正好想写一条删除重复语句并保留一条数据的SQL,网上查了一部分资料写的很详细,但还是在这里写下自己的理解,以遍后续学习 。如下:
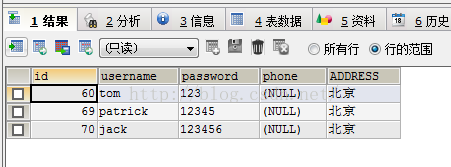
表字段和数据:
SQL语句:
- DELETE FROM `user` WHERE id NOT IN(SELECT * FROM(SELECT id FROM `user` GROUP BY username)AS b)
理解:
先从里面的SQL开始看
1、SELECT id FROM `user` GROUP BY username 根据名字分组查询出每组的ID。
2、SELECT * FROM(SELECT id FROM `user` GROUP BY username) AS b 这句话中有2个疑问点,
第一、为什么要套这样一个select?因为 更新数据时使用了查询,而查询的数据又做更新的条件,mysql不支持这种方式
如果不套上这个select查询,那么将会报1093 - You can't specify target table 'user' for update in FROM clause错误。
第二、这句话中一定要取别名,不然会报1248 - Every derived table must have its own alias 错误
3、结合上面的分析来看一下整个的SQL语句理解,先将分组的ID查出来,然后删除USER表中ID 不在分组ID中的数据,那么就实现效果了。
delete from 表名 where ID not in (select * from (select id from 表名 group by 分组的列名) 别名)
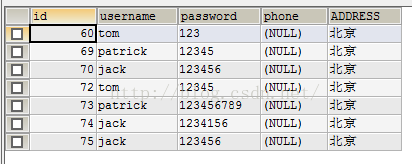
效果如下: