转载http://www.sohu.com/a/128794834_211120
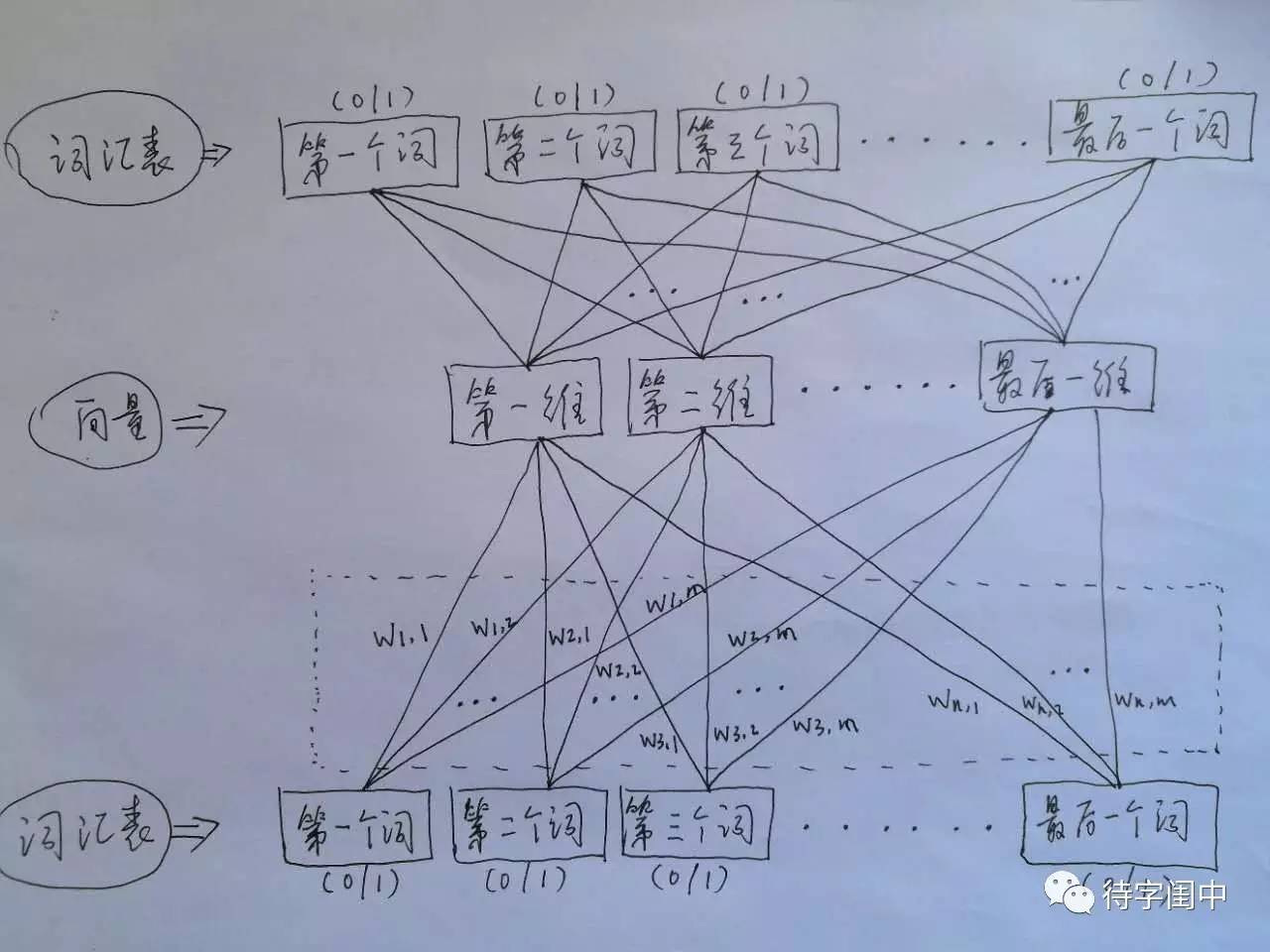
Word2Vec 的训练模型,看穿了,是具有一个隐含层的神经元网络(如下图)。它的输入是词汇表向量,当看到一个训练样本时,对于样本中的每一个词,就把相应的在词汇表中出现的位置的值置为1,否则置为0。它的输出也是词汇表向量,对于训练样本的标签中的每一个词,就把相应的在词汇表中出现的位置的值置为1,否则置为0。那么,对所有的样本,训练这个神经元网络。收敛之后,将从输入层到隐含层的那些权重,作为每一个词汇表中的词的向量。比如,第一个词的向量是(w1,1 w1,2 w1,3 ... w1,m),m是表示向量的维度。所有虚框中的权重就是所有词的向量的值。有了每个词的有限维度的向量,就可以用到其它的应用中,因为它们就像图像,有了有限维度的统一意义的输入。
