一、简介
HDFS采用master/slave架构,一个HDFS集群是由一个Namenode和一定数目的Datanodes组成。Namenode是一个中心服务器,负责管理文件系统的名字空间(namespace)以及客户端对文件的访问。集群中的Datanode一般是一个节点一个,负责管理它所在节点上的存储。HDFS暴露了文件系统的名字空间,用户能够以文件的形式在上面存储数据。从内部看,一个文件其实被分成一个或多个数据块,这些块存储在一组Datanode上。Namenode执行文件系统的名字空间操作,比如打开、关闭、重命名文件或目录。它也负责确定数据块到具体Datanode节点的映射。Datanode负责处理文件系统客户端的读写请求。在Namenode的统一调度下进行数据块的创建、删除和复制。
HBase采用Master/Slave架构搭建集群,它隶属于Hadoop生态系统,由一下类型节点组成:HMaster节点、HRegionServer节点。一个HMaster和一定数目的HRegionServer组成
YARN总体上采用master/slave架构,其中Master被称为ResourceManager,Slave被称为NodeManager,ResourceManager负责对各个NodeManager上的资源进行统一管理和调度。当用户提交一个应用程序时,需要提供一个用以跟踪和管理这个程序的ApplicationMaster,它负责向ResourceManager申请资源,并要求NodeManger启动可以占用一定资源的Container。由于不同的ApplicationMaster被分布到不同的节点上,并通过一定的隔离机制进行了资源隔离,因此它们之间不会相互影响。
二、Linux环境配置
1、集群的说明
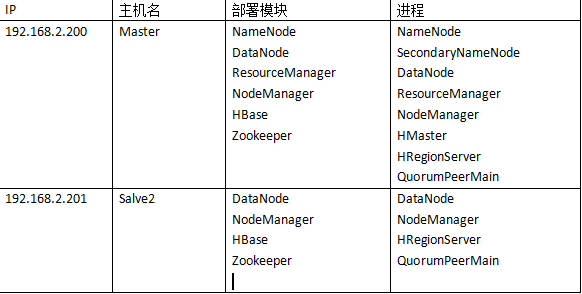
集群中包括3个节点:1个Master,2个Slave(本来是要使用3台,我这边只有两个虚拟机 (Salve1和Master就放在一起))
Master 192.168.2.200
Salve1 192.168.2.200
Salve2 192.168.2.201
2、修改hosts
1)可以修改当前机器名称
192.168.2.200(Master)
192.168.2.201(Salve2)
# vi /etc/sysconfig/network

#service network restart 重启网络
2)、必须配置hosts文件(Master与Salve2都是一样)
#vi /etc/hosts

3、配置JDK1.7

不懂怎么在Linux上配置JDK,可以查看Linux下配置JAVA环境
4、主机之间SSH无密码验证(这个比较重要)
Master作为客户端,要实现无密码公钥认证,连接到服务器Salve上时,需要在Master上生成一个密钥对,包括一个公钥和一个私钥,而后将公钥复制到所有的Salve上。当Master通过SSH链接到Salve上时,Salve会生成一个随机数并用Master的公钥对随机数进行加密,并发送给Master。Master收到加密数之后再用私钥解密,并将解密数回传给Salve,Salve确认解密数无误之后就允许Master进行连接了。这就是一个公钥认证过程,期间不需要手工输入密码,重要的过程是将Master上产生的公钥复制到Salve上。
1)查看一下SSH是否有安装
# ssh -version

2)基于空口令创建一个新的SSH密钥,启用无密码登录
第一步:拷贝文件id_rsa.pub到192.168.2.200(Master)的root目录下面
#ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa
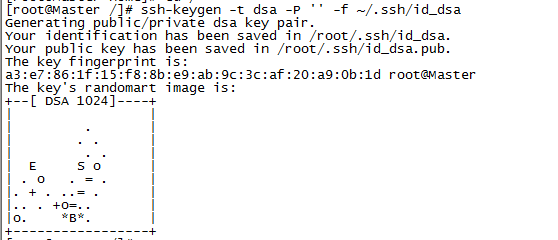
第二步:把id_rsa.pub追加到授权的key里面去。
[root@Master /]# cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys

第三步:修改文件"authorized_keys"
#chmod 600 ~/.ssh/authorized_keys
第四步:启动服务(需要权限用户)
#service sshd restart
第五步:把公钥复制所有的Slave机器上
#scp -r ~/.ssh/authorized_keys [email protected]:~/.ssh/
第六步:测试一下是否需要密码登陆
#ssh Salve2

