此文章较为适合我这种初学者
废话不多说直接进入正题
观看如下代码
public class 铜中 {
public static void main(String []args) {
File yf=new File("F:\\123");
try {
yf.createNewFile();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
你能在里指定的目录下发现一个这样的文件
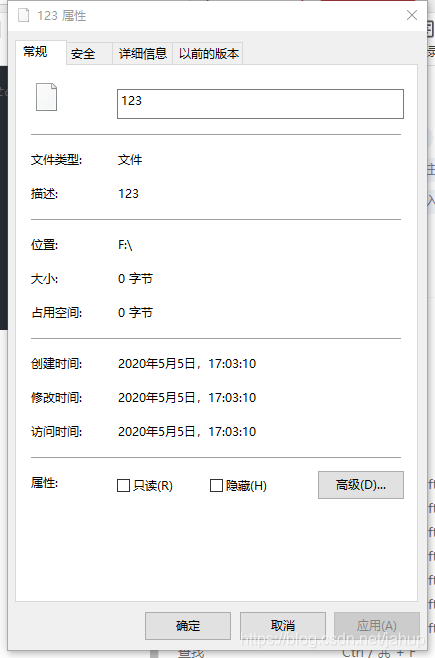
因为我们在创建时没有规定文件类型
如果将新建对象的代码改为
File yf=new File("F:\\123.txt");
出现的就是如下结果
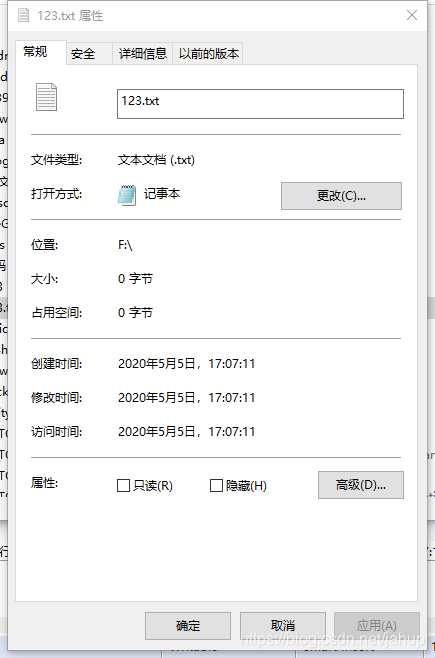
可能有同学会注意到代码中用到了try catch来捕获异常,如果你尝试过会发现不加的话代码是会报错的,为什么了?如果我们创建的目录不存在,或者说在多线程文件被中途删除了,代码就会抛出异常;
我们可以创建文件,当然可以创建文件夹,可能有同学会问,那文件夹的格式该填什么,开发者们想到了这个问题,故重新定义了个方法创建文件夹
看看如下代码
public class 铜仁一中 {
public static void main(String []args) {
File yf=new File("F:\\123.txt");
yf.mkdir();
}
}
你会发现在指定目录下出现了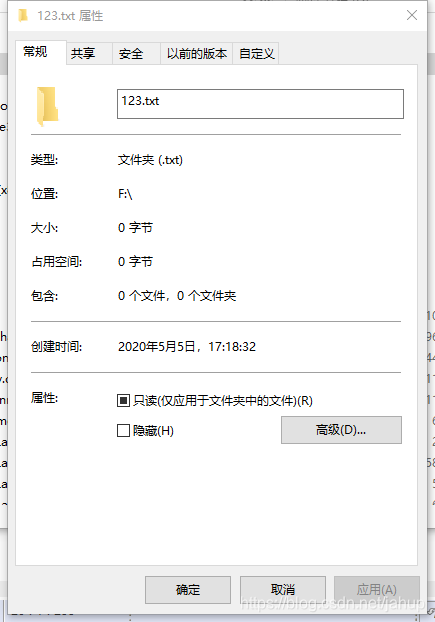
很明显,文件名末尾的“.txt”没有对文件类型造成任何影响,细心的同学会发现代码中没有捕获异常的操作,为什么mkdir就不用了,因为人们在定义这个方法的时候考虑到了会抛出异常的情况,并在方法体内对其进行了处理,故我们不需要考虑
可以创建一个文件夹,那可以创建多重吗,结果是肯定的
public class 杨帆 {
public static void main(String []args) {
File yf=new File("F:\\123.txt\\我喜欢你");
yf.mkdirs();
}
}
你会发现在指定目录下多了一个多重文件夹(记住把原来的123.txt删掉,如果检测到重复是不会创建的)
可能有同学觉得一个个去翻文件确认是否创建成功会很麻烦,这里我们提供一种更好的方法
public boolean mkdirs() {
if (exists()) {
return false;
}
if (mkdir()) {
return true;
}
File canonFile = null;
try {
canonFile = getCanonicalFile();
} catch (IOException e) {
return false;
}
File parent = canonFile.getParentFile();
return (parent != null && (parent.mkdirs() || parent.exists()) &&
canonFile.mkdir());
}
上面是mkdirs的源码,可以看见它是boolean类型的,这里如果他创建成果会返回true,反之则是false,我们只需要根据其返回值在编写程序时做相应处理就行(createNewFile 因文件存在创建失败不会抛出异常)
上面是创建的常规操作,当然能创建就能删
public class 杨帆 {
public static void main(String []args) {
File yf=new File("F:\\123.txt");
yf.mkdirs();
yf.delete();
}
}
你会发现指定目录下是没有任何改变的,因为它创建了,然后又删了,但看看如下代码
public class 行行行 {
public static void main(String []args) {
File yf=new File("F:\\123.txt\\我喜欢你");
yf.mkdirs();
yf.delete();
}
}
运行后你会发现仍然存在123.txt这个文件夹,为什么了,因为delete默认只删最底层的文件,该怎么办了
public class 杨帆{
