目录
一、简要
第二章一共四小节,第二节讲的是顺序表的相关概念及实现,顺序表是线性表的顺序存储结构,是后续顺序存储的基础。在本节代码中,我会加上我大量的个人代码理解,包括我思考的一些问题和我自己得到的答案(问题加粗并设为绿色),还有我自己对代码逻辑的理解,如果有哪里写的不是很完善,或者有一些错误的地方,还希望大家能多多提出宝贵意见,本人在此表示感谢。
1、涵盖内容
1、顺序表的定义、基本操作及特点。
2、顺序表的实现(包括顺序表的建立、插入和删除、检索等)及应用(验证实现算法的正确性)。
2、学习要求
1、掌握顺序表的相关概念;
2、能用C语言编写顺序表的相关操作,包括建立,查询,插入,删除,修改等。
二、顺序表定义及相关概念
线性表的顺序存储又称为顺序表,它是用一组地址连续的存储单元,依次存储线性表中的数据元素,从而使逻辑上相邻的两个元素在物理位置上也相邻。第1个元素存储在线性表中的起始位置。第i个元素的存储位置后面紧接着存储的是第i+1个元素。
1、特点
1.表中元素的逻辑顺序与其物理顺序相同,即以元素在计算机内“物理位置”来表示线性表中数据元素之间的逻辑关系。
2.若线性表中每个元素占用l个存储单元,线性表中两相邻数据元素的存储位置之间的关系如下:
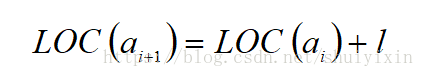
其中

3.一般来说第i个数据元素的存储位置为:
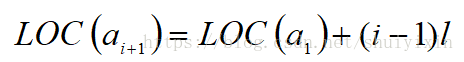
4.随机访问,随机存取,可以通过首地址和数据元素符号在O(1)时间内找到指定元素。
5.存储密度高,每个结点只存储数据元素。
4和5是顺序表的优点,同样也有它自己的缺点,因为逻辑顺序与物理顺序相同,所以在增加和删除元素时需要移动大量元素。
2、注意点
1.线性表中的元素位序是从1开始的,数组的下标是从0开始的。
2.一维数组可以是静态分配的,也可以是动态分配的。
(1)静态分配时,由于数组大小和空间已经固定,一旦空间占满,再加入新的数据就会导致程序崩溃。
(2)动态分配时,存储空间是在程序执行过程中通过动态存储分配语句分配的,一旦数据空间占满,可以另外开辟一块更大的空间,用以替换原来的存储空间,从而达到扩种空间的目的,而不需要一次性划分所有所需空间。
C++初始动态分配,需要用new来创建。
L.elem = new ElemType(List_INIT_SIZE);C语言初始动态分配,需要用到的是malloc,同时需要头文件malloc.h。
L.elem = (ElemType *)malloc(List_INIT_SIZE*sizeof(ElemType));
//(ElemType *)为强制类型转换,sizeof为获取类型对象所占字节数,通常用来查看变量,数组,或结构体等所占的字节个数。
//(类型 *)malloc(size)分配内存空间函数,在内存的动态存储区域分配一块长为“size”字节的连续区域,函数返回值为该区域的首地址,用free释放动态分配的过程不是链式存储,依然是顺序存储。其物理结构没有变化,依然是随机存取,只是分配大小可以在运行时决定。
三、线性表的实现
这里的实现应用的是C语言,因为这本教材指定的是C语言版。
在所有操作之前,我们需要考虑到需要先定义一些常量,方便在代码中使用,常用的常量宏定义如下:
#define List_INIT_SIZE 100//线性存储空间的初始分配量
#define LISTINCREMENT 10 //线性表存储空间的分配增量
#define TRUE 1
#define FALSE 0
#define OK 1
#define ERROR 0
#define OVERFLOW -1同时,为了后续操作方便,我们将相同类型的返回值重新赋给名称:
typedef int ElemType;
typedef int Status;1、顺序表的创立
根据我们对前面所有概念的理解,我们知道,顺序表需要有一个基地址,来保存这个数组,即顺序表,同时,顺序表要有两个长度,一个长度是这个顺序表当前的存储容量是多少,另一个长度表示当前顺序表的数据有多少个。
typedef struct {
ElemType *elem;//存储空间基址,用指针表示
int length;//当前长度
int listsize;//当前分配的存储量,(以sizeof(ElemType)为单位)
}SqList;在这里,我想过一个问题:在线性表中既申请了存储空间基址,又有线性表长度,又有存储量,各部分之间有什么什么联系呢?少一个可以吗?
