较多返回可能会导致性能下降
-
1.3 epoll :
-
epoll 基于红黑树和链表,不需要在用户空间遍历,时间复杂度O(1)
-
提供了三个函数
-
epoll_create :创建一个结构体,含记录要监听FD的红黑树和记录就绪FD的链表
-
epoll_ctl :将一个FD添加到红黑树,关联回调函数callback,当数据就绪时,就会把相应的FD加入到就绪链表
-
epoll_wait :检查就绪链表是否为空,不为空返回就绪的FD数量,同时会将就绪链表拷贝到用户空间;即返回的FD集合是就绪的集合,不需要用户空间去遍历检测
两种触发模式:
LT :
当 epoll_wait() 检测到描述符事件到达时,将此事件通知进程,进程可以不立即处理该事件,下次调用 epoll_wait() 会再次通知进程,是默认的一种模式。
ET :
和 LT 模式不同的是,通知之后进程必须立即处理事件。
下次再调用 epoll_wait() 时不会再得到事件到达的通知。很大程度上减少了 epoll 事件被重复触发的次数,
因此效率要比 LT 模式高,避免由于一个文件句柄的阻塞读/阻塞写操作把处理多个文件描述符的任务饿死
-
-
总结:减少拷贝次数,即不需要每次epoll_wait都要去拷贝FD集合,因为要监听的FD在内核中的红黑树(当有新的FD要监听时,调用epoll_ctl添加到红黑树上);只是将就绪的FD集合拷贝到用户空间,不需要用户空间去遍历所有FD来判断就绪状态;基于红黑树保存的FD,理论上无上限,CRUD效率高,且性能不会受FD数量影响
优化:数据就绪交由内核判断,减少NIO中内核<->用户的切换
-
-
信号驱动模型
- 与内核及建立信号的关联并设置回调,当内核有FD就绪时,会回调通知用户,期间用户可以执行其他业务,无需阻塞等待
- 第一个
- 大量IO操作时,信号较多,不能及时处理可能会导致信号队列溢出
-
AIO 异步IO
- 系统调用,立即响应返回结果表明已知晓,当前进程不需要等待事件处理结果,可以继续执行其他事务
- 两个阶段都不会阻塞
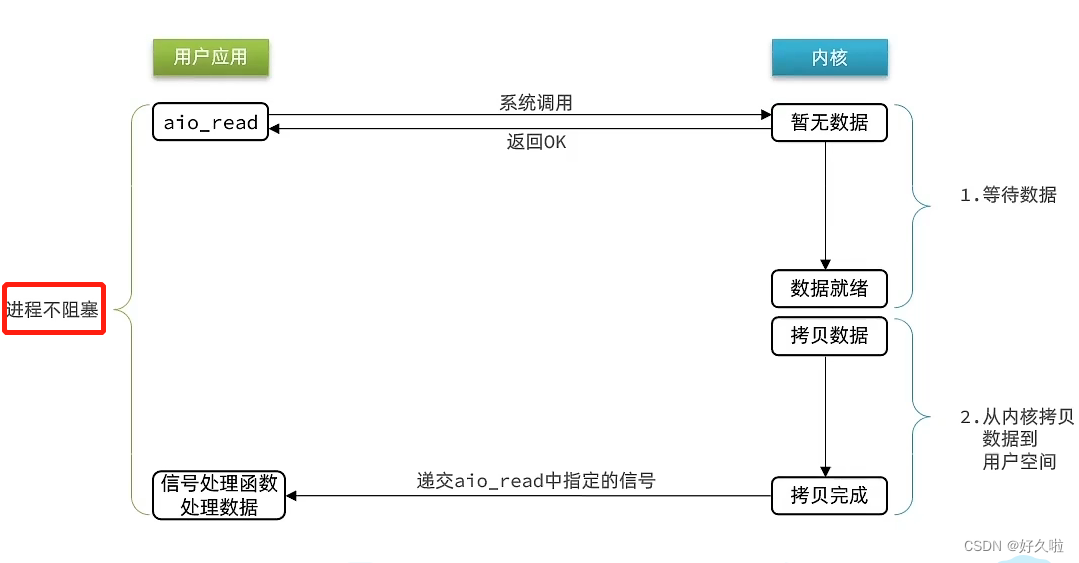
同步与异步区分:从内核空间到用户空间的拷贝过程是否阻塞
以JAVA网络套接字socket来谈 IO模型
-
BIO
- 单线程情况下,首先accpet阻塞等待客户端连接,其次有客户端连接之后,read阻塞,需要等待客户端发送信息; 如果连接的客户端一直没有发送信息,就会一直占用连接,其他客户端无法连接。
- 多线程情况下,同样accpet阻塞等待客户端连接,在有客户端连接之后,thread一个线程去读取客户端发送的信息;如果有大量的连接,那么就会开辟大量的线程,很可能连接的客户端并不发送信息,造成了资源的浪费。
-
NIO
