这一篇接着记录集群搭建,开始安装配置zookeeper,它的作用是做集群的信息同步,zookeeper配置时本身就是一个独立的小集群,集群机器一般为奇数个,只要机器过半正常工作那么这个zookeeper集群就能正常工作,工作时自动选举一个leader其余为follower,所以最低是配置三台。
注意本篇文章的几乎所有操作如不标注,则默认为hadoop用户下操作
1.首先修改下上一篇写的批量脚本
复制一份,然后把ips内删除两台机器名,,只留下前三台即可,然后把几个脚本的名称啥的都改一下,和内部引用名都改一下。
可以用我改好的https://www.lanzous.com/b849762/ 密码:1qq6
2.安装zookeeper
可以用xshell的rz命令上传zookeeper安装包,安装包在这里https://www.lanzous.com/b849708/ 密码:8a10
[hadoop@nn1 ~]$ cd zk_op/
批量发送给三台机器
[hadoop@nn1 zk_op]$ ./zk_scp_all.sh ~/upload/zookeeper-3.4.8.tar.gz /tmp/
查看是否上传成功
[hadoop@nn1 zk_op]$ ./zk_ssh_all.sh "ls -l /tmp | grep zoo*"
批量解压到各自的/usr/local/目录下
[hadoop@nn1 zk_op]$ ./zk_ssh_root.sh tar -zxf /tmp/zookeeper-3.4.8.tar.gz -C /usr/local/
再次查看是否操作成功
[hadoop@nn1 zk_op]$ ./zk_ssh_all.sh "ls -l /usr/local/ | grep zoo*"
批量改变/usr/local/zookeeper-3.4.8目录的用户组为hadoop:hadoop
[hadoop@nn1 zk_op]$ ./zk_ssh_root.sh chown -R hadoop:hadoop /usr/local/zookeeper-3.4.8
[hadoop@nn1 zk_op]$ ./zk_ssh_root.sh chmod -R 770 /usr/local/zookeeper-3.4.8
[hadoop@nn1 zk_op]$ ./zk_ssh_all.sh "ls -l /usr/local/ | grep zookeeper-3.4.8"
批量创建软链接(可以理解为快捷方式)
[hadoop@nn1 zk_op]$ ./zk_ssh_root.sh ln - s /usr/local/zookeeper-3.4.8/ /usr/local/zookeeper
[hadoop@nn1 zk_op]$ ./zk_ssh_all.sh "ls -l /usr/local/ | grep zookeeper"
这里软链接的用户组合权限可以不用修改,默认为root或者hadoop都可以。 修改/usr/local/zookeeper/conf/zoo.cfg
可以用我改好的https://www.lanzous.com/b849762/ 密码:1qq6
批量删除原有的zoo_sample.cfg文件,当然先备份为好
[hadoop@nn1 zk_op]$ ./zk_ssh_root.sh rm -f /usr/local/zookeeper/conf/zoo_sample.cfg
把我们准备好的配置文件放进去,批量。
[hadoop@nn1 zk_op]$ ./zk_scp_all.sh ~/zoo.cfg /usr/local/zookeeper/conf/
=================================================================================================
然后修改/usr/local/zookeeper/bin/zkEnv.sh脚本文件,添加日志文件路径
[hadoop@nn1 zk_op]$ vim /usr/local/zookeeper/bin/zkEnv.sh
ZOO_LOG_DIR=/data
把这个配置文件批量分发给其他机器
