Kmp操作、原理、拓展
注:虽然我是一只菜,才大一。但我是想让萌新们更容易的学会一些算法和思想,所以没有什么专业词语,用的都是比较直白地表达,大佬们可能觉得烦,但是真的对不会的人更有帮助啊。我本人也是菜,大一上学期写的,直接拿过来了,也没检查,有什么错误大佬们赶紧告诉我
先上代码,大佬们可以别看下面了,就当复习一下
package advanced_001;
public class Code_KMP {
public static int getIndexOf(String s, String m) {
if (s == null || m == null || m.length() < 1 || s.length() < m.length()) {
return -1;
}
char[] str1 = s.toCharArray();
char[] str2 = m.toCharArray();
int i1 = 0;
int i2 = 0;
int[] next = getNextArray(str2);
while (i1 < str1.length && i2 < str2.length) {
if (str1[i1] == str2[i2]) {
i1++;
i2++;
} else if (next[i2] == -1) {
i1++;
} else {
i2 = next[i2];
}
}
return i2 == str2.length ? i1 - i2 : -1;
}
public static int[] getNextArray(char[] ms) {
if (ms.length == 1) {
return new int[] { -1 };
}
int[] next = new int[ms.length];
next[0] = -1;
next[1] = 0;
int i = 2;
int cn = 0;
while (i < next.length) {
if (ms[i - 1] == ms[cn]) {
next[i++] = ++cn;
} else if (cn > 0) {
cn = next[cn];
} else {
next[i++] = 0;
}
}
return next;
}
public static void main(String[] args) {
String str = "abcabcababaccc";
String match = "ababa";
System.out.println(getIndexOf(str, match));
}
}
问题:给定主串S和子串 T,如果在主串S中能够找到子串 T,则匹配成功,返回第一个和子串 T 中第一个字符相等的字符在主串S中的序号;否则,称匹配失败,返回 0。
一、引子
原始算法:以主串中每一个位置为开头,与子串第一个元素匹配,若相同,下一个位置和子串下一个位置匹配,如果子串元素全部匹配成功,则匹配成功,找到位置。
非常傻白甜,很明显时间复杂度最差为o(len(s)*len(t))。效率很低,大佬请忽略:
引出KMP算法,概念如下:KMP算法是一种改进的字符串匹配算法,由D.E.Knuth,J.H.Morris和V.R.Pratt同时发现,因此人们称它为克努特——莫里斯——普拉特操作(简称KMP算法)。KMP算法的关键是利用匹配失败后的信息,尽量减少模式串与主串的匹配次数以达到快速匹配的目的。具体实现就是实现一个next()函数,函数本身包含了模式串的局部匹配信息。时间复杂度O(m+n)。(摘自百度百科)
其实就是说,人家kmp算法时间复杂度o(len(s)+len(t)),非常快了,毕竟你不遍历一遍这俩字符串,怎么可能匹配出来呢?我不信还有时间复杂度更低的算法,包括优化也是常数范围的优化,时间已经非常优秀了
二、分析总结
分析:首先,我们要搞明白,原始的算法为啥这么慢呢?因为它在一遍一遍的遍历s和t,做了很多重复工作,浪费了一些我们本该知道的信息。大大降低了效率。
比如t长度为10,s匹配到位置5,如果t一直匹配到了t[8],到[9]才匹配错误,那s已经匹配到了位置14,下一步怎么做呢?接着从位置6开始,和t[0]开始匹配,而s位置6和t[0]甚至后面很大一部分信息我们其实都遍历过,都知道了,原始算法却还要重复匹配这些位置。所以效率极低。
(其实很多算法都是对一般方法中的重复运算、操作做了优化,当我们写出暴力递归后,应分析出我们做了哪些重复运算,然后优化。具体优化思路我会在以后写出来。当我们可以用少量的空间就能减少大量的时间时,何乐而不为呢?)
