作者:邹祁峰
邮箱:[email protected]
博客:http://blog.csdn.net/qifengzou
日期:2017.08.12 18:35
转载请注明来自"祁峰"的CSDN博客
1 引言
ChatterBot is a machine-learning based conversational dialog engine build in Python which makes it possible to generate responses based on collections of known conversations. The language independent design of ChatterBot allows it to be trained to speak any language.
完成聊天室系统的研发之后,在生产环境中发现部分聊天室中人数较少,用户之间的交流互动更是沉寂,显得十分冷清。为解决此问题,本人计划开发一个聊天机器人使其能够模拟人类的对话过程,让原本沉寂的聊天室活跃起来。
为达到以上目标,本人分析了开源社区关注度较高的聊天机器人项目ChatterBot的实现原理。
ChatterBot的优点:
1.训练语料可存放在多种介质上
2.训练结果可存放在多种介质上
3.应答匹配算法支持多种应答匹配算法:相似度匹配、数学估值算法等
4.可训练支持任何语言的聊天机器人
ChatterBot的缺点:
1.性能较低:收到聊天请求时,其需要遍历所有语料以找到相似度最高的语句,并提取对应的应答语句。因此,训练语料过多时(超过1万条),应答时延可能已无法让人接受。
2.场景有限:其只能应用到一些情况简单、场景单一的环境。由于性能较低,因此,无法使用过多的语料对ChatterBot进行训练,这也必然限制了应用场景。
2 工作原理
2.1 准备语料
ChatterBot的最大特点是:可训练支持任何语言的聊天机器人。如果希望ChatterBot能够应答中文,则需要使用中文对话语料训练;如果希望ChatterBot能够应答英文,则需要使用英文对话语料训练;其他语言依次类推。可以将ChatterBot的训练对话语料存储在数据库或本地文件中,如:MONGODB/SQLite/JSON-FILE等。[注:以下提到的数据库中的训练语料指的就是存储在MONGODB/SQLite/JSON-FILE中的对话语料]
对话语料的好坏将会直接影响聊天机器人的对话效果。设想一下,训练的对话语料的都不是正常人类的对话过程,怎么能够训练出类似人类的聊天机器人呢?最后,大家应该清楚训练语料的准备阶段与其他阶段相比非常的费时费力,可以说该阶段是最重要的。
2.2 训练阶段
完成对话语料的准备后,则需要使用这些对话语料来训练ChatterBot机器人。训练的过程其实就是将对话语料转换成对话过程中能够查询、转换的数据对象。以下是ChatterBot的训练过程:
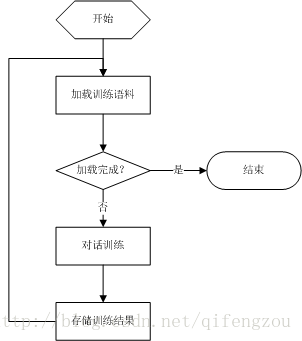
1. 加载训练语料
在进行聊天机器人的训练时,需要将存储在数据库中的训练语料逐段/全部载入内存,为对话训练做准备。
如果训练语料较多,而且使用JSON存储,则加载语料过程可能会耗费较长时间。因此,训练语料较多时,建议使用MONGODB/SQLite等数据库存储训练语料。
2. 对话训练
使用“训练”一词非常抽象,其实对话训练的过程就是将对话语料转换成对话过程中能够查询、转换的数据对象。ChatterBot之所以能够训练出支持“任何语言”的聊天机器人,关键就在于其训练过程。
ChatterBot之所以能够训练出支持“任何语言”的聊天机器人,是因为其在此过程并不对训练语料做深度加工(如:分词)处理,而是直接将训练语料直接转换成Statement->Response对,并将其存储起来。虽然其带来了支持“任何语言”的优点,但是其也带来了致命的缺点:性能低下!
3. 存储训练结果
完成对话训练后,我们需要将训练结果存储起来,以便在收到聊天请求时能够快速从之前的训练结果中找到答案并响应对方。
之前提到过:ChatterBot可将训练结果存储在数据库中(MONGODB/SQLite/JSON-FILE)。但是需要注意的是:使用Json文件存储训练语料和训练结果时,每训练一对对话ChatterBot就会将其写入到Json文件中,这样导致对Json文件大量的重复加载、重复解析、重复生成、重复写入文件的操作,非常的耗时。当训练语句超过1万条时,即使训练4-5小时可能也完不成机器人的训练过程。因此,建议使用数据库(MONGODB/SQLite)来存储最终的训练结果。
2.2 对话阶段
对话过程就是根据当前的对话请求,从之前的训练结果中找到应答语句,并发送给请求方。
如果我们采用最佳匹配策略时,当ChatterBot收到对话请求后,其将遍历所有的训练结果,让其与当前对话请求语句进行相似度计算(余旋夹角),将训练结果中与对话请求相似度最高的语句的应答作为当前请求语句的应答并返回。因此,可以发现当训练语句过大时,将会出现ChatterBot应答请求的时间太长。
2.3 性能优化
经过以上的分析,可以发现ChatterBot在训练阶段、对话阶段中均性能较低的问题,其也直接限制了ChatterBot的应用场景的扩展。如果能解决ChatterBot存储的性能问题,将会极大的增加其应用场景。
1. 对话语料的存储
使用数据库(MONGODB/SQLite)替换JSON-FILE存储对话语料,可有效防止程序一次性将对话语料载入内存。
当对话语料过大时,如果将对话语料一次性载入内存,训练过程将会出现长时间的阻塞。如果机器性能较低、内存空间较小,可能导致机器无法进行后续训练处理。
2. 对话训练的优化
ChatterBot为了能够实现对“任何语言”的处理,未对训练语料进行深度处理,且也导致了对话过程的性能低下的问题。因此,我们可以根据机器人的应用场景进行语料分词、构建倒排索引等机制,大幅提升聊天机器人的对话性能。
如果我们构建的机器人只需要支持中文对话,此时完全可以对语料进行分词处理,并构建倒排索引。当收到对话请求时,也需要对对话请求进行分词处理,根据分词结果搜索倒排索引,再根据搜索结果进行相似度匹配,将会大大的缩减相似度匹配的规模,大幅提升聊天机器人的性能。