原博地址:https://blog.csdn.net/red_stone1/article/details/77929889
上节课我们主要介绍了逻辑回归,以输出概率的形式来处理二分类问题。我们介绍了逻辑回归的Cost function表达式,并使用梯度下降算法来计算最小化Cost function时对应的参数w和b。通过计算图的方式来讲述了神经网络的正向传播和反向传播两个过程。本节课我们将来探讨Python和向量化的相关知识。
1. 向量化
深度学习算法中,数据量很大,在程序中应该尽量减少使用loop循环语句,而可以使用向量运算来提高程序运行速度。
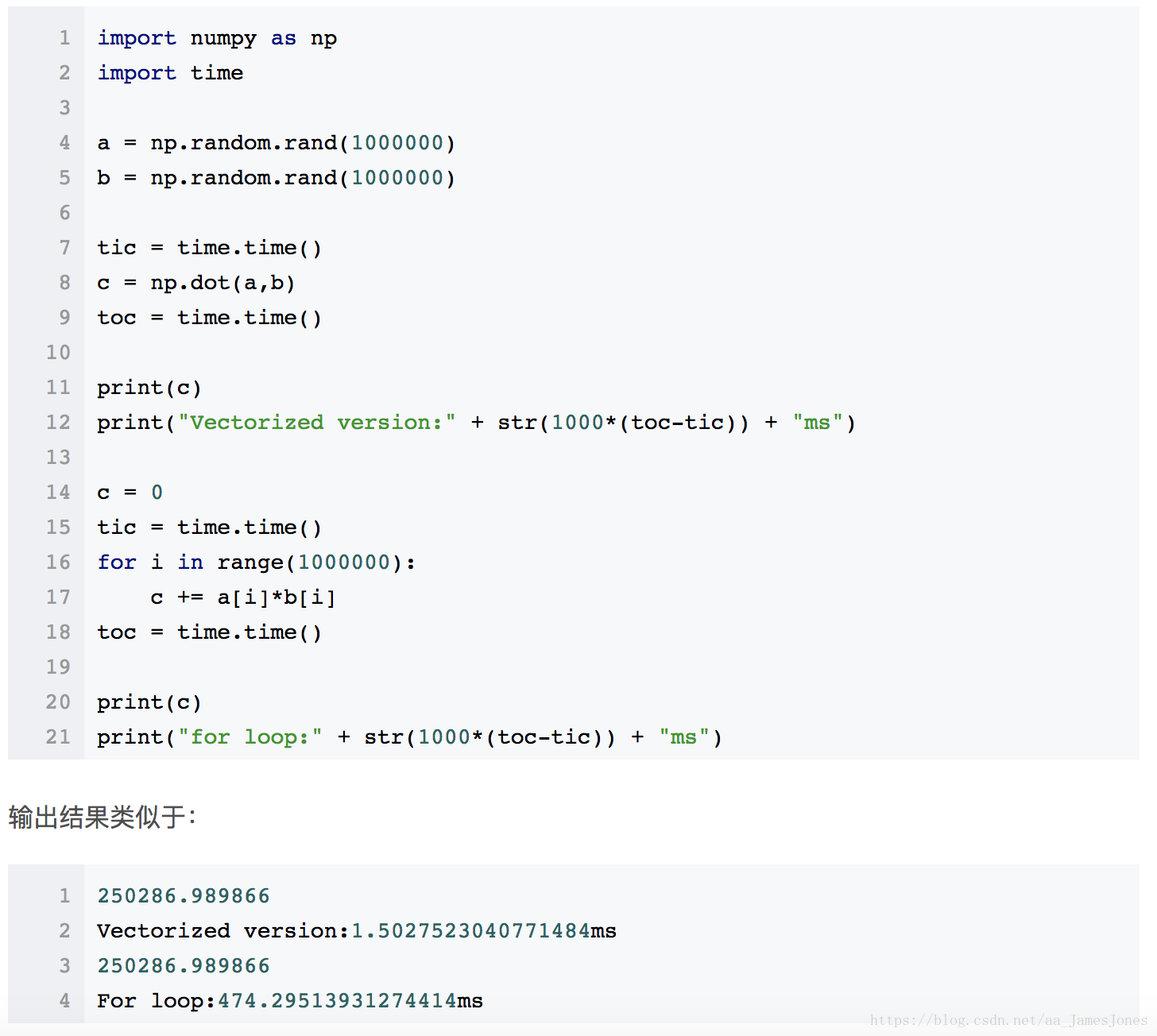
向量化(Vectorization)就是利用矩阵运算的思想,大大提高运算速度。例如下面所示在Python中使用向量化要比使用循环计算速度快得多。
(