public static void main(String []args) {
File yf=new File("F:\\123.txt\\我喜欢你");
yf.mkdirs();
File yjl=new File("F:\\123.txt");
yf.delete();
yjl.delete();
}
}
分步删即可;
现在我们能增能删,怎么查了
所先我们要确定一个文件是否存在
如下代码
public class 杨帆 {
public static void main(String []args) {
File yf=new File("E:\\eclipse");
System.out.println(yf.exists());
}
}

因为我的E:\eclipse确实存在,所以返回true
接下来就是查询
public class 杨帆 {
public static void main(String []args) {
File yf=new File("E:\\eclipse");
if(yf.exists()) {
System.out.println(yf.length());//所占大小以字节为单位
System.out.println(yf.getName());//名字
System.out.println(yf.getParent());//文件的上一层是谁
System.out.println(yf.getPath());//路径
System.out.println(yf.getFreeSpace());//空余的空间
System.out.println(yf.getTotalSpace());//总空间
}
}
}
下面介绍一个递归方法
所先必须得知道这几个方法
public boolean isDirectory()//判断是否是一个文件夹
public File[] listFiles()//返回文件夹里所有字文件
public boolean isFile()//判断是否是一个标准文件
我们知道java是无法删除一个非空文件的,这里假设我们要删除一个文件夹
public static void deleteall(File x) {
if(x.isDirectory()) {
//如果是文件夹
File []y=x.listFiles();//将文件夹里文件全部分出来
for(int i=0;y!=null&&i<y.length;i++) {
//依次判断
if(y[i].isDirectory())//如果是文件夹,递归下去
deleteall(y[i]);
else//不是直接删除文件
y[i].delete();
}
}
x.delete();//删除该文件夹
}
看了这么多,我们好像还是不知道什么是oi流,不过值得高兴的是我相信前面的类容我们应该都能消化掉,至少我们看懂了。那么下面我们介绍什么是oi流;
字节输入流(i流)(input流):
什么是输入流了
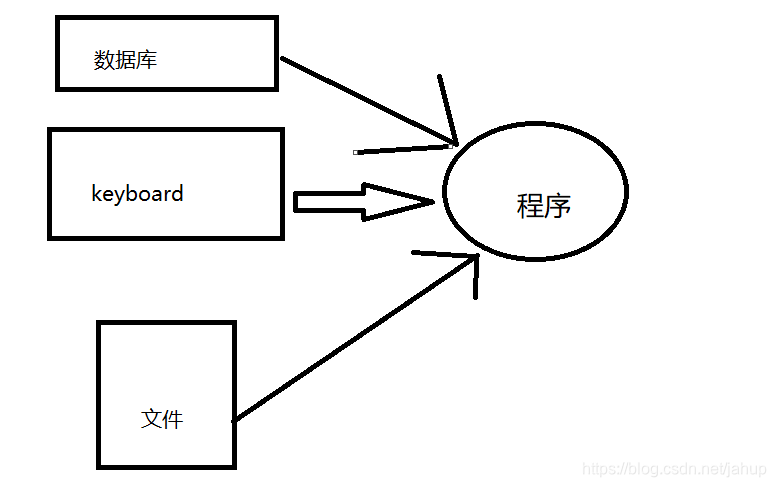
如图,在运行一个程序时,程序需要根据一些数据做出相应的反馈,好比我们在打字的时候(拼音输入),为什么我们按下‘wo’,会出现‘我’这个字了,因为你的输入法检测到了你的键盘输入,并根据其做出了相应的反馈。假设有时候我们为了好看,打算给QQ换一个主题,所先我们要下载这个主题,然后设定它。为什么需要下载了,因为我们需要这个文件的数据,为什么需要设定了,因为设定(假设是手机,那么就是通过触屏)就是给程序传递数据,也是一种输入流,设定完成后,程序根据你的设定读取相应的文件,这也是输入流。我们说的直白一点,数据从其他任何地方导入某个运行的程序就可以叫输入流。
我相信通过上面的例子,我们对输入流是什么有了大致的了解,那具体怎么实现了;
下面我们介绍几个类
FileInputStream,BufferedInputStream。
这2个类有相同的父类InputStream
下面我们先看看FileInputStream
public class 杨帆 {
public static void main(String []args) {
File yjl=new File("D:\\two.txt");
try {
FileInputStream yf=new FileInputStream("D:\\one.txt");
FileInputStream yf2=new FileInputStream(yjl);