我们知道,一个结构,应该是尽可能简单,尽量少占用内存,所以能不能减少一个?如果不能,那就说明每一部分都是必不可少的,他们必定在其中起到重要作用,对此,我的理解是:
elem是作为地址分配用的,用来申请物理空间,所以必须要有。
listsize是当前分配的存储量,作为顺序表溢出界限的标志。方便进行对比,如果用地址对比,或者用指针来对比的话,对比比较麻烦。(链表是这样实现的,链表的目的是为了插入及删除方便)。
length是当前长度用于和线性表已有存储量进行比较,防止溢出。
所以这三者,缺一不可。
2、顺序表的操作
1.构造一个空的线性表
因为顺序表三个部分都不可少,所以在构造线性表的时候,需要三个都要赋初值:elem是基地址,基地址的含义是分配线性表所占的物理空间的首地址;length是当前长度,创建之初是0;分配基地址的时候,会分配一个长为size字节的连续区域,size = 长度 * 类型字节长。这个长度就是顺序表的初始分配量。步骤操作如下:
1.给顺序表分配地址,分配地址用malloc函数。
2.判断是否分配失败,分配失败,退出操作。(在此只是为了考虑算法实现,没有设计鲁棒性,所以直接return 就行)
3.分配成功后需要分配长度,因为是空表,所以长度为0。
4.分配存储容量,使用初始存储容量。
具体代码实现如下:
Status InitList_sq(SqList &L) {
L.elem = (ElemType *)malloc(List_INIT_SIZE*sizeof(ElemType));
//(ElemType *)为强制类型转换,sizeof为获取类型对象所占字节数,通常用来查看变量,数组,或结构体等所占的字节个数。
//(类型 *)malloc(size)分配内存空间函数,在内存的动态存储区域分配一块长为“size”字节的连续区域,函数返回值为该区域的首地址,用free释放
if (!L.elem) exit(OVERFLOW) ;//存储分配失败,溢出。
L.length = 0;//空表长度为0
L.listsize = List_INIT_SIZE;//初始存储容量
return OK;
}2.销毁线性表L
首先理解一下汉语,所谓销毁,就是不留痕迹,什么都不剩下,我们在创立之初,定义了顺序表的三个重要组成部分,所以在销毁的时候,要全部销毁。
1.销毁线性表需要把所有的东西全部消除。其中 elem 需要用free释放。
2.释放后将基址放空
3.放空基址后,还需要将线性表中的长度和存储量置空,即将他们的值变为0。
Status DestroyList(SqList &L) {
free(L.elem);//通过malloc创建的线性表的存储空间基址,需要通过free来释放。
L.elem = NULL;//销毁线性表需要将L.elem放空
L.length = 0;//销毁线性表,线性表的长度和存储量都为0
L.listsize = 0;
return OK;
}3.将线性表置空L
将线性表置空,置空后线性表依然存在,只是没有数据元素,表长为0。但是有基址有存储容量。即只需要将长度置0。
Status ClearList(SqList &L) {
L.length = 0;//置空的线性表长度为0,存储空间基址不变。
return OK;
}销毁与置空的区别是什么?
