文章目录
如何进行电影分类
众所周知,电影可以按照题材分类,然而题材本身是如何定义的?由谁来判定某部电影属于哪 个题材?也就是说同一题材的电影具有哪些公共特征?这些都是在进行电影分类时必须要考虑的问 题。没有哪个电影人会说自己制作的电影和以前的某部电影类似,但我们确实知道每部电影在风格 上的确有可能会和同题材的电影相近。那么动作片具有哪些共有特征,使得动作片之间非常类似, 而与爱情片存在着明显的差别呢?动作片中也会存在接吻镜头,爱情片中也会存在打斗场景,我们 不能单纯依靠是否存在打斗或者亲吻来判断影片的类型。但是爱情片中的亲吻镜头更多,动作片中 的打斗场景也更频繁,基于此类场景在某部电影中出现的次数可以用来进行电影分类。
介绍第一个机器学习算法:K-近邻算法,它非常有效而且易于掌握。
#KNN算法是有监督的学习,数据必须带有目标值
#要求数据的样本要平衡
#要清楚k值的作用:找周围离自己最近的几个数据
#数据处理
#建立模型->训练数据->模型评估->预测数据
#机器学习应对的三种数据:结构化数据,半结构化数据(html),非结构化数据
一、k-近邻算法原理
简单地说,K-近邻算法采用测量不同特征值之间的距离方法进行分类。
- 优点:精度高、对异常值不敏感、无数据输入假定。
- 缺点:时间复杂度高、空间复杂度高。
- 适用数据范围:数值型和标称型。
1.工作原理
存在一个样本数据集合,也称作训练样本集,并且样本集中每个数据都存在标签,即我们知道样本集中每一数据
与所属分类的对应关系。输人没有标签的新数据后,将新数据的每个特征与样本集中数据对应的
特征进行比较,然后算法提取样本集中特征最相似数据(最近邻)的分类标签。一般来说,我们
只选择样本数据集中前K个最相似的数据,这就是K-近邻算法中K的出处,通常K是不大于20的整数。
最后 ,选择K个最相似数据中出现次数最多的分类,作为新数据的分类。
回到前面电影分类的例子,使用K-近邻算法分类爱情片和动作片。有人曾经统计过很多电影的打斗镜头和接吻镜头,下图显示了6部电影的打斗和接吻次数。假如有一部未看过的电影,如何确定它是爱情片还是动作片呢?我们可以使用K-近邻算法来解决这个问题。

首先我们需要知道这个未知电影存在多少个打斗镜头和接吻镜头,上图中问号位置是该未知电影出现的镜头数图形化展示,具体数字参见下表。

即使不知道未知电影属于哪种类型,我们也可以通过某种方法计算出来。首先计算未知电影与样本集中其他电影的距离,如图所示。
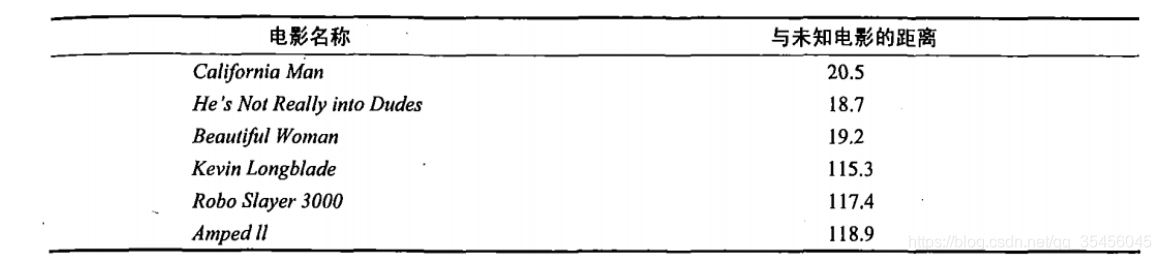
现在我们得到了样本集中所有电影与未知电影的距离,按照距离递增排序,可以找到K个距
离最近的电影。假定k=3,则三个最靠近的电影依次是California Man、He’s Not Really into Dudes、Beautiful Woman。K-近邻算法按照距离最近的三部电影的类型,决定未知电影的类型,而这三部电影全是爱情片,因此我们判定未知电影是爱情片。
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import pandas as pd
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import train_test_split
二、数据准备阶段
m = pd.read_excel('tests.xlsx',sheet_name=0)
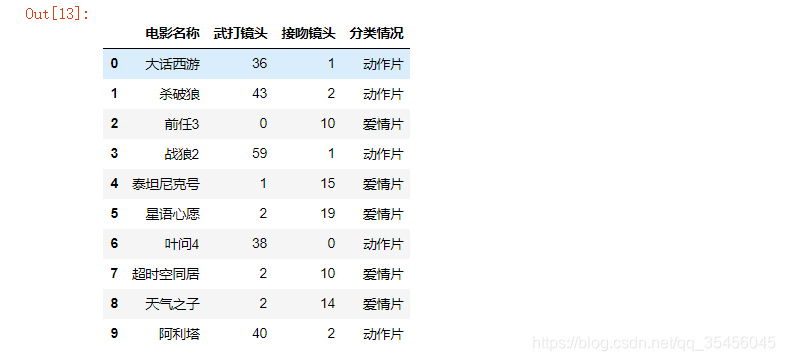
1.特征提取
Faeture 特征部分
Labels(target)目标
目标:

