Spark Streaming入门
1. 概述
Spark Streaming 是 Spark Core API 的扩展, 它支持弹性的, 高吞吐的, 容错的实时数据流的处理。
spark streaming提供是一种分布式计算能力。
数据来源
数据可以通过多种数据源获取, 例如 Kafka, Flume以及 TCP sockets, 也可以通过例如 map, reduce, join, window 等的高级函数组成的复杂算法处理。
最终, 处理后的数据可以输出到文件系统, 数据库以及实时仪表盘中. 事实上, 你还可以在 data streams(数据流)上使用 机器学习 以及 图计算 算法.
工作原理
Spark Streaming是用来实时处理数据的,但是会把一定的时间间隔的数据当做一个批次去处理,在单位时间间隔内就相当于处理离线的数据了。底层操作其实还是基于RDD的。你可以自定义单位时间间隔的大小。
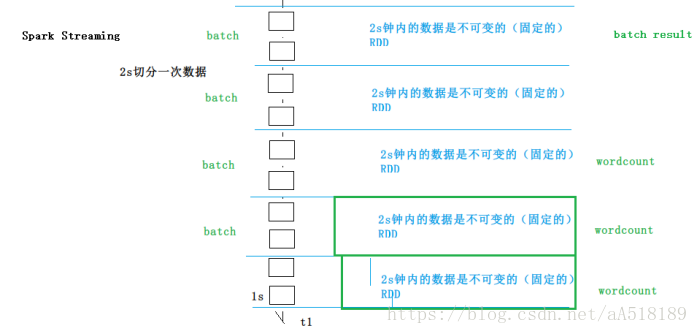
在内部, 它工作原理如下, Spark Streaming 接收实时输入数据流并将数据切分成多个 batch(批)数据, 然后由 Spark 引擎处理它们以生成最终的 stream of results in batches(分批流结果).

Spark Streaming 提供了一个名为 discretized stream 或 DStream 的高级抽象, 它代表一个连续的数据流. DStream 可以从数据源的输入数据流创建, 例如 Kafka, Flume 以及 Kinesis, 或者在其他 DStream 上进行高层次的操作以创建. 在内部, 一个 DStream 是通过一系列的 RDDs 来表示.
DStream
它代表了一个连续的数据流,在内部, 一个 DStream 被表示为一系列连续的 RDDs, 在一个 DStream 中的每个 RDD 包含来自一定的时间间隔的数据。

应用于 DStream 的任何操作转化为对于底层的 RDDs 的操作.

Spark Streaming数据源
l Basic sources(基础的数据源): 在 StreamingContext API 中直接可以使用的数据源.
可以通过StreamingContext点出来的api都是基础数据源;
l Advanced sources(高级的数据源): 像 Kafka, Flume, Kinesis, 等等这样的数据源.
通过第三方的框架封装的获取数据api,称之为高级数据源。
Setting the Right Batch Interval (设置正确的批次间隔)
对于在集群上稳定地运行的 Spark Streaming application, 该系统应该能够处理数据尽可能快地被接收.换句话说, 应该处理批次的数据就像生成它们一样快.这是否适用于 application 可以在 monitoring streaming web UI 中的 processing times 中被找到, processing time (批处理处理时间)应小于 batch interval (批间隔).
取决于 streaming computation (流式计算)的性质, 使用的 batch interval (批次间隔)可能对处理由应用程序持续一组固定的 cluster resources (集群资源)的数据速率有重大的影响.例如, 让我们考虑早期的 WordCountNetwork 示例.对于特定的 data rate (数据速率), 系统可能能够跟踪每 2 秒报告 word counts (即 2 秒的 batch interval (批次间隔)), 但不能每 500 毫秒.因此, 需要设置 batch interval (批次间隔), 使预期的数据速率在生产可以持续.
为您的应用程序找出正确的 batch size (批量大小)的一个好方法是使用进行测试 conservative batch interval (保守的批次间隔)(例如 5-10 秒)和 low data rate (低数据速率).验证是否系统能够跟上 data rate (数据速率), 可以检查遇到的 end-to-end delay (端到端延迟)的值通过每个 processed batch (处理的批次)(在 Spark driver log4j 日志中查找 “Total delay” , 或使用 StreamingListener 接口). 如果 delay (延迟)保持与 batch size (批量大小)相当, 那么系统是稳定的.除此以外, 如果延迟不断增加, 则意味着系统无法跟上, 因此不稳定.一旦你有一个 stable configuration (稳定的配置)的想法, 你可以尝试增加 data rate and/or 减少 batch size .请注意, momentary increase (瞬时增加)由于延迟暂时增加只要延迟降低到 low value (低值), 临时数据速率增加就可以很好(即, 小于 batch size (批量大小)).
2. spark streaming入门案例
2.1.1. Spark streaming 编程模型
注意:最后的 ssc.start()和 ssc.awaitTermination()容易不写
setMaster("local[*]")至少分分配两个核,一个接受数据,一个处理数据。
一个StreamingContext创建多个input Dstream,会创建多个Receiver,Spark会为每个Receiver 分配一个core用于其运行。
故若SparkStreaming 程序一共分配了k个core,运行n个Receiver,应保证k>n,这时会有n个core用于运行Receiver接收外部数据,k-n个core用于真正的计算。
eg:
val lines = ssc.socketTextStream("192.168.80.10", 9999) // Receiver, job-0(input job) 1 core 长驻进程,
val lines = ssc.socketTextStream("192.168.80.10", 9998) // Receiver, job-1 1 core
一个Receiver 占用了一个core,这里两个Receiver占用了2个core,如果这个job的启动资源是 --master "local[4]" 那么真正能用于运算的core只有两个了。
val conf = new SparkConf().setMaster("local[*]").setAppName("ck")
val ssc = new StreamingContext(conf,Seconds(2))
逻辑代码
// 启动spark streaming app
ssc.start()
// 等待被终止, main 阻塞
ssc.awaitTermination()
streaming wordcount
2.1.2. 导入依赖
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.11</artifactId>
<version>2.2.0</version>
</dependency>
2.1.3. 从socket获取数据(nc -lk )并统计wordcount
安装nc命令,yum install -y nc
nc(netcat),一般我们多用在局域网内传送文件(scp多用在跳板机存在的情况),
nc -lk 9999
监听9999这个端口就可向这个端口中传输数据了
Spark streaming就可以实时的从这个端口中获得数据
启动nc命令,并监听一个端口
启动程序:
/** |
总结:
只能统计当前批次的结果数据;但是我们可以基于MySQL或者Redis来实现带历史状态的统计,当然streaming也给我们提供了一个updateStateByKey来实现历史状态的统计,但是使用该方法的时候需要做checkpoint
问题:
1) 修改本地yum源为网络的yum源?
cd /etc/yum.repos.d/
mv CentOS-Media.repo CentOS-Media.repo.bak
mv CentOS-Base.repo.bak CentOS-Base.repo
2) import org.apache.spark.streaming.Seconds
3) pom.xml文件不要倒错包,尤其注意scala sdk的版本
DStream transformations
DStream上的转化算子:注意这些算子RDD上没有
与 RDD 类似,transformation 允许从 input DStream 输入的数据做修改. DStreams 支持很多在 RDD 中可用的 transformation 算子。一些常用的如下所示 :
与RDD类似,类似,transformation 允许修改来自 input DStream 的数据. DStreams 支持标准的 Spark RDD 上可用的许多转换. 一些常见的如下.
Transformation(转换) |
Meaning(含义) |
map(func) |
利用函数 func 处理原 DStream 的每个元素,返回一个新的 DStream. |
flatMap(func) |
与 map 相似,但是每个输入项可用被映射为 0 个或者多个输出项。. |
filter(func) |
返回一个新的 DStream,它仅仅包含原 DStream 中函数 func 返回值为 true 的项. |
repartition(numPartitions) |
通过创建更多或者更少的 partition 以改变这个 DStream 的并行级别(level of parallelism). |
union(otherStream) |
返回一个新的 DStream,它包含源 DStream 和 otherDStream 的所有元素. |
count() |
通过 count 源 DStream 中每个 RDD 的元素数量,返回一个包含单元素(single-element)RDDs 的新 DStream. |
reduce(func) |
利用函数 func 聚集源 DStream 中每个 RDD 的元素,返回一个包含单元素(single-element)RDDs 的新 DStream。函数应该是相关联的,以使计算可以并行化. |
countByValue() |
在元素类型为 K 的 DStream上,返回一个(K,long)pair 的新的 DStream,每个 key 的值是在原 DStream 的每个 RDD 中的次数. |
reduceByKey(func, [numTasks]) |
当在一个由 (K,V) pairs 组成的 DStream 上调用这个算子时,返回一个新的, 由 (K,V) pairs 组成的 DStream,每一个 key 的值均由给定的 reduce 函数聚合起来. 注意:在默认情况下,这个算子利用了 Spark 默认的并发任务数去分组。你可以用 numTasks 参数设置不同的任务数。 |
join(otherStream, [numTasks]) |
当应用于两个 DStream(一个包含(K,V)对,一个包含 (K,W) 对),返回一个包含 (K, (V, W)) 对的新 DStream. |
cogroup(otherStream, [numTasks]) |
当应用于两个 DStream(一个包含(K,V)对,一个包含 (K,W) 对),返回一个包含 (K, Seq[V], Seq[W]) 的 tuples(元组). |
transform(func) |
通过对源 DStream 的每个 RDD 应用 RDD-to-RDD 函数,创建一个新的 DStream. 这个可以在 DStream 中的任何 RDD 操作中使用. |
updateStateByKey(func) |
返回一个新的 "状态" 的 DStream,其中每个 key 的状态通过在 key 的先前状态应用给定的函数和 key 的新 valyes 来更新. 这可以用于维护每个 key 的任意状态数据. |
其中一些转换值得深入讨论.
UpdateStateByKey 操作
该 updateStateByKey 操作允许您维护任意状态,同时不断更新新信息. 你需要通过两步来使用它.
00001. 定义 state - state 可以是任何的数据类型.
00002. 定义 state update function(状态更新函数) - 使用函数指定如何使用先前状态来更新状态,并从输入流中指定新值.
在每个 batch 中,Spark 会使用状态更新函数为所有已有的 key 更新状态,不管在 batch 中是否含有新的数据。如果这个更新函数返回一个 none,这个 key-value pair 也会被消除.
DStream Actions
Output Operation |
Meaning |
print() |
在运行流应用程序的 driver 节点上的DStream中打印每批数据的前十个元素. 这对于开发和调试很有用. I 这在 Python API 中称为 pprint(). |
saveAsTextFiles(prefix, [suffix]) |
将此 DStream 的内容另存为文本文件. 每个批处理间隔的文件名是根据 前缀 和 后缀 : "prefix-TIME_IN_MS[.suffix]" 生成的. |
saveAsObjectFiles(prefix, [suffix]) |
将此 DStream 的内容另存为序列化 Java 对象的 SequenceFiles. 每个批处理间隔的文件名是根据 前缀 和 后缀 : "prefix-TIME_IN_MS[.suffix]" 生成的. PI 这在Python API中是不可用的. |
saveAsHadoopFiles(prefix, [suffix]) |
将此 DStream 的内容另存为 Hadoop 文件. 每个批处理间隔的文件名是根据 前缀 和 后缀 : "prefix-TIME_IN_MS[.suffix]" 生成的. 这在Python API中是不可用的. |
foreachRDD(func) |
对从流中生成的每个 RDD 应用函数 func 的最通用的输出运算符. 此功能应将每个 RDD 中的数据推送到外部系统, 例如将 RDD 保存到文件, 或将其通过网络写入数据库. 请注意, 函数 func 在运行流应用程序的 driver 进程中执行, 通常会在其中具有 RDD 动作, 这将强制流式传输 RDD 的计算. |
2.1.4. foreachRDD 设计模式的使用
dstream.foreachRDD 是一个强大的原语, 允许将数据发送到外部系统.但是, 了解如何正确有效地使用这个原语很重要. 避免一些常见的错误如下.
通常向外部系统写入数据需要创建连接对象(例如与远程服务器的 TCP 连接), 并使用它将数据发送到远程系统.为此, 开发人员可能会无意中尝试在Spark driver 中创建连接对象, 然后尝试在Spark工作人员中使用它来在RDD中保存记录.例如(在 Scala 中):
2.1.5. foreachRDD的使用
可以使用foreachRDD将DStream转换成RDD进行操作:
// 方式一:以下是使用对DStream进行操作 |
foreachRDD在使用连接的时候可以进行如下优化:
通常, 创建连接对象具有时间和资源开销. 因此, 创建和销毁每个记录的连接对象可能会引起不必要的高开销, 并可显着降低系统的总体吞吐量. 一个更好的解决方案是使用 rdd.foreachPartition - 创建一个连接对象, 并使用该连接在 RDD 分区中发送所有记录.
dstream.foreachRDD { rdd => rdd.foreachPartition { partitionOfRecords => // ConnectionPool is a static, lazily initialized pool of connections val connection = ConnectionPool.getConnection() partitionOfRecords.foreach(record => connection.send(record)) ConnectionPool.returnConnection(connection) // return to the pool for future reuse } |
2.1.6. checkpoint
Ø Metadata checkpointing - 将定义 streaming 计算的信息保存到容错存储(如 HDFS)中.这用于从运行 streaming 应用程序的 driver 的节点的故障中恢复(稍后详细讨论). 元数据包括:
Configuration - 用于创建流应用程序的配置.
DStream operations - 定义 streaming 应用程序的 DStream 操作集.
Incomplete batches - 批量的job 排队但尚未完成.
Ø Data checkpointing - 将生成的 RDD 保存到可靠的存储.这在一些将多个批次之间的数据进行组合的 状态 变换中是必需的.在这种转换中, 生成的 RDD 依赖于先前批次的 RDD, 这导致依赖链的长度随时间而增加.为了避免恢复时间的这种无限增加(与依赖关系链成比例), 有状态转换的中间 RDD 会定期 checkpoint 到可靠的存储(例如 HDFS)以切断依赖关系链.
何时启用 checkpoint
对于具有以下任一要求的应用程序, 必须启用 checkpoint:
· 使用状态转换 - 如果在应用程序中使用 updateStateByKey或 reduceByKeyAndWindow(具有反向功能), 则必须提供 checkpoint 目录以允许定期的 RDD checkpoint.
· 从运行应用程序的 driver 的故障中恢复 - 元数据 checkpoint 用于使用进度信息进行恢复.
请注意, 无需进行上述有状态转换的简单 streaming 应用程序即可运行, 无需启用 checkpoint. 在这种情况下, 驱动器故障的恢复也将是部分的(一些接收但未处理的数据可能会丢失). 这通常是可以接受的, 许多运行 Spark Streaming 应用程序. 未来对非 Hadoop 环境的支持预计会有所改善.
如何配置 checkpoint
可以通过在保存 checkpoint 信息的容错, 可靠的文件系统(例如, HDFS, S3等)中设置目录来启用 checkpoint. 这是通过使用 streamingContext.checkpoint(checkpointDirectory) 完成的. 这将允许您使用上述有状态转换. 另外, 如果要使应用程序从 driver 故障中恢复, 您应该重写 streaming 应用程序以具有以下行为.
· 当程序第一次启动时, 它将创建一个新的 StreamingContext, 设置所有流, 然后调用 start().
· 当程序在失败后重新启动时, 它将从 checkpoint 目录中的 checkpoint 数据重新创建一个 StreamingContext.
updatestateByKey
2.1.7. updateStateByKey实现wordcount历史状态统计
object WordCountPlus { |
Window Operations(窗口操作)
Spark Streaming 也支持 windowed computations(窗口计算),它允许你在数据的一个滑动窗口上应用 transformation(转换). 下图说明了这个滑动窗口.
如上图显示,窗口在源 DStream 上 slides(滑动),合并和操作落入窗内的源 RDDs,产生窗口化的 DStream 的 RDDs。在这个具体的例子中,程序在三个时间单元的数据上进行窗口操作,并且每两个时间单元滑动一次。 这说明,任何一个窗口操作都需要指定两个参数.
· window length(窗口长度) - 窗口的持续时间(图 3).
· sliding interval(滑动间隔) - 执行窗口操作的间隔(图 2).
这两个参数必须是 source DStream 的 batch interval(批间隔)的倍数(图 1).
让我们举例以说明窗口操作. 例如,你想扩展前面的例子用来计算过去 30 秒的词频,间隔时间是 10 秒. 为了达到这个目的,我们必须在过去 30 秒的 (wrod, 1) pairs 的 pairs DStream 上应用 reduceByKey 操作. 用方法 reduceByKeyAndWindow 实现.