//FileInputStream yf2=new FileInputStream(new File("D:\\two.txt"));也可以这样写
} catch (FileNotFoundException e) {
// TODO Auto-generated catch block
System.out.println("文件不存在 ");
}
}
}
如上代码我们通过2种方式进行了对象实例化(通过路径,通过File类)但一般推荐用第二种方法,为什么了,看如下代码
public class 行行行 {
public static void main(String []args) {
try {
File yjl=new File("D:\\two.txt");
if(yjl.exists()&&yjl.length()>0) {
FileInputStream yf2=new FileInputStream(yjl);
}
} catch (FileNotFoundException e) {
// TODO Auto-generated catch block
System.out.println("文件不存在 ");
}
}
}
相信大家已经知道为什么了
下面我们学习几种方法
public int read();//读取一个字节,注意 返回值是int(如果原文件是通过ascll编辑的,可以同过强转转化为字符)(如果返回值为-1,代表文件读完了)
public void close()//切断文件与程序的连接
当官我们反复调用read时,它会按顺序读取文件,这个要怎么理解了
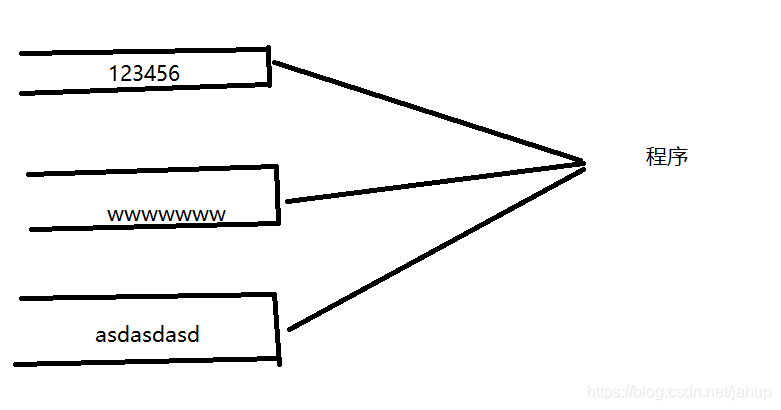
如图假设每个文件是一个水厂,当我们FileInputStream实例化一个文件时,就架起了水管,我们可以通过一系列方法获取水管里的水,但当水流出去了,假设我们通过read读取了1号水管的6,下一次再读取1号水管时就是5.close就是把水管切断,如果想再次调用该文件的数据就需要从新FileInputStream实例化该文件的对象,此时又会从头读取该文件。因为缓冲区是有限的,对于不需要的水管要及时关闭,避免占用资源;
当然一个个读确实很麻烦
看看如下代码
public class 行行行 {
public static void main(String []args) {
File yf=new File ("D:\\one.TXT");
try {
FileInputStream yjl=new FileInputStream(yf);
byte x[]=new byte [20];
int all=yjl.read(x);
for(int i=0;i<all;i++)
System.out.print((char)x[i]);
} catch (FileNotFoundException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (Exception e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
输出结果为
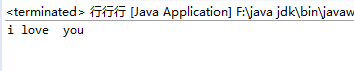
让我们看看这段代码
yjl.read(x);
它的是通过这个方法实现的
public int read(byte b[]) throws IOException {
return readBytes(b, 0, b.length);
}
只不过readBytes方法我们无法访问而已
,此方法从该输入流读取高达byte.length(传入数组的大小)字节的数据到字节数组。 此方法将阻塞,直到某些输入可用。
字节输出流(o流)(output)
字节输出流和字节输入流一样由2个类来实现
1.FileOutputStream
2.BufferedOutputStream
它们也同样继承于同一个父类(OutputStream)
public class 杨帆 {
public static void main(String []args) {
String data ="我讨厌你";
try {
FileOutputStream yf=new FileOutputStream ("D:\\one.TXT");
