词向量
one-hot
在Word2vec出现之前,在nlp中最常用的是one-hot(独热)编码,先来解释一下什么是独热的编码:假设我们数据集为,“今天天气特别晴朗”,“六月的天气是多变的”,对应词库{“今天”,“天气”,“特别”,“晴朗’,“六月”,“是”,“多变”}。
那么每个词对应的one-hot词向量就是:
今天:{1,0,0,0,0,0,0}
天气:{0,2,0,0,0,0,0}
特别:{0,0,1,0,0,0,0}
晴朗:{0,0,0,1,0,0,0} 等等
这样我们可以看出one-hot编码的一些特点:
1、词向量的维度是和词库的大小一致
2、每一维的位置代表词的位置(不是词在文中的位置,是词在词库中的位置)只有对应位置有值,、值的大小代表该词在文本出现的次数,其他位置为0;
扫描二维码关注公众号,回复:
9643489 查看本文章

这样我们可以看出one-hot编码的一些缺点:
1、稀疏的表示
我们的数据集往往有成千上万的词,根据one-hot编码的特点每个词的词向量都有上万维,而且只有其中一维有值,其他位置为0。
2、这种对编码对词表达的能力很弱,基本上没有包含词义在里面。
word2vec
我们先不谈word2vec的原理,先看一下由word2vec计算出来的词向量有什么特点:
今天:{0.235,0.145,0.287,0.264}
天气:{0.113,0.212,0.185,0.235}
特别:{0.825,0.213,0.212,0.336}
晴朗:{0.32,0.655,0.412,0.251}
第一、每一个维度都有值,是稠密的表示
假设现在有一个八维的词向量那么使用one-hot编码只能表示8个词,而使用word2vec的这种表示方式可以表示无数个词
第二 word2vec计算出的词向量包含词义信息,也就是词义相近,那么词向量之间的距离相近
相对于one-hot,我们一般称word2vec的这种编码方式为分布式的编码
word2vec详解
想要了解word2vec首先要明白它的一个基本原理:在一句话中对于每个词与其他词之间有这么一种现象:两词离得越近,词义相似度越高。例如:
”我们在训练一个非常有意思的nlp模型。”这一句话中,“我们”和“nlp”这两个词的相似度要小于“nlp”与“模型”之间的相似度,这也就说明一个词的含义是与周围几个词有很大的关系。所以根据这种关系我们设计里两个模型:
Skip-gram:利用当前单词预测周围单词。
CBOW:利用周围单词预测当前单词。
当前比较流行的是使用Skip-gram模型,所以下面重点介绍这种模型的原理
Skip-gram
Skip-gram的主要思想是:根据当前词预测周围词,还是举个例子说明吧:
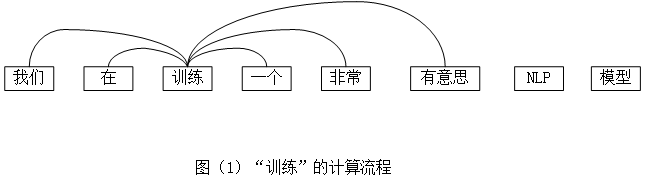
现在有这样的一句话:”我们在训练一个非常有意思的nlp模型”,假设对“训练”这个词进行计算,那么计算过程就是,如图(1),计算周围词出现的概率:
p(我们∣训练),
p(在∣训练),
p(一个∣训练),
p(非常∣训练),
p(有意思∣训练)...并且要把这个概率最大化,也就是MLE的思想(不了解的同学先去了解一下MLE)。
对于每个词我们都进行这样的计算,假设我们考虑周围2个单词那么这句话的计算流程就是:
p(在∣我们),
p(训练∣我们),
p(我们∣在),
p(训练∣在) ,
p(一个∣在),
p(我们∣训练),
p(在∣训练),
p(一个∣训练),
p(非常∣训练)...
我们一般把当前词叫做中心词,周围的词叫做上下文词(context),那么我们把计算流程写成数学公式就是:
argmax∏w∈Text∏c∈context(w)p(c∣w;θ)
进行简单的转化为:
argmax∑w∈Text∑c∈context(w)logp(c∣w;θ)
也就是说我们输入大量的数据集到模型进行训练,不断的最大化目标函数,优化参数。在这里我们的参数是:
θ
简单介绍一下
θ :
θ是有两个矩阵组成
U和
V,也就是
θ=[U,V]
U表示的是每个词作为中心词时的词向量如图(2):

由图(2)可知每一行都代表这每个词的词向量,也就是我们在训练时不断优化每个词对应的词向量。K表示的是词向量的维度,V表示词库的大小。
V和U是一模一样的,也是个矩阵,每一行代表着单词作为上下文时的向量

具体最后
θ是用
U还是
V我们一会再说
根据上面的解释我们了解了skip-gram的目标函数是:
argmax∑w∈Text∑c∈context(w)logp(c∣w;θ)
也就是最大化训练数据的当前词与上下文词之间的概率
以计算
p(在∣我们)为例:
就是最大化“我们”作为中心词,“在”作为上下文词的概率,“我们”作为中心词时的词向量为:
V(我们),“在”作为上下文词的词向量为
U(在),我们知道两个向量的内积表示向量之间的关系:而模型的目的是最大化此时的“我们”和“在”之间的关系。因此也就是最大化
V(我们)和
U(在)的内积:
p(在∣我们)是一个概率的形式,所以我们还要除以“我们”作为中心词时所有可能发生的情况。:
p(在∣我们)=∑dV(我们)⋅U(d)V(我们)⋅U(在)
d表示在词库中除了“在”其他所有词
由于这样计算出的数字比较大,再改变一下形式:
p(在∣我们)=∑de(V(我们)⋅U(d))e(V(我们)⋅U(在))
最后我们在扩展到所有词的情况:
p(c∣w;θ)=∑de(V(w)⋅U(d))e(V(w)⋅U(c))
代入目标函数:
argmax∑w∈Text∑c∈context(w)log∑de(V(w)⋅U(d))e(V(w)⋅U(c))
=
argmax∑w∈Text∑c∈context(w)V(w)⋅U(c)−log∑de(V(w)⋅U(d))
目标函数既然有了,下面就是采用最常用的随机梯度下降法求梯度,然后优化参数。一会做一个求梯度的过程。
当然,这里还有一个问题哈:从公式中可以看出每计算一个词的概率时,都得计算中心词与词库中所有的词的一个内积,这样计算量是非常大的。下面我们讲一下解决方式
目标函数的转化
上面讲到skip-gram的目标函数是最大化
p(c∣w;θ)现在我们换一种思维方式,也就是
p(D=1∣w1,w2)和
p(D=0∣w1,w2),他们表示的是什么意思呢?
p(D=1∣w1,w2;θ)指的是
w1,w2是上下文词的概率
p(D=0∣w1,w2;θ)指的是
w1,w2不是上下文词的概率
那么我们的目标就是 :
w1,w2作为上下文词时,最大化
p(D=1∣w1,w2;θ)
w1,w2不是上下文词时,最大化
p(D=0∣w1,w2;θ)
根据概率的性质:
p(D=1∣w1,w2;θ)+
p(D=0∣w1,w2;θ)=1
这里我们采用逻辑回归来做目标函数:
p(D=0∣w1,w2;θ)=1+e(−Uwi⋅Vwi)1
因此我们的目标函数可以写成:
argmax∏(w.c)∈Dp(D=1∣wi,ci;θ)∏(w.c)∈Dp(D=0∣wi,ci;θ)
D表示
w作为中心词时上下文词的集合,我们称为正样本
D表示
w作为中心词时不是其上下文词的集合,我们称为负样本
将公式展开为:
argmax∏(w.c)∈D1+e(−Uwi⋅Vwi)1∏(w.c)∈D(1−1+e(−Uwi⋅Vwi)1)
化简:
argmax∑(w.c)∈Dlogσ(Vw⋅Uc)+∑(w.c)∈Dlogσ(−Vw⋅Uc)
负采样
在这里我们考虑一个问题:
D和
D在数据集中的分布问题,其实很明显我们可以看出随着数据集的增加
D要远大于
D,也就是负样本要比正样本多的多,y也就是在计算
∑(w.c)∈Dlogσ(−Vw⋅Uc)时比较麻烦。因此我们使用的是负采样。
负采样:也就是在执行一次正样本的计算时,我们不是计算全部的
D集合中的数据,而是随机的选取一部分,这样就可以减少大量的计算量。当然
D集合中的数据有很多都是噪音,所以减少一部分的计算结果也不会太差。
因此目标函数转变成:
argmaxφ(θ)=
argmax∑(w.c)∈D[logσ(Vw⋅Uc)+∑d∈N(w)logσ(−Vw⋅Ud)]
c: 表示
w作为中心词时的上下文词
N(w): 表示从词库中随机采样出的不是
w的上下文词的集合
d: 表示从词库中随机采样出的不是
w的上下文词
求参数梯度
ok既然我们已经得出了目标函数,那么下一步就是优化参数这里采用的是梯度下降法,所以我们分别来计算对参数
Uc、
Ud和
Vw的梯度
求参数
Uc的梯度结合逻辑回归的公式:
∂Uc∂φ(θ)=σ(Vw⋅Uc)σ(Vw⋅Uc)⋅[1−σ(Vw⋅Uc)]⋅Vw=[1−σ(Vw⋅Uc)]⋅Vw
同理求参数
Ud的梯度:
∂Ud∂φ(θ)=σ(Vw⋅Ud)σ(Vw⋅Ud)⋅[1−σ(Vw⋅Ud)]⋅−Vw=[σ(Vw⋅Ud)−1]⋅Vw
求参数
Vw的梯度:
∂Vw∂φ(θ)=σ(Vw⋅Uc)σ(Vw⋅Uc)⋅[1−σ(Vw⋅Uc)]⋅Uc+∑d∈N(w)σ(Vw⋅Ud)σ(Vw⋅Ud)⋅[1−σ(Us⋅Ud)]⋅−Ud
=[1−σ(Vw⋅Uc)]⋅Uc+∑d∈N(w)[σ(Vw⋅Ud)−1]⋅Ud
随机梯度下降法:
for
(w,c)∈D 先从正样本里面获得集合:
对
w进行负采样获得集合
N(w)
更新参数:
Uc=Uc+η∂Uc∂φ(θ)
Ud=Ud+η∂Ud∂φ(θ)
Vw=Vw+η∂Vw∂φ(θ)
评估
我建议是将词向量映射到二维空间里,看看相似的单词是否会聚在一起。
缺点:
1、我们只是计算周围的单词与当前词之间的关系,并没有考虑到上下文的信息
2、在实际应用中,输入词库以外的词还是无法计算,要么删掉,英文可以采用字符拼接的方式。
