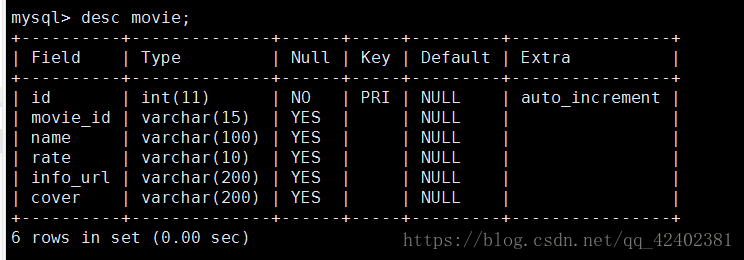
先看下表结构
1.首先查询重复数据的id(这里面的movie_id有重复的)
SELECT id from movie GROUP BY movie_id HAVING COUNT(movie_id)>1 (这里默认好像是查询最小的id)
2.查询重复的movie_id对应的id
select id from movie where movie_id in (SELECT movie_id from movie GROUP BY movie_id HAVING COUNT(movie_id)>1)(这里查询movie_id对应全部的id)
扫描二维码关注公众号,回复:
4927291 查看本文章

3.从总的id里面减去重复数据的最小id即为我们要删除的id的集合
然后我准备这样写:
delete from movie where id in
(select id from movie where movie_id in (SELECT movie_id from movie GROUP BY movie_id HAVING COUNT(movie_id)>1))
and id not in (SELECT id from movie GROUP BY movie_id HAVING COUNT(movie_id)>1)
然后就报错了,查资料好像是mysql数据库里select和delete不能一起用,网上有种方法是构建临时表储存被删除的id,然后再删除,感觉有点麻烦。
最后我是用python脚本删除重复数据的,用列表存储被删除的id,构建sql语句删除就好了
具体代码如下:
import pymysql
result=[]
conn=pymysql.connect(host='localhost',user='root',password='password',db='web',charset='utf8')
cur=conn.cursor()
sql='''
select id from movie where movie_id in (SELECT movie_id from movie GROUP BY movie_id HAVING COUNT(movie_id)>1) and id not in (SELECT id from movie GROUP BY movie_id HAVING COUNT(movie_id)>1)
'''
cur.execute(sql)
for each in cur.fetchall():
result.append(each[0])
for each in result:
sql='delete from movie_info where id=%d'%each
cur.execute(sql)
conn.commit()
conn.close()