扯远了,下面开始进入kmp正题。
三、基本操作
首先扯基本操作:
next数组概念:一个字符串中最长的相同前后缀的长度,加一。可能表达的不太好啊,举例说明:abcabcabc
所以next[1]一直到next[9]计算的是’a’,’ab’,’abc’,’abca’,’abcab’直到’abcabcabc’的相同的最长前缀和最长后缀,加一
注意,所谓前缀,不能包含最后一个字符,而后缀,也不能包含第一个字符,如果包含,那所有的next都成了字符串长度,也就没意义了。
比如’a’,最长前后缀长度为0,原因上面刚说了,不包含。
“abca”最长前后缀长度为1,即第一个和最后一个。
“abcab”最长前后缀长度为2,即ab
“abcabc”最长前后缀长度为3,即abc
“abcabca”最长前后缀长度为4,即abca
“abcabcabc”最长前后缀长度为6,即abcabc
萌新可以把next数组看成一个黑盒,我下面会写怎么求,不过现在先继续讲主体思路。
(感觉next数组体现了一个挺重要的思想:预处理思想。当我们不能直接求解问题时,不妨先生成一个预处理的数组,用来记录我们需要的一些信息。以后我会写这方面的专题)
开始匹配了哦:假如主串从i位置开始和子串配,配到了i+j时配不下去了,按原来的方法,应该回到i+1,继续配,而kmp算法是这样的:
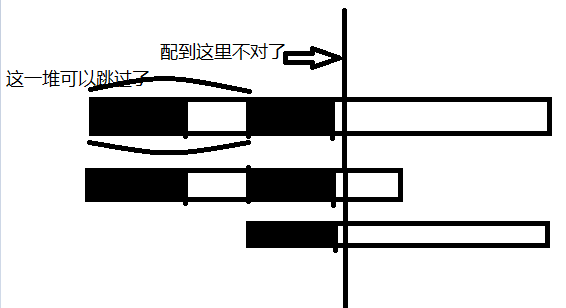
黑色部分就是配到目前为止,前面子串中的最长相同前后缀。匹配失败以后,可以跳过我圈的那一部分开头,从主串的第二块黑色那里开始配了,这些开头肯定配不出来,这就是kmp核心的思想,至于为什么敢跳,等会讲,现在先说基本操作。
根据定义,主串第二块黑部分和子串第一块黑部分也一样,所以直接从我划线的地方往下配就好。
就这样操作,直到最后或配出。
四、原理
原始的kmp操作就是这样,下面讲解原理,为什么能确定跳过的那一段开头肯定配不出来呢?
还是再画一个图来配合讲解吧。(要不然我怕表达不好唉。。好气哟)
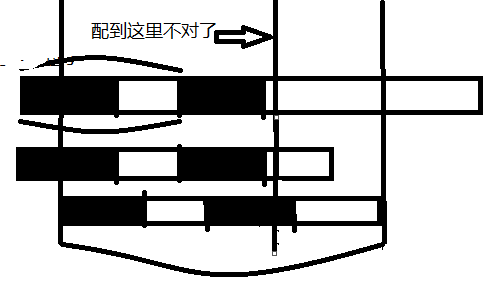
(懒,就是刚才的图改了改)
咱们看普遍情况(注意,是普遍情况,任意跳过的开头位置),随便一个咱们跳过的开头,看看有没有可能配出来呢?
竖线叫abc吧。
主串叫s,子串交t
请看ab线中间包含的t中的子串,它在t中是一个以t[0]为开头,比黑块更长的前缀。
请看ab线中间包含的s中的子串,它在s中是一个以b线前一个元素为结尾,比黑块更长的后缀。
请回想黑块定义:这是目前位置之前的子串中,最长的相同前后缀。
请再想一想我们当初为什么能配到这里呢?
