字符与字节的区别(查阅引用)
①ASCII码中,一个英文字母(不分大小写)占一个字节的空间,一个中文汉字占两个字节的空间。一个二进制数字序列,在计算机中作为一个数字单元,一般为8位二进制数,换算为十进制。最小值0,最大值255。
②UTF-8编码中,一个英文字符等于一个字节,一个中文(含繁体)等于三个字节。
③Unicode编码中,一个英文等于两个字节,一个中文(含繁体)等于两个字节。
符号:英文标点占一个字节,中文标点占两个字节。举例:英文句号“.”占1个字节的大小,中文句号“。”占2个字节的大小。
④UTF-16编码中,一个英文字母字符或一个汉字字符存储都需要2个字节(Unicode扩展区的一些汉字存储需要4个字节)。
⑤UTF-32编码中,世界上任何字符的存储都需要4个字节。
字节(Byte)是一种计量单位,表示数据量多少,它是计算机信息技术用于计量存储容量的一种计量单位。
字符是指计算机中使用的文字和符号,比如1、2、3、A、B、C、~!·#¥%……—*()——+、等等。
存数据时的区别
char定义的是固定长度,长度范围为0-255,存储时,如果字符数没有达到定义的位数,会在后面用空格补全存入数据库中。char最多能存放255个字符个数,和编码无关。
varchar是变长长度,长度范围为0-65535,存储时,如果字符没有达到定义的位数,也不会在后面补空格。对于varchar,理论上最多能存放65535个字符,varchar 字段是将实际内容单独存储在聚簇索引之外,内容开头用1到2个字节表示实际长度(长度超过255时需要2个字节),因此最大长度不能超过65535字符。当用到utf-8编码时候最多可以存21844个字符,在gbk编码下最多可以有32766个字符,Latin1 一个字符占一个字节,最多能存放 65532 个字符。
GBK编码计算方式:
若一个表只有一个varchar类型:
32766=(65535-1-2)/2。
减1的原因是实际存储从第二字节开始;
减2的原因是varchar头部的2个字节表示长度;
除2的原因是字符编码是gbk;
UTF8计算方式:
32766=(65535-1-2)/3。
减1的原因是实际存储从第二字节开始;
减2的原因是varchar头部的2个字节表示长度;
实际例子:
create table t11(c int, c2 char(30), c3 varchar(21812)) charset=utf8;
减1的原因是实际存储从第二字节开始;
减2的原因是varchar头部的2个字节表示长度;
减4的原因是int类型的c占4个字节;
减30*3的原因是char(30)占用90个字节,编码是utf8。
取数据区别
数据库取char字段的数据的时候会把空格去掉,但是在取varchar字段的数据时,数据的尾部空格会保留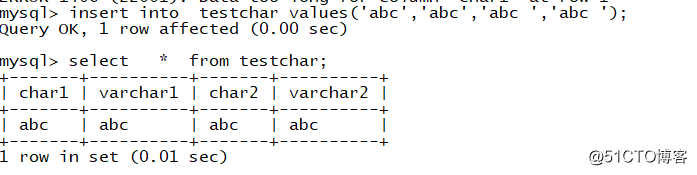


存储引擎对于选择CHAR和VARCHAR的影响:
对于MyISAM存储引擎:最好使用固定长度的数据列代替可变长度的数据列。这样可以使 整个表静态化,从而使数据检索更快,用空间换时间。
对于InnoDB存储引擎:使用可变长度的数据列,因为InnoDB数据表的存储格式不分固定 长度和可变长度,因此使用CHAR不一定比使用VARCHAR更好,但由于VARCHAR是按照 实际的长度存储,比较节省空间,所以对磁盘I/O和数据存储总量比较好。