[hadoop@nn1 zk_op]$ ./zk_scp_all.sh /usr/local/zookeeper/bin/zkEnv.sh /usr/local/zookeeper/bin/
给5台机器创建/data目录,注意这里是给5台机器创建。用的没改过的原本批量脚本。
[hadoop@nn1 hadoop_base_op]$ ./ssh_root.sh mkdir /data
[hadoop@nn1 hadoop_base_op]$ ./ssh_root.sh chown hadoop:hadoop /data
[hadoop@nn1 hadoop_base_op]$ ./ssh_all.sh "ls -l | grep data"上面为啥是突然创建5个/data呢,,,因为后边的hdfs和yarn都需要,后边的hdfs是运行在后三台机器上的,所以现在直接都创建好。
然后回到zk_op中,给前三台机器创建id文件。用于zookeeper识别
[hadoop@nn1 zk_op]$ ./zk_ssh_all.sh touch /data/myid然后_分别进三台机器_,给这个文件追加id值。
第一台:
echo "1" > /data/myid
第二台:
echo "2" > /data/myid
第三台:
echo "3" > /data/myid
3.批量设置环境变量
在nn1上切换到root用户更改系统环境变量
[hadoop@nn1 zk_op]$ su - root
[root@nn1 ~]# vim /etc/profile
文件在末尾添加
#set Hadoop Path
export HADOOP_HOME=/usr/local/hadoop
export HADOOP_COMMON_HOME=${HADOOP_HOME}
export HADOOP_HDFS_HOME=${HADOOP_HOME}
export HADOOP_MAPRED_HOME=${HADOOP_HOME}
export HADOOP_YARN_HOME=${HADOOP_HOME}
export HADOOP_CONF_DIR=${HADOOP_HOME}/etc/hadoop
export HDFS_CONF_DIR=${HADOOP_HOME}/etc/hadoop
export YARN_CONF_DIR=${HADOOP_HOME}/etc/hadoop
export LD_LIBRARY_PATH=$HADOOP_HOME/lib/native:/usr/lib64
export HBASE_HOME=/usr/local/hbase
export HIVE_HOME=/usr/local/hive
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$HBASE_HOME/bin:$HIVE_HOME/bin:/usr/local/zookeeper/bin然后批量发送给其他两台机器
[hadoop@nn1 zk_op]$ ./zk_scp_all.sh /etc/profile /tmp/
[hadoop@nn1 zk_op]$ ./zk_ssh_root.sh cp -f /tmp/profile /etc/profile
批量检查一下
[hadoop@nn1 zk_op]$ ./zk_ssh_all.sh tail /etc/profile
批量source一下环境变量
[hadoop@nn1 zk_op]$ ./zk_ssh_root.sh source /etc/profile4.批量启动zookeeper
[hadoop@nn1 zk_op]$ ./zk_ssh_all.sh /usr/local/zookeeper/bin/zkServer.sh start
查看一下是否启动。看看有没有相关进程
[hadoop@nn1 zk_op]$ ./zk_ssh_all.sh jps如下图查看进程,有QPM进程就说明启动成功
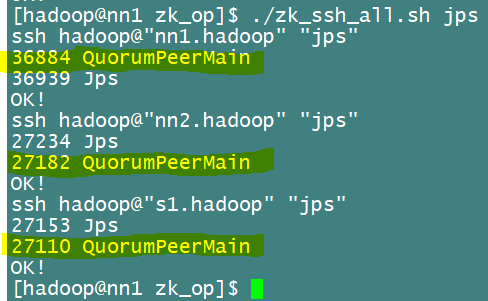
或者直接查看状态,
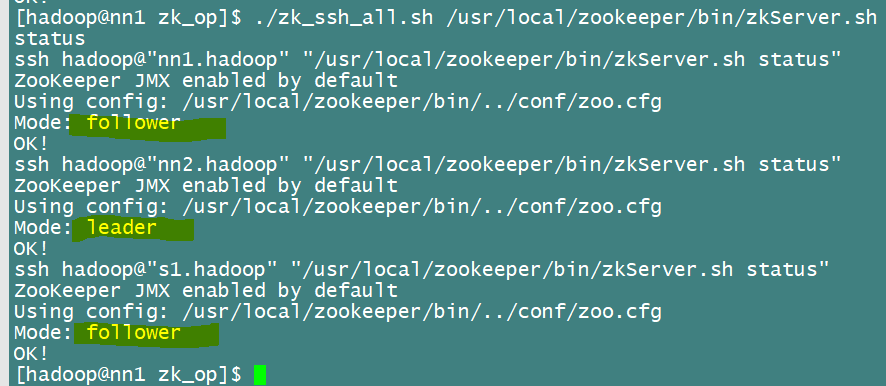
好了,zookeeper安装配置顺利结束!!!