m.iloc[:,1:-1]

m.iloc[:,-1]

#2.特征的抽取 Feature 特征部分 和 Labels(target) 目标
#Feature 必须是一个二维的数据类型 Labels至少是一维的
fea = m.iloc[:,1:-1]#逗号前面的是行,后面的是列
lab = m.iloc[:,-1]
lab:

2.数据需要切分成训练数据和测试数据
#3..数据需要切分成 训练数据 和 测试数据
#int 测试数据又几条
#float 测试数据的比例
X_train,X_test,y_train,y_test=train_test_split(fea,lab,test_size=0.3)
X_train,X_test,y_train,y_test

label

三、数据的训练
#2.数据的训练
#n_neighbors = k : 找几个距离自己最短的邻居
#p=2 使用欧式距离作为度量
#n_jobs 开启几个进程
knn = KNeighborsClassifier(n_neighbors=5,p=2,n_jobs=2)
#进行训练
knn.fit(X_train,y_train)
#进行评估 观测模型的准确率
knn.score(X_train,y_train)
n_neighbors是knn中的k值,找几个距离自己最短的邻居
p=2指用欧式距离作为度量(好看)
p=1指的是用曼哈顿距离作为度量
不填默认闵可夫斯基距离
n_jobs开启几个进程
进行训练,多的训练,比较少的测试:

训练完成后对模型进行评估
观测模型的准确率
1.0说明没有欠拟合,但是过拟合不知道
四、数据的测试
测试得分
#3.数据的测试
knn.score(X_test,y_test)

结果也是1.0,没有低于0.8,说明没有过拟合
五、模型的模拟
#假如爱有天意,
给个新电影,new=[3,17]
我们获取到的当前是一维的数据,模型需要二维数组不认识会报错
写成二维列表也可以,好像还是转一下数组比较好
二维列表的话,画图的时候不好取第一列第二列,所以改成了二维数组
#4.模型的模拟
#'假如爱有天意'
new = np.array([(3,17)])
#预测
knn.predict(new)
预测结果:

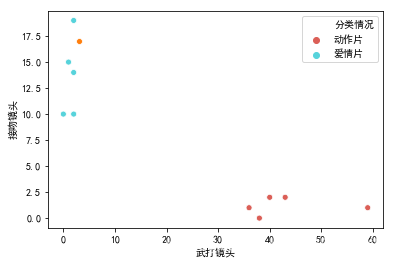
六、图形展示
plt.rcParams['font.family'] = ['SimHei']
sns.scatterplot(x='武打镜头',y='接吻镜头',data=m,hue='分类情况',palette='hls')
sns.scatterplot(x=new[:,0],y=new[:,1])
附:欧几里得距离(Euclidean Distance)
欧氏距离是最常见的距离度量,衡量的是多维空间中各个点之间的绝对距离。公式如下:
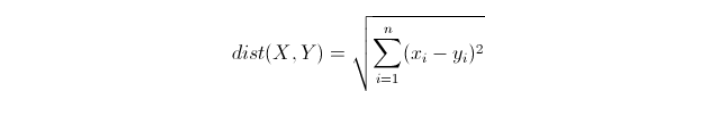
总结使用sklearn的knn模块进行分类
#1.模型实例
#n_neighbors=5 默认找周围的5个离自己最近的数据
knn=KNeighborsClassifier(n_neighbors=5)
#2.将数据进行训练(把数据保存到内存中)
#X是特征数据
#y是目标数据(标签)
knn.fit(X_train,y_train)
#3.评估 1.0代表100%的准确
knn.score(X_train,y_train)
#准确率 被预测正确的数据数量 / 总数据数量
#4.对测试数据进行评估
knn.score(X_test,y_test)
#5.如果模型的分值高,那么模型可以上线,可以进行预测了
knn.predict(X_test)