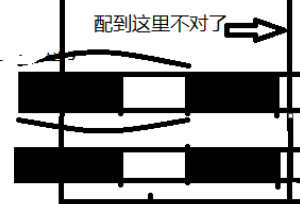
这个位置之前,我们全都一样,所以多长的后缀都是相等的。
其实就是,主数组后缀等于子数组后缀,而子数组前缀不等于子数组后缀,所以子数组前缀肯定不等与主数组后缀,也就是说,当前位置肯定配不出来
这是比最长相同前后缀更长的前后缀啊兄弟。。。所以肯定不相等,如果相等,最长相同前后缀至少也是它了啊,对么?这就是能跳过的原因,这辈子不可能在这里面配出来了哦。
主要操作和原理就这些了。。不知道解释清楚没。
下面解释如何求解next数组:
当然,一个一个看也不是不可以,在子串很短的情况下算法总时间区别不大,但是。。各位有没有一股似曾相识的感觉呢?计算next[x]还是要在t[0]-t[x-2]这个串里找最大相同前后缀啊。还是串匹配问题啊。看操作:

(一切为了code简洁好操作),之后每个位置看看p[i-1]和p[next[i-1]]是不是相等,请回去看图,也就是第一个黑块后面那个元素和第二个黑块最后那个元素,相等,next[i]就等于next[i-1]+1。(求b,看前一个元素的最长前后缀,前一个元素和a看是不是相等。)
若不等,继续往前看,p[i-1]是不是等于p[next[next[i-1]]],就这样一直往前跳。其实现在一看,大家是不是感觉,和s与t匹配的时候kmp主体很像啊?只是反过来跳了嘛。。。原理也是基本一样的,我就不解释了,跳过的部分也不可能配出来,你们自己证吧,不想写了。
五、复杂度分析
下面分析时间复杂度:
主体部分,在主串上的指针,两种情况,要么配了头一个就不对,就往后走了,这时用o(1)排除了一个位置。要么就是,配了n个位置以后配不对了,那不管next数组是多少,主串上的指针总会向后走n个位置的,所以每个位置还是o(1),这样看来,主串长度是len的话,时间复杂度就是o(len)啊。
再看next数组求解的操作,一样的啊,最多就是子串的长度那么多呗。
所以总体时间复杂度o(m+n),原来是o(m*n)啊,向这位大神致敬,想出这么强的算法。
六、kmp拓展题目
(本来想放到树专题讲,但是kmp提供了很好的思路,故在本章讲述kmp方法,在树专题讲一般思路)
输入两棵二叉树A,B,判断B是不是A的子结构。
Oj链接
https://www.nowcoder.com/practice/6e196c44c7004d15b1610b9afca8bd88?tpId=13&tqId=11170&tPage=1&rp=1&ru=/ta/coding-interviews&qru=/ta/coding-interviews/question-ranking
先说一般思路,就一个一个试呗,先在A里找B的根,相等了接着往下配,全配上就行了。
需要注意的是,子结构的定义,好好理解,不要搞错了,不太清楚定义的自己查资料。
下面说利用kmp解此题的思路
Kmp,解决字符串匹配问题,而此题是二叉树匹配问题,所以一般思路是想把树序列化,然后用kmp,但是我们有一个常识,一种遍历不能确定唯一一颗树,这是我们首先要解决的问题。
分析为什么一个序列不能确定呢?给你个序列建立二叉树,比如1 2 3,先序吧(默认先左子树),1是根没问题,2就不一定了,可以是左子树可以是右子树,假如是左子树,那三可放的位置更不确定,这就是原因,我们不知道左子树是空,结束了,该建右子树,还是说,填在左子树。
怎么解决这个问题?
我请教了敬爱的老师这方法对不对,所以肯定没有问题滴。
只要把空也表示出来就好了比如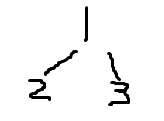
再举一例
在座的各位都是大佬,应该都懂吧。
(因为序列化和重建的方式一样,知道左子树什么时候为空,所以可以确定唯一一颗结构确定的树)
AB树序列化以后,用kmp字符串匹配就行啦
(当然要是为了过oj,就别秀kmp操作了,直接用系统函数,面试再自己写)
整篇结束,code怎么整合,如何操作、kmp的优化,以及篇中提到的算法思想怎么养成以后可能会写。
字数3170
初稿2017/12/20