现在处理的是一维数组,得到的是两数组的內积(1*4+2*5+3*6=32)
如果是二维数组(矩阵)之间的运算,则执行的是矩阵间的乘法运算

矩阵乘法符合结合律,即(A*B)*C = A*(B*C)
)
从程序运行结果上来看,该例子使用for循环运行时间是使用向量运算运行时间的约300倍。因此,深度学习算法中,使用向量化矩阵运算的效率要高得多。
为了加快深度学习神经网络运算速度,可以使用比CPU运算能力更强大的GPU。事实上,GPU和CPU都有并行指令(parallelization instructions),称为Single Instruction Multiple Data(SIMD)。SIMD是单指令多数据流,能够复制多个操作数,并把它们打包在大型寄存器的一组指令集。SIMD能够大大提高程序运行速度,例如python的numpy库中的内建函数(built-in function)就是使用了SIMD指令。相比而言,GPU的SIMD要比CPU更强大一些。
2. 向量化的更多例子
上一部分我们讲了应该尽量避免使用for循环而使用向量化矩阵运算。在python的numpy库中,我们通常使用np.dot()函数来进行矩阵运算。
我们将向量化的思想使用在逻辑回归算法上,尽可能减少for循环,而只使用矩阵运算。值得注意的是,算法最顶层的迭代训练的for循环是不能替换的。而每次迭代过程对J,dw,b的计算是可以直接使用矩阵运算。
3. 向量化逻辑回归

4. 向量化逻辑回归的梯度输出



5. Python中的广播
下面介绍使用python的另一种技巧:广播(Broadcasting)。
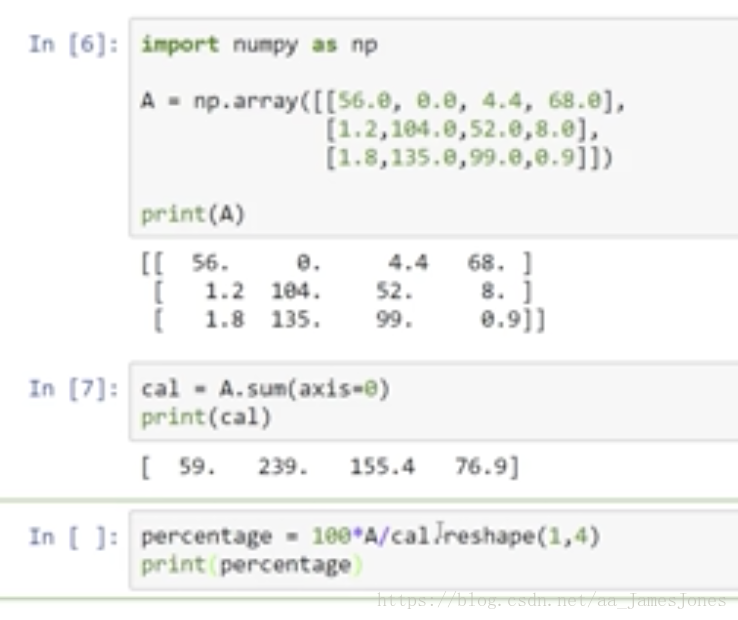

简而言之,就是python中可以对不同维度的矩阵进行四则混合运算,但至少保证有一个维度是相同的。下面给出几个广播的例子,具体细节可参阅python的相关手册,这里就不赘述了。

