os模块
• 为访问操作系统的特定熟悉提供方法
• 提供了对平台模块的封装(对 windows, 对 mac 的封
装等)
import os
# 1). 返回操作系统类型, 值为posix,是Linux操作系统, 值为nt, 是windows操作系统
print(os.name)
# 2). 操作系统的详细信息
info = os.uname()
print(info)
# 3). 系统环境变量
print(os.environ)
# 4). 通过key值获取环境变量对应的value值
print(os.environ.get('PATH'))
print(os.getenv('PATH'))
#5).获取当前的工作目录
print(os.getcwd())
#os.access(path,mod)
# 判断对一个文件或者目录是否具有指定的权限
# mode 参数的可选值: R_OK, W_OK, and X_OK.
print(os.access('python-os.py', mode=os.R_OK))
# 6). 创建目录/删除目录
os.mkdir('floating')
os.makedirs('floating/films')
#os.rmdir('floating')
# 7). 创建文件/删除文件
os.mknod('coffee.txt')
#os.remove("cooffee.txt")
# 8). 文件重命名(mv)
os.rename("data.txt",'data1.txt')
# 9).列出给定目录的内容
print(os.listdir('/home/kiosk/Desktop/python1'))
# 10). 判断文件或者目录是否存在
print(os.path.exists('floating'))
print(os.path.exists('data1.txt'))
# 11). 分离后缀名和文件名
print(os.path.splitext('hello.peng'))
# 12). 将目录名和文件名分离
print(os.path.split("/tmp/hello/hello.peng"))
# 13). 判断是否为绝对路径
print(os.path.isabs('/tme/hello'))
print(os.path.isabs('hello'))
# 14). 生成绝对路径
print(os.path.abspath("/tmp/hello"))
print(os.path.abspath('hello.peng'))
# 15).将目录与文件拼接
print(os.path.join('/home/kiosk','hello.peng'))
print(os.path.join(os.path.abspath('.'),'hello.peng')) # 返回一个绝对路径: 当前目录的绝对路径+ 文件名/目录名
# 16).获取目录名或者文件名
filename='/home/kiosk/Desktop/python1/day9-1/hello.peng'
print(os.path.basename(filename))
print(os.path.dirname(filename))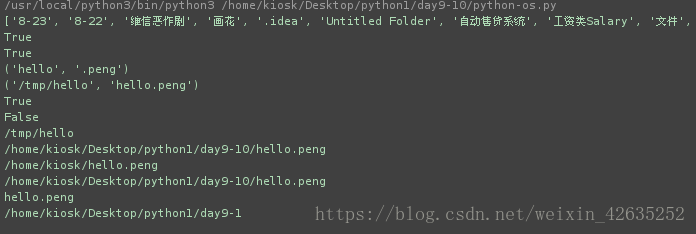
# 17).返回path的最后访问时间
print(os.path.getatime ('coffee.txt'))
# 18).文件元数据最后修改时间(或者可以说是文件状态最后修改时间)
print(os.path.getctime('coffee.txt'))
# 19).返回path的最后修改时间
print(os.path.getmtime('coffee.txt'))
# 20).返回文件大小
print(os.path.getsize('coffee.txt'))
# 21).判断是否是目录
print(os.path.isdir('coffee.txt'))
# 22).判断是否是文件
print(os.path.isfile('coffee.txt'))
# 23).判断是否是链接
print(os.path.islink('coffee.txt'))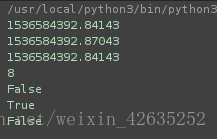
sys模块
sys 模块,主要提供了系统相关的配置和操作,封装了探测、改变解释器
runtime 以及资源的交互。
import sys
#得到解释器的版本信息
print(sys.version)
#得到当前运行平台
print(sys.platform)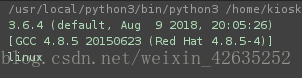
sys.argv 获取传递给脚本的参数,参数解析类似于 bash 的方式,第
一个参数代表脚本本身;
sys.stderr , sys.stdin , sys.stdout 这些都分别代表一个文件对象;
import sys
#以列表方式返回传递给脚本的参数
print(sys.argv)
#sys.stderr , sys.stdin , sys.stdout 这些都分别代表一个文件对象;
print(sys.stderr)
print(sys.stdin)
print(sys.stdout)
time及datetime模块
time模块
- 简介:time模块--时间获取和转换
time模块提供各种时间相关的功能
与时间相关的模块有:time,datetime,calendar
这个模块中定义的大部分函数是调用C平台上的同名函数实现 - 术语和约定的解释: 1.时间戳(timestamp)的方式:通常来说,时间戳表示的是从1970年1月1日开始按秒计算的偏移量(time.gmtime(0))此模块中的函数无法处理1970纪元年以前的时间或太遥远的未来(处理极限取决于C函数库,对于32位系统而言,是2038年)
2.UTC(Coordinated Universal Time,世界协调时)也叫格林威治天文时间,是世界标准时间.在我国为UTC+8
3.DST(Daylight Saving Time)即夏令时
4.时间元组(time.struct_time对象, time.localtime方法)
5.字符串时间(time.ctime) - 常用的时间转换
import time
# 把看不懂的时间戳转换为字符串格式
a=time.time()
print(a)
print(time.ctime(a))
# 把看不懂的时间戳转换为元组格式
print(time.localtime(a))
import time
# 把元组的时间转换为时间戳
tuple_time = time.localtime()
print(time.mktime(tuple_time))
# 把元组的时间转换字符串格式
print(time.strftime('%m-%d',tuple_time))
print(time.strftime('%Y-%m-%d',tuple_time))
print(time.strftime('%T',tuple_time))
print(time.strftime('%F',tuple_time))
# 字符串格式转换为元组
s='2018-10-10'
print(time.strptime(s,'%Y-%m-%d'))
s_time='12:12:30'
print(time.strptime(s_time,'%H:%M:%S'))
eg:想要得到/etc/group文件的最后一次修改时间,
对应的年月日这些信息,并保存在文件date.txt文件中。
import os
import time
time1 = os.path.getctime('/etc/group')
tuple_time = time.localtime(time1)
year = tuple_time.tm_year
month = tuple_time.tm_mon
day = tuple_time.tm_mday
with open('date.txt', 'w') as f:
f.write("%d %d %d" %(year, month, day))在date.txt文件中:
datetime模块
from datetime import date
from datetime import datetime
from datetime import timedelta
# 获取当前的日期并且以字符串方式返回
print(date.today())
d=date.today()
print(d)
# 对象加或者减一个时间间隔, 返回一个新的日期对象;
delta = timedelta(days=3)
print(d-delta)
#获取当前时间
d=datetime.now()
print(d)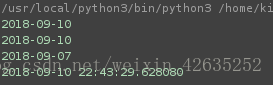
eg:监控系统
1. 获取当前主机信息, 包含操作系统名, 主机名, 内核版本, 硬件架构等
2. 获取开机时间和开机时长;
3. 获取当前登陆用户
import os
import psutil as psutil
from datetime import datetime
info = os.uname()
print('1.主机信息'.center(50,'*'))
print("""
操作系统:%s,
主机名:%s,
内核版本:%s,
硬件构架:%s
"""%(info.sysname,info.nodename,info.release,info.machine))
print("2.开机时间".center(50,"*"))
# 获取开机时间的时间戳, 需要安装psutil模块;
boot_time = psutil.boot_time()
# 将时间戳转换为字符串格式, 两种方法, 任选一种
# print(time.ctime(boot_time))
boot_time= datetime.fromtimestamp(boot_time)
# 获取当前时间
now_time = datetime.now()
# 获取时间差
delta_time = now_time-boot_time
delta_time = str(delta_time).split('.')[0]
print("""
开机时间:%s
当前时间:%s
开机时长:%s
"""%(boot_time,now_time,delta_time))
print("3.当前登陆用户".center(50,"*"))
# 获取当前登陆用户的详细信息, 需求是获取用户名和登陆主机;
users = psutil.users()
# 获取需要的信息,实现信息的去重
users = {'%s %s'%(user.name,user.host) for user in users}
for user in users:
print("\t %s"%(user))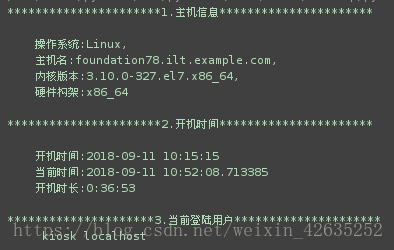
print(psutil.disk_partitions())
print(psutil.virtual_memory())
namedtupled新型数据类型
因为元组的局限性:不能为元组内部的数据进行命名,所以往往我们并不知道一个元组所要表达的意义,
所以在这里引入了 collections.namedtuple 这个工厂函数,来构造一个带字段名的元组。
具名元组的实例和普通元组消耗的内存一样多,因为字段名都被存在对应的类里面。这个类跟普通的对象
实例比起来也要小一些,因为 Python 不会用 _ dict _ 来存放这些实例的属性。
def namedtuple(typename, field_names, *, verbose=False, rename=False, module=None):
- typename: 元组名称
- field_names : 元组中元素的名称
- rename: 如果元素名称中包含python关键字,必须设置rename=True
from collections import namedtuple
user = namedtuple('User',['name','age','gender'])
u = user('cooffee',13,'male')
print(u.name)
print(u.age)
print(u.gender)
print(u)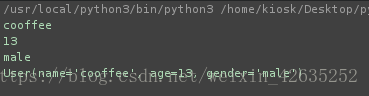
openpyxl模块
excel文档的基本定义
- 工作薄(workbook)
- 工作表(sheet)
- 活动表(active sheet)
- 行(row): 1,2,3,4,5,6……..
- 列(column): A,B,C,D……..
- 单元格(cell): B1, C1
import openpyxl
# 打开一个excel文档, class 'openpyxl.workbook.workbook.Workbook'实例化出来的对象
wb = openpyxl.load_workbook('classbox.xlsx')
print(wb,type(wb))
# 获取当前工作薄里所有的工作表, 和正在使用的表;
print(wb.sheetnames)
print(wb.active)
# 选择要操作的工作表, 返回工作表对象
sheet = wb['Sheet1']
# 获取工作表的名称
print(sheet.title)
#返回指定行指定列的单元格信息
print(sheet.cell(row=1,column=2).value)
cell =sheet['B1']
print(cell)
print(cell.row,cell.column,cell.value)
# 获取工作表中行和列的最大值
print(sheet.max_column)
print(sheet.max_row)
sheet.title = "学生信息"
print(sheet.title)
# 访问单元格的所有信息
print(sheet.rows) # 返回一个生成器, 包含文件的每一行内容, 可以通过便利访问.
# 循环遍历每一行
for row in sheet.rows:
# 循环遍历每一个单元格
for cell in row:
# 获取单元格的内容
print(cell.value,end=',')
# 保存修改信息
wb.save(filename='classbox1.xlsx')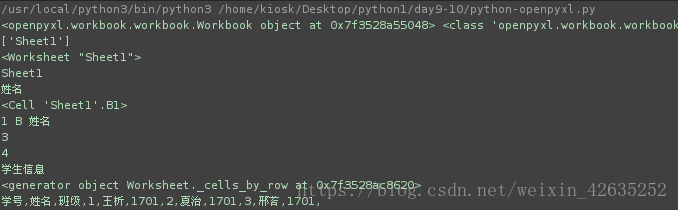
eg:
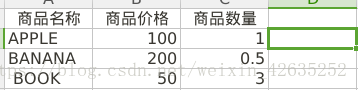
商品名称 商品价格 商品数量
- 定义一个函数, readwb(wbname, sheetname=None)
- 如果用户指定sheetname就打开用户指定的工作表, 如果没有指定, 打开active sheet;
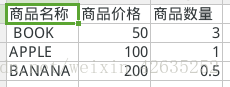
- 根据商品的价格进行排序(由小到大), 保存到文件中;商品名称:商品价格:商品数量
- 所有信息, 并将其保存到数据库中;
import openpyxl
def readwb(wbname,sheetname=None):
# 打开工作薄
wb = openpyxl.load_workbook(wbname)
# 获取要操作的工作表
if not sheetname:
sheet = wb.active
else:
sheet = wb[sheetname]
# 获取商品信息保存到列表中
all_info = []
for row in sheet.rows:
child = [cell.value for cell in row]
all_info.append(child)
return sorted(all_info[1:],key=lambda item:item[1])
def save_to_excel(data,wbname,sheetname='sheet1'):
print("写入Excel[%s]中....."%(wbname))
# 打开excel表, 如果文件不存在, 自己实例化一个WorkBook对象
wb=openpyxl.Workbook()
# 修改当前工作表的名称
sheet = wb.active
# 修改工作表的名称
sheet.title = sheetname
# 往单元格写入内容
# sheet.cell['B1'].value = "value"
# sheet.cell(row=1, column=2, value="value")
sheet.cell(row=1,column=1,value='商品名称')
sheet.cell(row=1, column=2, value='商品价格')
sheet.cell(row=1, column=3, value='商品数量')
for row,item in enumerate(data):
for column,cellvalue in enumerate(item):
sheet.cell(row=row+2,column=column+1,value=cellvalue)
# 保存写入的信息
wb.save(filename=wbname)
print("写入成功")
data = readwb(wbname='Book1.xlsx')
save_to_excel(data,wbname='Book2.xlsx',sheetname='排序商品')Book1.xlsx:
‘Book2.xlsx:
eg:
每一行代表一次单独的销售。列分别是销售产品的类型(A)、产品每磅的价格
(B)、销售的磅数(C),以及这次销售的总收入。TOTAL 列设置为 Excel 公式,将每磅的成本乘以销售的磅数,
并将结果取整到分。有了这个公式,如果列 B 或 C 发生变化,TOTAL 列中的单元格将自动更新.
需要更新的价格如下:
Celery 1.19
Garlic 3.07
Lemon 1.27
现在假设 Garlic、 Celery 和 Lemons 的价格输入的不正确。这让你面对一项无聊
的任务:遍历这个电子表格中的几千行,更新所有 garlic、celery 和 lemon 行中每磅
的价格。你不能简单地对价格查找替换,因为可能有其他的产品价格一样,你不希
望错误地“更正”。对于几千行数据,手工操作可能要几小时。
import openpyxl
price_update= {
'Celery':1.19,
'Garlic':3.07,
'Lemon' :1.27
}
wb = openpyxl.load_workbook('produceSales.xlsx')
sheet = wb.active
for index,row in enumerate(sheet.rows):
produce_name = sheet.cell(row = index+1,column =1)
if produce_name in price_update.keys():
sheet.cell(row = index+1,column = 2).value = price_update[produce_name]
wb.save(filename='produceSales1.xlsx')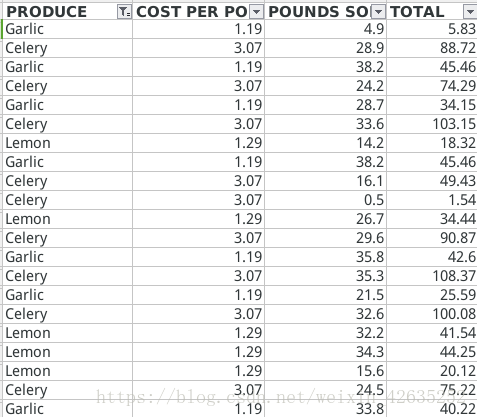
json模块
import json
# 将python对象编码成为json的字符串格式;
d={'name':'fentiao'}
jsonstr = json.dumps(d)
print(jsonstr,type(jsonstr))
l = [1,2,3,4]
jsonli=json.dumps(l)
print(jsonli,type(jsonli))
# 将获取的json字符串解码为python的对象
pythonDict = json.loads(jsonstr)
print(pythonDict,type(pythonDict))
# 将将python对象编码成为json的字符串格式并写入文件中;
with open('json.txt', 'w') as f:
json.dump(d, f)
# 将文件中的json字符串解码为python的对象
with open('json.txt') as f:
json_Dict = json.load(f)
print(json_Dict, type(json_Dict))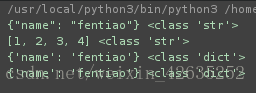
eg:
import json
import string
from random import choice
keys = string.ascii_lowercase
values = string.ascii_letters + string.digits
dict = {choice(keys): choice(values) for i in range(10)}
with open('json.txt', 'w') as f:
# separators = ("每个元素间的分隔符", “key和value之间的分隔符”)
json.dump(dict, f, indent=4, sort_keys=True, separators=(';', '='))