这个问题挺幼稚,但是我们必须要弄明白,比如将一栋房子置空,只是将这个房子中所有的家具等一系列东西清除出去,但是这个房子还在,销毁不同,销毁是将这个房子一起销毁了,不仅房子本身不在了,房子所属的地址也将被释放,用作其他用处。
所以销毁是将表所有的东西全部清除,而置空只需要将长度置0即可。
4.判断线性表L是否为空
空表的特征为:表长度为0,所以只需要判断L的长度即可。
Status ListEmpty(SqList &L) {
if (L.length == 0)
return TRUE;
else
return FALSE;
}5.返回线性表中L的数据元素的个数
L表数据元素的个数即为L的长度,将之返回即可。
Status ListLength(SqList &L) {
return L.length;
}6.用e返回线性表L中第i个元素
获取线性表的第几位的值,因为顺序表是一组地址连续的存储单元依次存储线性表的数据结构,所以顺序表中第i个元素和第一个元素的位置关系是:
Location(i) = Location(1) + (i - 1) * l; 其中Location(i)表示第i个元素所在位置,Location(1)表示第一个元素所在位置,l表示每个数据元素占用的存储单元是l个。
所以获取在i位置的元素,直接用指针获取i位置元素即可。
1.判断i是否越界,如果i越界(不在顺序表长度范围内),则错误。
2.如果没有越界,用e返回i位置上的值。
Status GetElem(SqList L, int i, ElemType &e) {
//初始条件:0<i<=L.length,如果不满足,说明错误,所以先做判断,若满足,用e返回该值。
if (i < 1 && i > L.length)
exit(ERROR);
e = *(L.elem + i - 1);//L.elem是存储空间基址,+ i - 1 就是第i个位置,获取该位置的元素
return OK;
}7.返回L中第一个与e满足关系compare()的数据元素的位序,若不存在则返回0。
按照元素查询需要遍历线性表,需要通过指针进行遍历访问。
1.需要定义一个ElemType类型的指针变量p,并指向线性表的存储空间基址,从基址遍历查找。
2.定义一个常数i,表示当前指针位序,用于返回e的位序和判断线性表中是否存在满足compare()的元素e。
3.每次查找,不满足,指针后移,位序+1。
4.判断是否查找成功,成功返回位序,不成功返回错误。
注:该方法查找到的是满足compare的第一个元素e。
Status LocateElem(SqList L, ElemType e, Status(*compare)(ElemType,ElemType)) {
ElemType *p;
p = L.elem;//定义一个指针变量,指向线性表的存储空间基址。
int i = 1;//获取当前指针位序的变量,设置初始值为1
while (i<L.length && !compare(*p++,e))//当i不超出L.length,并且当前位序不是e时,需要将指针后移,继续寻找。
++i;//指针后移一次,位序就+1,
if (i<=L.length)
return i;//如果查找成功,返回位序
else
return ERROR;//没有查到,返回错误
}按照位序查找和按照元素查找,对于顺序表有什么不同?
对于顺序表的查找,一种是按照位置查找,一种是按照元素查找。两个方法的查找方式不同,如果是按照位置查找,直接用位序相关关系求即可,无需遍历。但是按照元素查找,需要从第一个元素开始遍历,直到查到第一个满足compare()位序的元素或者查询到结尾。两种方法的时间复杂度是不同的。按照位置查找属于随机存取,时间复杂度为o(1),按照元素查找,最坏情况下会遍历到最后一个元素,时间复杂度为o(n)。
函数中第三个参数的含义是什么?
