《Facial Landmark Detection with Tweaked Convolutional Neural Networks》论文解读
论文地址:
http://www.openu.ac.il/home/hassner/projects/tcnn_landmarks/
概述
如我前面所说,人脸特征点检测是一个回归问题,这个问题需要关注两个方面:一是人脸特征表示,二是回归方法。这次解析的论文是使用深度学习的方法来做特征点检测,它的方法也不会脱离这个框架的。
Vanilla CNN
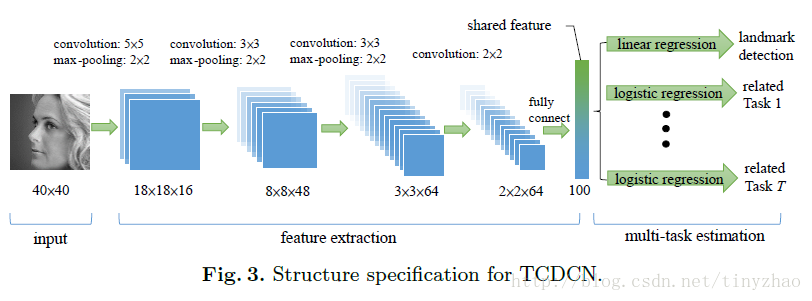
其实这篇论文的网络结构和前面的TCDCN网络结构是一样的,就不一一细说了。
TCDCN:
Vanilla CNN:

和TCDCN不一样的地方在于:去掉多任务学习而且使用彩色图像。损失函数也不一样,这里使用的损失函数使用了两眼间距离进行标准化:
至此,本文中使用Vanilla CNN人脸特征点检测结束了。文章后面的内容是TCNN,这部分作者还没有放出源码,我们简单看一下。
网络特征分析
随后作者对这个模型提出了一些思考,由此引出了下面的TCNN。这个问题就是,网络到底学习到了什么样特征?
作者对网络不同层的特征进行使用GMM进行聚类分析,发现网络进行的是层次的,由粗到精(hierarchical, coarse to fine)的特征定位,越深的网络特征越能反应出特征点的位置。
作者对FC5的输入进行了分析,也就是网络示意图中红色圆圈部分,将这些特征使用了GMM聚成64类,并显示出每一个聚类中心(相同类别脸的平均):

显然,这些特征展示出了人脸的不同姿势,还可以看出不同的人脸属性,比如表情和性别,作者认为这是因为人脸特征点的位置常常和人脸的属性相关联。
TCNN
从上面对特征的分析可以看出,在深层模型中,越深的层所表示的特征越针对某项具体任务。在红圈处的特征已经能大致反应出人脸的姿势信息,作者由此想到针对不同的姿势训练对应的回归模型。这样人脸特征点检测就变成两步,先粗定位然后再精确定位。
具体做法是保持网络前面不变,fine-tuning最后一层FC5,使用具有相似特征的图片训练对应的回归器。

TCNN训练过程为:先训练好Vanilla CNN,然后从红圈处提取特征,将特征使用GMM聚类,使用同一类的图片fine-tune后面对应的回归器权值。
结果
按论文说,Vanilla CNN的结果比TCDCN好一点。

我使用MXNet进行的一次测试:

代码
作者给出了Vanilla CNN的caffe模型,我把它转成了MXNet模型,可以去我的GitHub上下载:
总结
本文其实对人脸特征点检测任务创新不是很多,论文主要价值在于分析了网络中每一层特征的意义。