byte []all=data.getBytes();
yf.write(all);//wirte函数在路径不存在时会自动创建路径
yf.close();
} catch ( IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
此代码会在D:\one.TXT路径下写入“我讨厌你”的ASCII码,如果是采用ASCII的编码的话,则文件中会出现文字,如果不是则是乱码;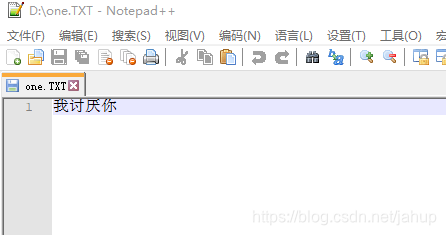
上面是ASCII的编码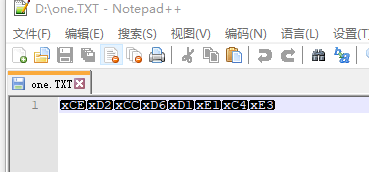
如果换成utf-8 就成了如上乱码。
如果我们反复运行代码,你会发现文本没有任何变化,为什么了,因为
FileOutputStream ("D:\\one.TXT");
会默认删除文件中的原数据
如果我们将代码改成这样
public class 行行行 {
public static void main(String []args) {
String data ="我讨厌你";
try {
//变化的地方
FileOutputStream yf=new FileOutputStream ("D:\\one.TXT",true);//改为false 和FileOutputStream()一样
byte []all=data.getBytes();
yf.write(all);
yf.close();
} catch ( IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
出现的就是如下结果
可见构造方法被重写了,我们需要根据自己的需求调用相应的构造方法。
通过上面FileOutputStream,FileInputStream的学习,大家对文件的操作应该有一些了解,相信有些爱折腾的同学会发现FileOutputStream FileInputStream 碰到大点的文件时,执行效率会非常的慢,所以接下来我们引入BufferedOutputStream BufferedIutputStream
BufferedIutputStream:
看看如下代码:
public class 行行行 {
public static void main(String []args) {
File yf=new File("E:\\steam\\steam.exe");
long start=System.currentTimeMillis();
try {
FileInputStream yjl=new FileInputStream(yf);
BufferedInputStream yf1=new =
BufferedInputStream(yjl);
byte []x=new byte[500];
int all=0;
while((all=yjl.read())!=-1) {
System.out.println(all);
}
yjl.close();
long end=System.currentTimeMillis();
System.out.println(end-start);
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}

运行时间为
但我将代码改为
public class 行行行 {
public static void main(String []args) {
File yf=new File("E:\\steam\\steam.exe");
long start=System.currentTimeMillis();
try {
FileInputStream yjl=new FileInputStream(yf);
BufferedInputStream yf1=new BufferedInputStream(yjl);
byte []x=new byte[500];
int all=0;
while((all=yf1.read())!=-1) {
//这里进行了修改
System.out.println(all);
}
yjl.close();
long end=System.currentTimeMillis();
System.out.println(end-start);
