版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/cuicanxingchen123456/article/details/85100525
工作原理:
粗力度
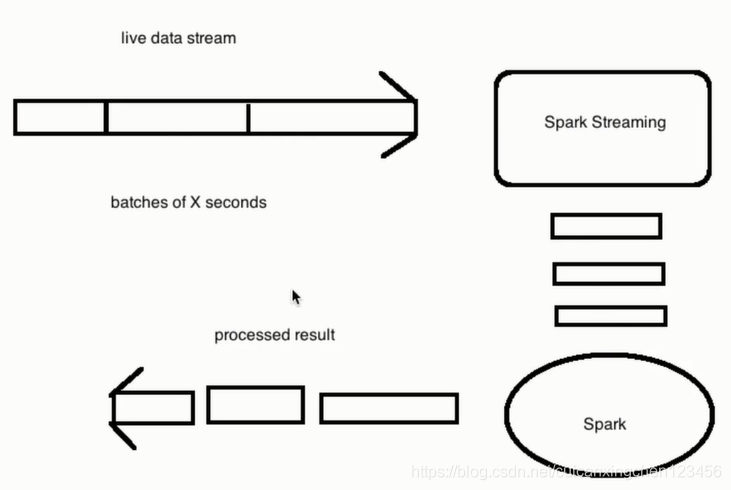
spark streaming接收到实时数据流,把数据按照指定的时间段切成一片片小的数据库,然后把小的数据库传给Spark Engine处理
细粒度:
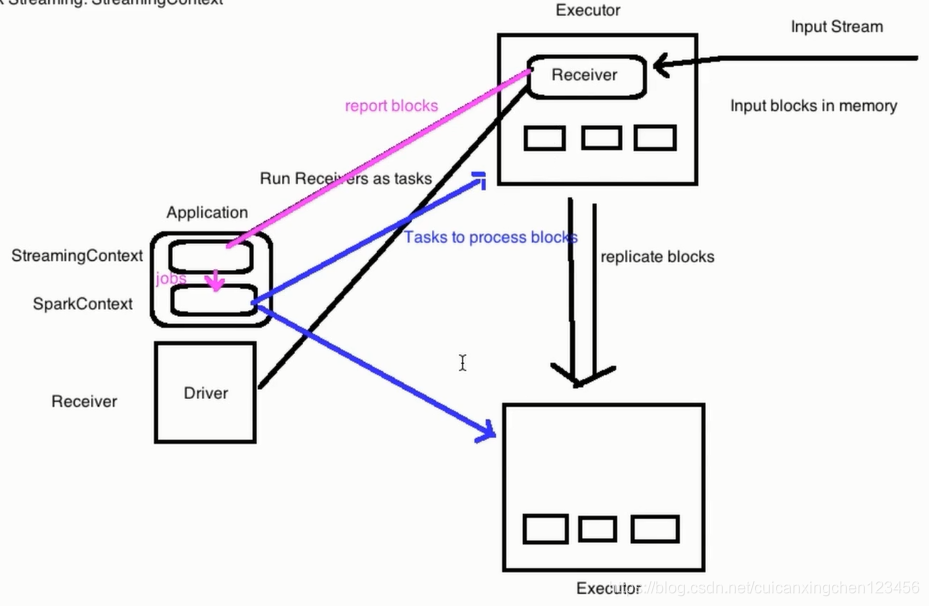
(1)driver:启动spark应用程序,构建StreamingContext
(2)executor:启动receiver接收器,接收数据
(3)executor:接收input Stream,然后拆分不同block(小块),将数据备份到其他executor
(4)executor:receiver将block存储信息发送给StreamingContext
(5)driver:启动job,然后将task提交到对应executor上执行
Spark应用程序运行在Driver端。Receiver是运行在Executor里面的,Driver运行一个Receiver作为一个Task。数据流进入Receiver,Receiver把数据流拆成小块放在内存中。被拆分后的数据会备份到另外一台机器的内存中。然后Receiver向Streaming Context汇报Block信息。Streaming Context会把数据做成RDD,然后在Spark Context上启动jobs。Spark Context会把作业提交到各个Executor中运行。
新建StreamingContext对象时,需要使用sparkconf对象,sparkconf对象会定义使用几个线程 local[n],一个注意点就是一定要让n的个数大于receiver的个数,因为每一个receiver在接收数据的时候都会占用一个线程。如果线程数少于receiver的时候,接收过来之后不会对数据进行处理(主线程会占用一个线程)。
val sparkConf = new SparkConf().setMaster("local[2]").setAppName("NetworkWordCount")
/**
* 创建StreamingContext需要两个参数:SparkConf和batch interval
*/
val ssc = new StreamingContext(sparkConf, Seconds(5))
val lines = ssc.socketTextStream("localhost", 6789)
val result = lines.flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_)
result.print()
ssc.start()
ssc.awaitTermination()