Transformation(转换) Meaning(含义)
window(windowLength, slideInterval)
返回一个新的 DStream, 它是基于 source DStream 的窗口 batch 进行计算的.
countByWindow(windowLength, slideInterval)
返回 stream(流)中滑动窗口元素的数
reduceByWindow(func, windowLength, slideInterval)
返回一个新的单元素 stream(流),
它通过在一个滑动间隔的 stream 中使用 func 来聚合以创建. 该函数应该是 associative(关联的)且 commutative(可交换的),以便它可以并行计算
reduceByKeyAndWindow(func, windowLength, slideInterval, [numTasks])
在一个 (K, V) pairs 的 DStream 上调用时,
返回一个新的 (K, V) pairs 的 Stream, 其中的每个 key 的 values 是在滑动窗口上的 batch 使用给定的函数 func 来聚合产生的. Note(注意): 默认情况下,
该操作使用 Spark 的默认并行任务数量(local model 是 2, 在 cluster mode 中的数量通过 spark.default.parallelism 来确定)来做 grouping.
您可以通过一个可选的 numTasks 参数来设置一个不同的 tasks(任务)数量.
reduceByKeyAndWindow(func, invFunc, windowLength, slideInterval, [numTasks])
上述 reduceByKeyAndWindow() 的更有效的一个版本,其中使用前一窗口的 reduce 值逐渐计算每个窗口的 reduce值. 这是通过减少进入滑动窗口的新数据,
以及 “inverse reducing(逆减)” 离开窗口的旧数据来完成的. 一个例子是当窗口滑动时”添加” 和 “减” keys 的数量. 然而,
它仅适用于 “invertible reduce functions(可逆减少函数)”,即具有相应 “inverse reduce(反向减少)” 函数的 reduce 函数(作为参数 invFunc </ i>).
像在 reduceByKeyAndWindow 中的那样, reduce 任务的数量可以通过可选参数进行配置. 请注意, 针对该操作的使用必须启用 checkpointing.
countByValueAndWindow(windowLength, slideInterval, [numTasks])
在一个 (K, V) pairs 的 DStream 上调用时,
返回一个新的 (K, Long) pairs 的 DStream, 其中每个 key 的 value 是它在一个滑动窗口之内的频次. 像 code>reduceByKeyAndWindow</code> 中的那样,
reduce 任务的数量可以通过可选参数进行配置.
历史数据聚合解决方案
我们知道spark streaming 按批次处理数据,所以每次处理的都是一个批次的数据,怎么聚合变得十分重要,一下有三种方式实现:
Ø Mysql
Ø updatestateByKey(chickPoint)
Ø redis
基于mysql实现历史数据聚合
object wc2Mysql {
|
基于updatestateByKey(chickPoint)
object wc2ck { |
需要从chickpoint中回复数据
object WordCountPlus { // 屏蔽日志 Logger.getLogger("org").setLevel(Level.WARN) /** * newValues: Seq[Int] : 当前批次某个单词出现的次数 a Seq(1,1,1,1) * runningCount: Option[Int]: 上次a的值 a=None */ val updateFunction = (newValues: Seq[Int], runningCount: Option[Int]) => { val newCount = newValues.sum + runningCount.getOrElse(0) Some(newCount) } // 创建一个新的StreamingContext实例 val function2CreateContext = () => { println("------------------------------") val conf = new SparkConf() conf.setMaster("local[*]") conf.setAppName(this.getClass.getSimpleName) val ssc = new StreamingContext(conf, Seconds(2)) ssc.checkpoint("./ckpt") val stream = ssc.socketTextStream("10.172.50.11", 44444) val wordCountResult = stream.flatMap(_.split(" ")).map((_, 1)).updateStateByKey(updateFunction)
wordCountResult.print() ssc } def main(args: Array[String]): Unit = { /** * 尝试从checkpoint目录中恢复以往的streamingcontext实例 * 如果恢复不了,则创建一个新的 */ val ssc = StreamingContext.getOrCreate("./ckpt", function2CreateContext) ssc.start() ssc.awaitTermination() } } |
基于Redis实现WordCount历史状态的统计
2.1.8. jedis连接池的定义
object Jpools { |
2.1.9. wordcount实现
object WordCountRedis { |