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}

时间几乎少了一倍
看完上面的码你可能对这2段代码存有疑惑
FileInputStream yjl=new FileInputStream(yf);
BufferedInputStream yf1=new BufferedInputStream(yjl);
为什么要这样
这里我们看看BufferedInputStream的源码
public BufferedInputStream(InputStream in)
它的构造方法是这样的,所以传入的参数需是InputStream(或它的子类型)类型
至于BufferedOutputStream我们直接看下面的例子
public class 可爱杨帆 {
public static void main(String []args) {
File yf=new File("E:\\steam\\steam.exe");
File yjl=new File("D:\\newsteam.exe");
try {
InputStream yf1=new FileInputStream(yf);
OutputStream yjl1=new FileOutputStream(yjl);
BufferedInputStream yf2=new BufferedInputStream(yf1);
BufferedOutputStream yjl2=new BufferedOutputStream(yjl1);
byte che[]=new byte[1024*1024];
int all=0;
while((all=yf2.read(che))!=-1) {
yjl2.write(che);
//此段代码可以改为yjl2.write(che,0,all)0-all代表拷贝che数组的长度,这种写法更加高效
}
//记得close小编偷个懒
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
它的学习可以类比,此程序的代码是拷贝一份文件
效果图如下
原文件
拷贝的

字节流可以读取一切文件;
接下来我们看看字符流,它只可以读取存文本文件,并且帮助我们处理了乱码问题。
它通过下面4个类来实现
filereader
bufferedreader
bufferedwriter
filerwriter
它们都继承于父类reader,writer;
filereader
public int read(char cbuf[])
可以看到它的一个read方法参数是char型,为什么了,因为诸如汉字它无法用一个字节表示,为了能读到整个汉字,只能用char
public class 杨帆 {
public static void main(String []args) {
File yf=new File("D:\\one.txt");
File yjl=new File("D:\\two.txt");
try {
FileReader yf1=new FileReader(yf);
char []xx=new char[30];
int all=yf1.read(xx);
System.out.println(xx);
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}

效果如上,因为我在文本中设定了3种语言,它也原封不动输出了。
filerwriter
public class 杨帆 {
public static void main(String []args) {
File yf=new File("D:\\one.txt");
File yjl=new File("D:\\two.txt");
String pp=" 你真的很漂亮";
try {
FileWriter xx=new FileWriter(yf,true);
xx.write(pp);
pp.close();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
根据前面的学习,代码的效果是显而易见。
bufferedreader
bufferedwriter
可以类比学习,我就不做过多说明
如有错误,欢迎指出,如有疑问,请下方留言