训练 Word2Vec 的思想,是利用一个词和它在文本中的上下文的词,这样就省去了人工去标注。论文中给出了 Word2Vec 的两种训练模型,CBOW (Continuous Bag-of-Words Model) 和 Skip-gram (Continuous Skip-gram Model)。
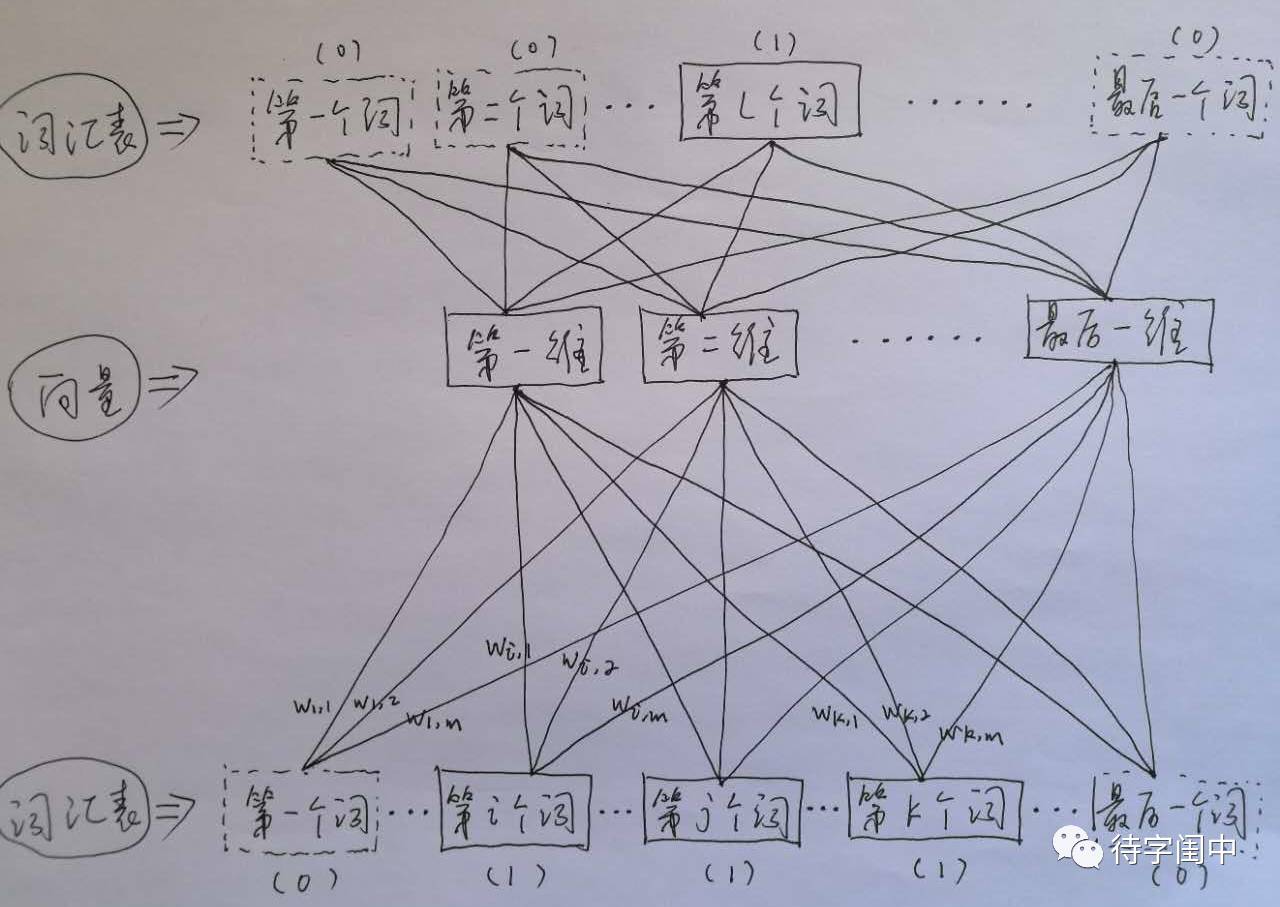
首先看CBOW,它的做法是,将一个词所在的上下文中的词作为输入,而那个词本身作为输出,也就是说,看到一个上下文,希望大概能猜出这个词和它的意思。通过在一个大的语料库训练,得到一个从输入层到隐含层的权重模型。如下图所示,第l个词的上下文词是i,j,k,那么i,j,k作为输入,它们所在的词汇表中的位置的值置为1。然后,输出是l,把它所在的词汇表中的位置的值置为1。训练完成后,就得到了每个词到隐含层的每个维度的权重,就是每个词的向量。