5、关闭集群中所有机器的防火墙
在启动前关闭集群中所有机器的防火墙,不然会出现datanode开后又自动关闭。
#service iptables stop
6、下载Hadoop 、hbase、Zookeeper 安装包
1)、下载Hadoop 2.5.2
https://dist.apache.org/repos/dist/release/hadoop/common/
2)、下载hbase1.0.3
http://mirrors.hust.edu.cn/apache/hbase/
3)、下载Zookeeper 3.4.6
http://mirrors.hust.edu.cn/apache/zookeeper/
并把下载好的安装包上传到Linux的/usr/local/hadoop

三、Zookeeper 集群配置
1、tar -zxvf zookeeper-3.4.6.tar.gz
2、配置zoo.cfg
#cd /usr/local/hadoop/zookeeper-3.4.6/conf/
#cp zoo_sample.cfg zoo.cfg
第一步: #vi zoo.cfg
dataDir=/usr/local/hadoop/zookeeper-3.4.6/zkData
server.1=Salve1:2888:3888
server.2=Salve2:2888:3888
第二步:创建myid(Master 对myid写入编号1 、Salve2对myid写入编号2 )
#mkdir /usr/local/hadoop/zookeeper-3.4.6/zkData
#touch /usr/local/hadoop/zookeeper-3.4.6/zkData/myid
//Master 对myid写入编号1
#echo 1 > /usr/local/hadoop/zookeeper-3.4.6/zkData/myid
第三步:将配置好的zookeeper拷贝到其他节点对应的相同的目录
#scp -r /usr/local/hadoop/zookeeper-3.4.6/ Salve2:/usr/local/hadoop/zookeeper-3.4.6/
第四步:Salve2 对myid写入编号2
#echo 2 > /usr/local/hadoop/zookeeper-3.4.6/zkData/myid
在部署zookeeper的节点上的/usr/local/hadoop/zookeeper-3.4.6/zkData/的目录下新建一个myid文件里写上zoo.cfg文件对应的server号码,Salve1写1,Salve2写2 。
四、hadoop 集群配置
1、tar -zxvf hadoop-2.5.2.tar.gz
2、修改Master、Salve2 /etc/profile 默认设置hadoop path
#vi /etc/profile
//在末尾添加
# set hadoop path
export HADOOP_HOME=/usr/local/hadoop/hadoop-2.5.2
export PATH=$PATH :$HADOOP_HOME/bin 重启"/etc/profile"
# source /etc/profile
3、hadoop配置
1) 配置 hadoop-env.sh文件 java环境
export JAVA_HOME=/usr/java/jdk1.7.0_80 2) 配置core-site.xml文件
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/hadoop/tmp</value>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://Master:9000</value>
</property>
</configuration>3) 配置mapred-site.xml文件
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.adress</name>
<value>Master:10020</value>
</property>
<property> <name>mapreduce.jobhistory.webapp.adress</name>
<value>Master:19888</value>
</property>
</configuration>4)配置hdfs-site.xml文件
<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/data/hdfs/namenode</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/data/hdfs/datanode</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>Master:50090</value>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
</configuration> 这里的dfs.replication用来设置每份数据块的副本数目,默认是3,因为我们是在单机上配置的分布模式,因此设为2。dfs.name.dir和dfs.data.dir非常重要,用来设置存放hdfs中namenode和datanode数据的本地存放位置。这里如果设置不好,后续会出现多个错误。当然你也可以不设置采用默认的/tmp下的目录,但是同样重启会丢失数据。
5)配置yarn-site.xml文件
<configuration>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>Master:8030</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>Master:8032</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>Master:8088</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>Master:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>Master:8033</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
</configuration>7)配置slaves文件
Salve1
Salve2然后拷贝一份到Salve2
五、hbase集群配置
1、tar -zxvf hbase-1.0.3-bin.tar.gz
2、修改Master、Salve2 /etc/profile 默认设置hbase path
#vi /etc/profile
//在末尾添加
# set hbase path
export HBASE_HOME=/usr/local/hadoop/hbase-1.0.3
export PATH= $PATH:$HBASE_HOME/bin 重启 /etc/profile
# source /etc/profile
3、hbase配置
#cd hbase-1.0.3/conf/
1)配置hbase-env.sh
export JAVA_HOME=/usr/java/jdk1.7.0_80
export HBASE_MANAGES_ZK=false HBASE_MANAGES_ZK=false,表示启动的是独立的zookeeper。而配置成true则是hbase自带的zookeeper。
2)配置hbase-site.xml
# vi hbase-site.xml
<configuration>
<property>
<name>hbase.rootdir</name>
<value>hdfs://Master:9000/hbase</value>
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<property>
<name>hbase.zookeeper.property.dataDir</name>
<value>/usr/local/hadoop/zookeeper-3.4.6/zkData</value>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>Master,Salve2</value>
</property>
</configuration>说明:
hbase.cluster.distributed指定了Hbase的运行模式。false是单机模式,true是分布式模式。
hbase.zookeeper.quorum是Zookeeper集群的地址列表,用逗号分割。
3)配置 regionservers
Salve1
Salve2同样把hbase拷贝一份到Salve2
六、Hadoop 、hbase、Zookeeper集群启动
1、启动 ZooKeeper 集群 (分别在Master、Salve2上启动zk)
ZooKeeper 安装在Master、Savle2机子上,在Master、Savle2机子上执行启动命令。
# cd /usr/local/hadoop/zookeeper-3.4.6/
第一步:在Master、Savle2启动ZooKeeper
#./bin/zkServer.sh start