我个人理解(可能理解有误,如果大家有不同看法,还希望能不吝赐教),compare()是一个函数,他的返回值类型是Status,即int。这个int,其实表达的不是一个数,而是一个bool类型的值,所以在最前面的宏定义中,将TRUE定义为1,FALSE定义为0。而在C语言中1表示真,0表示假。这个函数的作用是判断当前查找的元素和要查找的元素是否满足compare()中定义的关系,如果满足,返回真,不满足,返回假。
所以为了测试该函数,我做了最简单的一个compare函数,判断两个元素是否相等。
Status compare(ElemType find_e, ElemType e) {
if (find_e == e)
return true;
else
return false;
}当然也可以设置其他关系,比如倍数关系,或者较为复杂的函数关系等等,这个不是数据结构的核心,所以选择较为简单的做测试即可。
接下来的函数包括查询前驱,查询后继,插入删除某个元素等,其中查询前驱和查询后继算法原理比较相似,查询的都是某一个元素的前驱或后继,插入和删除比较相似,都是找到某一位置,在该位置插入或者删除元素,并将该位置以后的所有元素做对应的后移或者前移操作。
8.若L中的cur_e不是L的头结点,用pre_e返回cur_e的前驱。否则失败
这种查询是建立在查询元素前提下的,所以用到的也是遍历。想要获取cur_e 的前驱,需要先查找到e所在的位置,然后获取e所在位置的前一个位置的数据即可。获取位置,采用循环遍历。
1.定义指针p,指向线性表的第二个元素,获取线性表中某位置的数据进行判断,若不满足,指向下一个,继续判断。
2.如果查到该数据,获取--p对应的位置,用*获取该位置的元素,即为cur_e的前驱。
Status PriorElem(SqList L,ElemType cur_e,ElemType &pre_e) {
int i = 2;//线性表中头结点不含有前驱,所以i从2开始查找。
ElemType *p;
p = L.elem + 1;//线性表中头结点不含有前驱,所以p从存储空间基址的后继开始查找。
while (i<=L.length && *p != cur_e)//当i不超出L.length,并且当前位序不是e时,需要将指针后移,继续寻找。
{
p++;
i++;
}
if (i > L.length)
return OVERFLOW;
else
{
pre_e = *--p;
return OK;
}
}当然,算法不是唯一的,我们还可以每次都获取指针p的后继的数据元素,如果是要查找的,返回p即可,只不过我们需要先判断第一个元素是不是,因为没有一个元素的后继是第一个元素。具体实现,大家可以想一下,比较简单。
为什么我要说明这两种实现方法呢?
因为第一种方法只适用于顺序表,对于链表,找前驱时(双向链表除外),链表无法通过元素直接找前驱,只能通过元素的后继是要查找的元素时,说明该元素是要查找元素的前驱。
9.若L中的cur_e不是L的尾结点,用next_e返回cur_e的后继。
想要获取cur_e 的后继,需要先查找到e所在的位置,然后获取e所在位置的后一个位置的数据即可。获取位置,采用循环遍历。
1.定义指针p,指向线性表的首地址,获取线性表中某位置的数据进行判断,若不满足,指向下一个,继续判断。
2.如果查到该数据,获取++p对应的位置,用*获取该位置的元素,即为cur_e的后继。
Status NextElem(SqList L, ElemType cur_e, ElemType &next_e) {
int i = 1;//线性表获取后继,需要i从1开始查找。
ElemType *p;
p = L.elem;//线性表从存储空间基址开始查找。
while (i<L.length && *p != cur_e)//当i不超出L.length,并且当前位序不是e时,需要将指针后移,继续寻找。因为线性表最后一位没有后继,所以只到length-1.
{
p++;
i++;
}
if (i == L.length)
return FALSE;
else
{
next_e = *++p;
return OK;
}
}10.在L中的第i个位置之前插入新的数据元素e,L的长度+1;
例:---1 2 3 4 6 7 8 9 --- 在第五个位置插入5
在顺序表中想插入一个数据,需要将该表中该位置及以后的数据全部后移。所以从最后一位开始后移,一直到该位置。
1.判断输入的i是否在要求范围内,不在就返回错误。
2.判断当前表的长度是否大于存储量,如果等于或大于,需要分配新的存储量。加上线性表分配增量。才能进行后移,不然,最后一位会溢出。