值得一提的是,在python程序中为了保证矩阵运算正确,可以使用reshape()函数来对矩阵设定所需的维度。这是一个很好且有用的习惯。
6. 关于python/numpy向量的说明
接下来我们将总结一些python的小技巧,避免不必要的code bug。
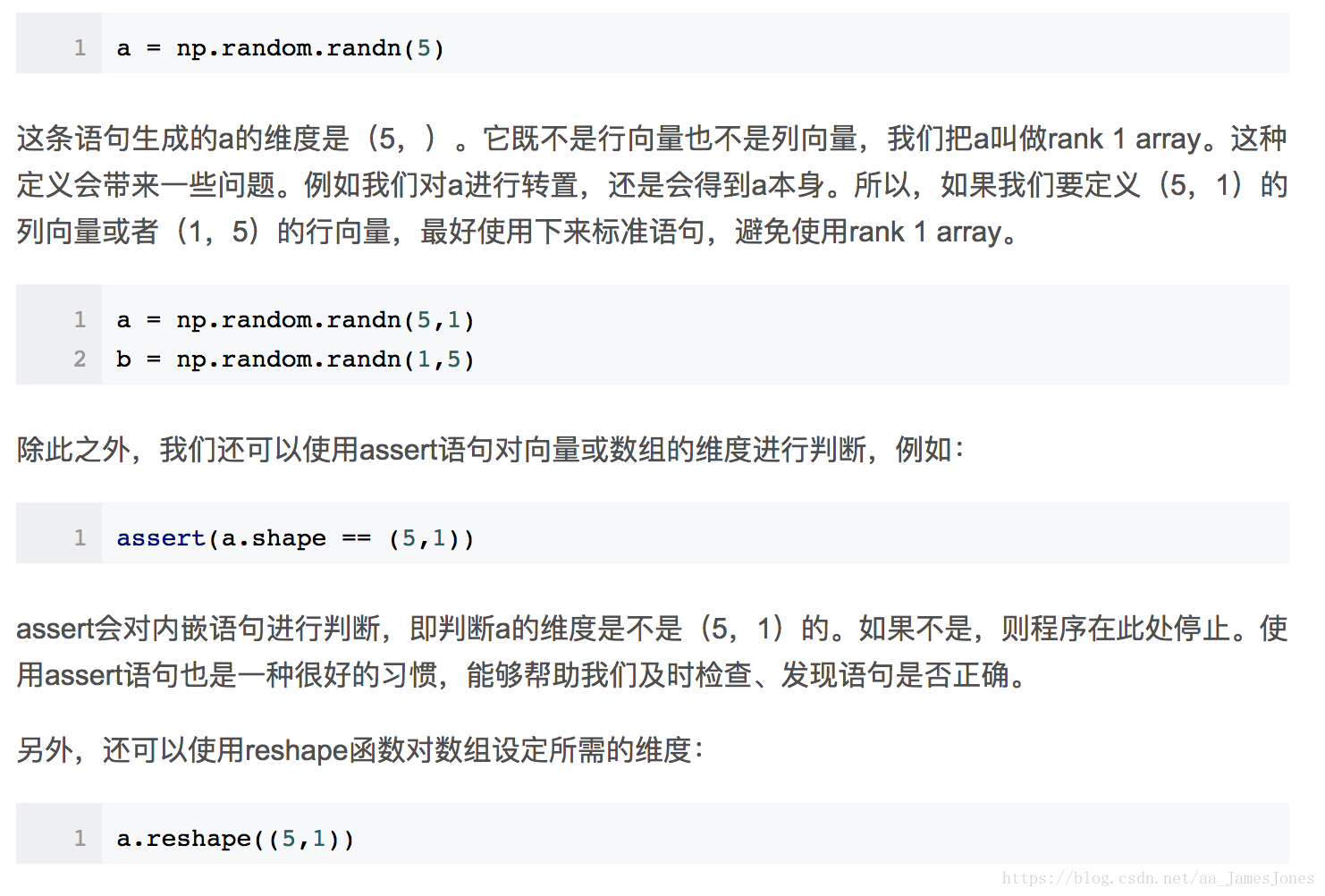
python中,如果我们用下列语句来定义一个向量:
7. Jupyter/iPython Notebook快速指南
Jupyter notebook(又称IPython notebook)是一个交互式的笔记本,支持运行超过40种编程语言。本课程所有的编程练习题都将在Jupyter notebook上进行,使用的语言是python。
关于Jupyter notebook的简介和使用方法可以看我的另外两篇博客:
8. 逻辑回归的代价函数的解释(选修)
在上一节课的笔记中,我们介绍过逻辑回归的Cost function。接下来我们将简要解释这个Cost function是怎么来的。


9. 总结
本节课我们主要介绍了神经网络基础——python和向量化。在深度学习程序中,使用向量化和矩阵运算的方法能够大大提高运行速度,节省时间。以逻辑回归为例,我们将其算法流程包括梯度下降转换为向量化的形式。同时,我们也介绍了python的相关编程方法和技巧。