- accpet不阻塞,轮询等待客户端连接,将连接的客户端放进list列表,每次轮询都要遍历一次list列表查看是否有客户端发送信息
- 如果1w个连接当中只有一个连接发送信息,那么有9999次是无意义的;在遍历上消耗了很多无用的时间
-
IO 多路复用
- accpet不阻塞,交由系统调用,如果有客户端发送信息则返回
- 以select为例,每次轮询都会将客户端连接list复制一份到内核,由内核来帮我们判断是否有客户端发送信息,有则返回
Redis 网络模型
-
两种身份:客户端 & 服务器
-
两种socket :ServerSocket 、ClientSocket
-
三种处理器:
- 连接应答:即有新的客户端连接服务器
- 命令请求(读)
- 命令回复(写):命令执行结果
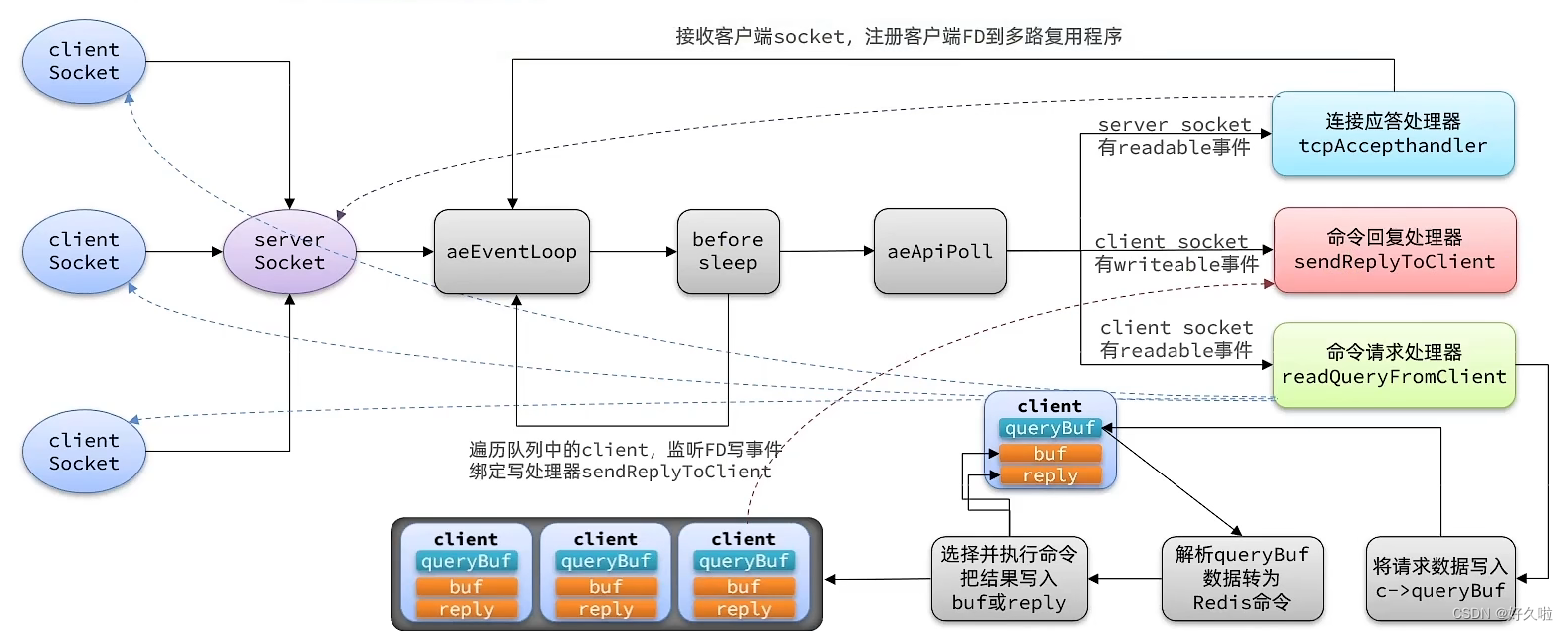
上图同样来源于视频截图
当我们在服务器中创建了redis服务之后,启动服务
-
创建事件结构体,类似于epoll_create
-
连接服务器,创建ServerSocket,获取对应的FD添加到事件实例,并绑定连接应答处理器,类似于epoll_ctl
- 当有客户端连接服务器时,ServerSocket绑定的连接应答处理器处理流程:获取连接的客户端的FD添加到事件实例,并绑定命令请求处理器,同样类似于epoll_ctl
- 监听是否含有就绪ClientSocket,当有就绪ClientSocket时,其绑定的命令请求处理器:将请求数据写入缓冲区,之后会解析缓冲区的数据转为redis命令,选择并执行命令把结果放入缓冲区;同时将该socket所属的缓冲区放入输出缓冲区队列中
-
在监听FD前,beforesleep作用在于遍历输出结果队列中的Clientsocket,监听FD写事件,并绑定命令回复处理器;在监听开始之后如果一直没有就绪ClientSocket,若设置了超时时间time_out会进入休眠因此在epoll_wait之前进行
-
监听事件,类似于epoll_wait
总结:redis的核心业务就是IO多路复用+事件派发,监听的是ServerSocket连接事件、ClientSocket读事件、ClientSocket事件,根据不同的事件去绑定不同的事件处理器,对应不同的处理流程
以上是单线程情况下,而后redis加入多线程版本,主要是针对IO问题引入了多线程
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-4q1QCrqu-1660977871407)(C:\Users\蔡晓娜\AppData\Roaming\Typora\typora-user-images\image-20220820143500094.png)]](https://img-blog.csdnimg.cn/a806dd4566804ccb983ca04024507269.png)