3.用指针获取位置i前一位的位置,作为一个节点,用另一个指针进行从后向前的遍历时,到该指针处停止。
4.把e赋给i位置的指针,并将表的长度+1。
Status ListInsert(SqList &L, int i, ElemType e) {
if (i > L.length + 1 || i<1)//如果位置越界,返回错误
return ERROR;
if (L.length >= L.listsize)//如果长度大于当前存储量,需要新增存储量
{
ElemType * newBase = (ElemType *)realloc(L.elem, (L.listsize + LISTINCREMENT)*sizeof(ElemType));//重新分配基地址
if (!newBase) exit(OVERFLOW);//如果没有分配,返回错误。
L.elem = newBase;//分配成功
L.listsize += LISTINCREMENT;//新地址分配成功后需要给顺序表长度增加一段。
}
ElemType *q = &(L.elem[i - 1]);
for (ElemType * p = &(L.elem[L.length]); p >= q;--p)
*(p + 1) = *p;
*q = e;
++L.length;
return OK;
}11.删除L中的第i个元素,并用e返回它的值,L的长度-1;
删除和插入是两个相反的操作,算法分析类似,在此,我只给出算法代码,大家可以尝试自己分析,欢迎在评论区将自己的分析结果说出来,大家一起交流。
Status ListDelete(SqList &L, int i, ElemType e) {
ElemType *q = &(L.elem[L.length]);
if (i <= L.length && i>0)
{
for (ElemType * p = &(L.elem[i - 1]); p <= q;++p)
*(p - 1) = *p;
*q = e;
}
return OK;
}3、代码应用
1.顺序构造线性表
顺序构造线性表是顺序表循环执行插入操作。每次插入数据都要判断是否即将越界,如果越界要重新分配地址,然后给指针赋值。
Status SequenceStructureList(SqList &L) {
for (int i = 1; i < 10; i++)
{
if (L.length >= L.listsize)//如果长度大于当前存储量,需要新增存储量
{
ElemType * newBase = (ElemType *)realloc(L.elem, (L.listsize + LISTINCREMENT)*sizeof(ElemType));//重新分配基地址
if (!newBase) exit(OVERFLOW);//如果没有分配,返回错误。
L.elem = newBase;//分配成功
L.listsize += LISTINCREMENT;//新地址分配成功后需要给顺序表长度增加一段。
}
ElemType *q = &(L.elem[i-1]);
//注:L.elem[i-1] 和 L.elem + i - 1 是一个含义,都是表示第i个位置上的数据。
*q = i;
++L.length;
}
return OK;
}2.函数代码调用
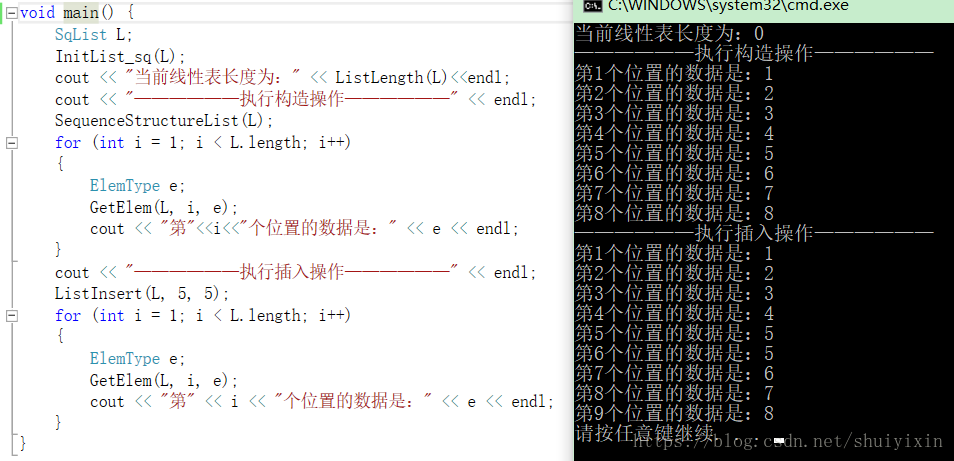
接下来我们测试一下我们写的函数。
void main() {
SqList L;
InitList_sq(L);
cout << "当前线性表长度为:" << ListLength(L)<<endl;
cout << "——————执行构造操作——————" << endl;
SequenceStructureList(L);
for (int i = 1; i < L.length; i++)
{
ElemType e;
GetElem(L, i, e);
cout << "第"<<i<<"个位置的数据是:" << e << endl;
}
cout << "——————执行插入操作——————" << endl;
ListInsert(L, 5, 5);
for (int i = 1; i < L.length; i++)
{
ElemType e;
GetElem(L, i, e);
cout << "第" << i << "个位置的数据是:" << e << endl;
}
}【输出结果】
分析码字不易,希望大家喜欢。