第二步:可以查看ZooKeeper 状态
启动完成后可以看zookeeper是leader、follower
#./bin/zkServer.sh status


如果./bin/zkServer.sh status为失败,

可以通过命令查看错误的信息:#tailf zookeeper.out
2、 启动 hadoop 集群 (Master)
第一步:第一次,格式化namenode
#hadoop namenode -format
第二步:启动所有服务
#./sbin/start-all.sh
3、 启动 hbase集群 (Master)
#./bin/start-hbase.sh
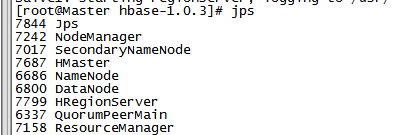
4、jps查看进程

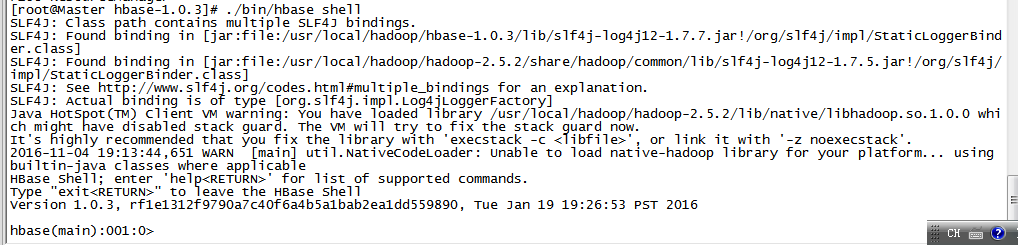
5、hbase shell
6、其他说明
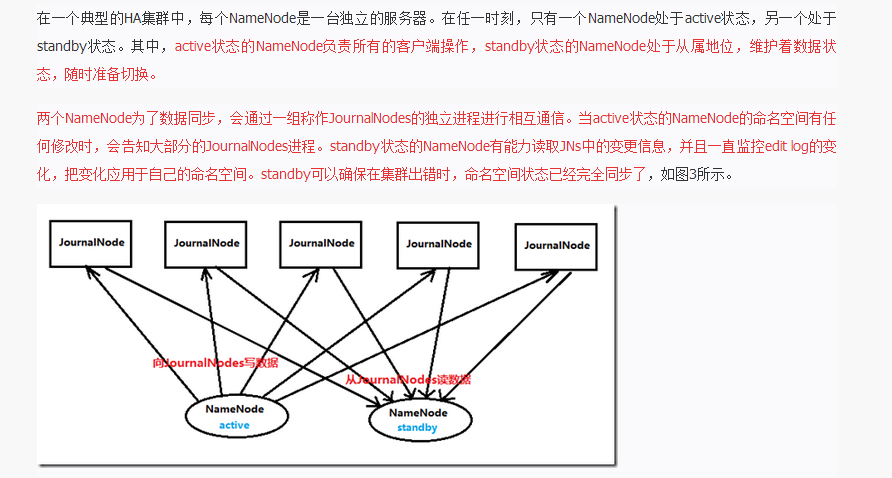
1)、有的在Master上启动namenode,Master2上在启动另外namenode。
#hadoop-daemon.sh start namenode(启动namenode)
#hadoop-daemons.sh start datanode(启动datanode)
#hadoop-daemon.sh start journalnode(在节点上都启动)
journalnode
https://my.oschina.net/u/189445/blog/661561
2)、启动备份hbase的 HMaster
#hbase-daemon.sh start master
大数据刚入门不久,有什么不对的地方,可以指出来,相互学习,相互成长。