Word2Vec 代码库中关于CBOW训练的代码,其实就是神经元网路的标准反向传播算法。

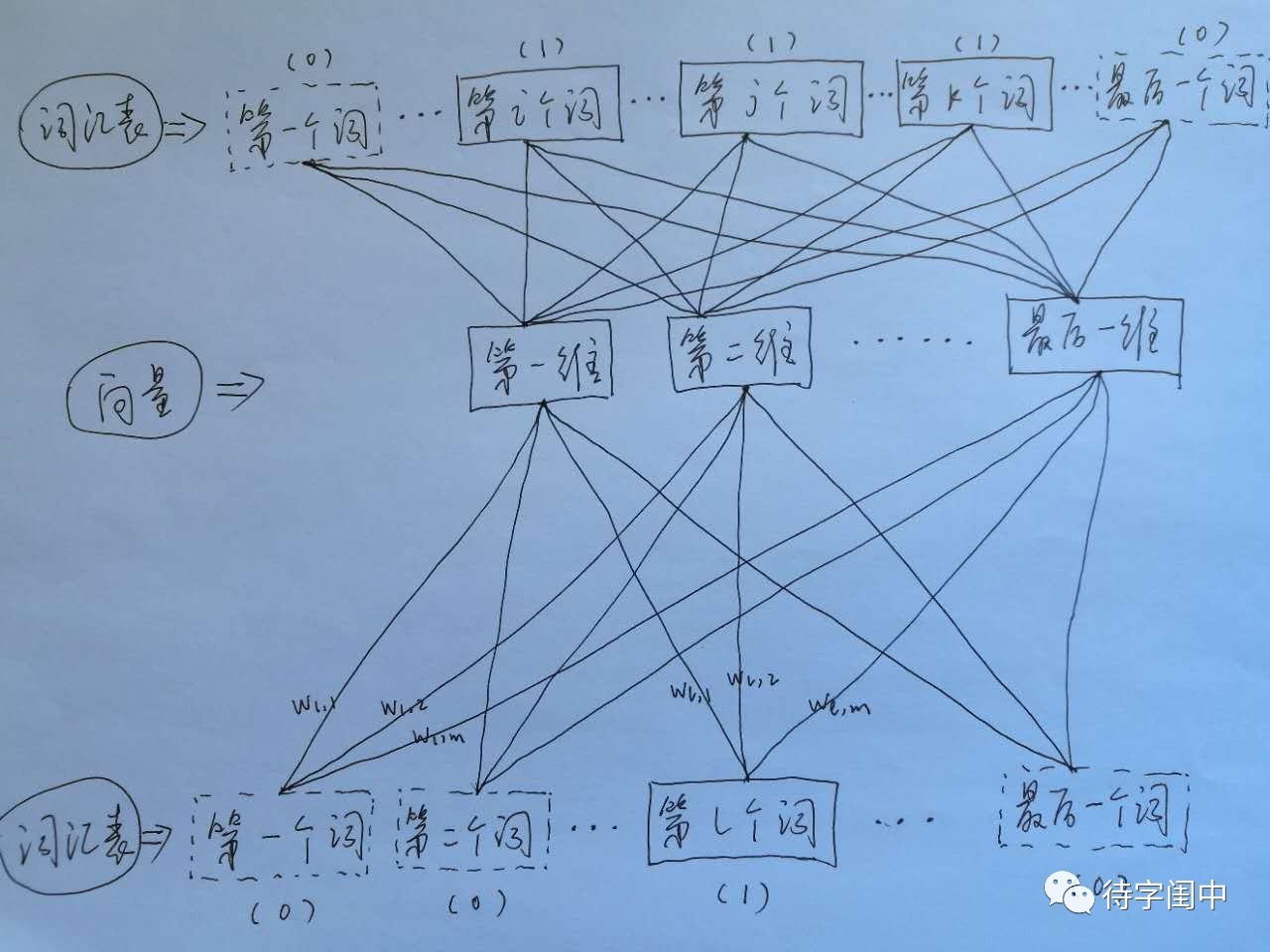
接着,看看Skip-gram,它的做法是,将一个词所在的上下文中的词作为输出,而那个词本身作为输入,也就是说,给出一个词,希望预测可能出现的上下文的词。通过在一个大的语料库训练,得到一个从输入层到隐含层的权重模型。如下图所示,第l个词的上下文词是i,j,k,那么i,j,k作为输出,它们所在的词汇表中的位置的值置为1。然后,输入是l,把它所在的词汇表中的位置的值置为1。训练完成后,就得到了每个词到隐含层的每个维度的权重,就是每个词的向量。
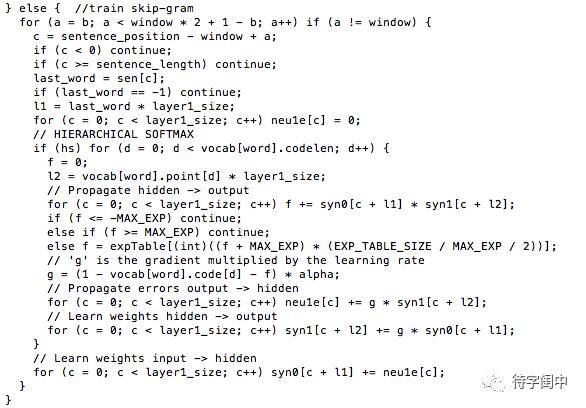
Word2Vec 代码库中关于Skip-gram训练的代码,其实就是神经元网路的标准反向传播算法。