调度器
在k8s集群中,能运行pod资源的只有工作节点,master 主要是做为控制平面组件 (api-server, contarner-manage, 调度器), 也依赖于etcd(最好能有冗余能力)
节点创建流程
- 当用户发起请求向Api Server 要求创建一个新的Pod资源对象时, Api Server先检查权限、授权、准入控制皆无问题,
- 然后将请求交给scheduler(调度器), 然后从集群中的work节点中匹配一个此Pod资源的运行节点, 调度器的选择结果并不会直接产生对应的Pod资源,而是会告诉 Api Server, 并且会将结果记录到Etcd中,实现持久化功能,
- 而每一个节点上的 Kubelet会一直监听着Api Server与自己节点相关连的事件变动, 当 Api Server发生变动时, 这个变动节点上的Kubelet会尝试获取Api server中定义的Pod清单,并且根据这个清单去创建一个Pod,
- 在创建这个Pod时会根据image或ImagePolicy下载或从私有仓库下载,如果是私有仓库那么它会检查对应的SA,当SA通过下载镜像并根据清单创建Pod(容器),
- 如果还有PVC那么还得根据相对应的存储创建PV
- 在创建和运行时,Pod有生命周期,我们此时在前端加一个serivces以提供一个固定的访问端点
- 而services并不是一个实实在在的组件,它其实只是每一个节点上的iptables或ipvs规则
- 当用户通过任意api调用的接口创建service时,这个请求也会向api service发送
- kubeproxy会监控着跟api service资源的变动,而后把创造成当前节点上的iptables或ipvs规则,kubeproxy是管理service资源的重要组件
节点过滤
- Volumes Filters:如果某一个Pod要求要使用本地的临时存储,而且需要至少有20G的存储空间,正好所有节点当中有的节点有20G有的节点没有20G,那么没有20G的就会被排除掉;
- Resources Filters:如果某一节点要求resource,CPU至少有四核,那么CPU也需要经过一次筛选;
- Topology Filters:
节点挑选
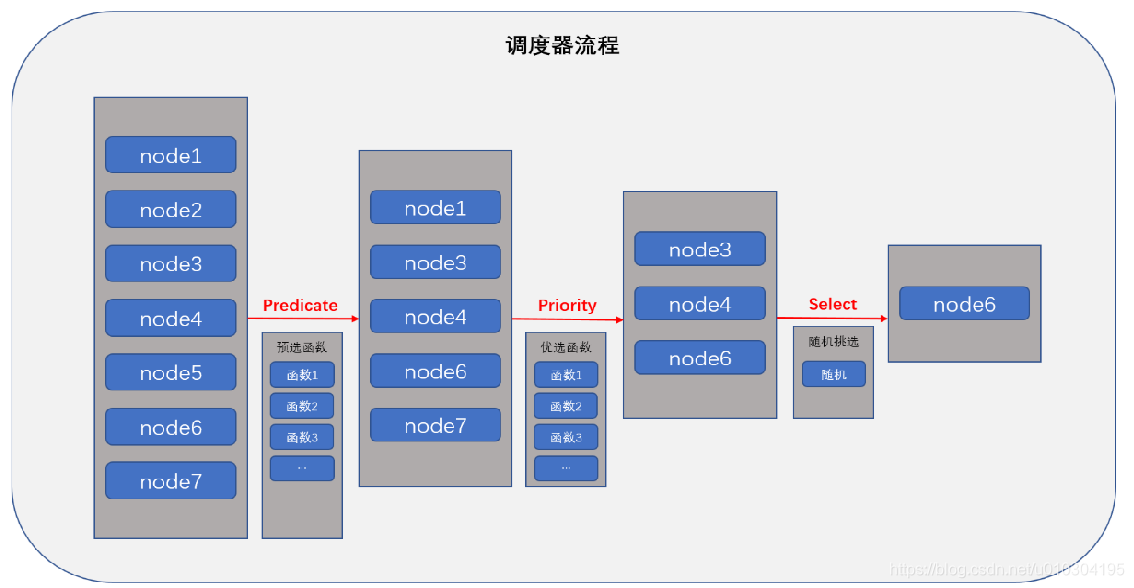
调度器是如何决策哪一个Pod在哪一个节点上运行的,简单来说 当用户创建Pod资源对象时,有一组节点可以选择, 调度器会从集群中的节点挑出一个匹配的,default scheduler通过三级来挑选节点
- 排除此Pod完全不符合的节点, 比如 Predicate(预选)
- 当前资源占用
- 资源限额
- 最低资源需求 (1c、2G内存),
- 比如污点,当我们节点有污点而Pod不能容忍该污点,那么这些所有不能容忍的污点就会被排队在外,只能留下没有污点的或者此Pod能容忍的污点的节点
- 优选策略, priority(优选)
- 基于一系列的算法,函数把每一个节点的属性输出进去 ,然后计算每一个节点的优先级,在进行排序
- 选定节点: Selector
- 如果还是有多个节点,那就随机挑选一个
基本工作流程
对于预选,k8s会有很多预选器也会参与挑选节点是否符合Pod的基本要求,对于Predicate来讲,它是一个或者一组程序,会将Kubernetes之上的所有节点拿来,进行一次计算,如果其中有一组程序声明这个节点不符合运行此Pod的条件,那么这就被预选排除了,以此类推,这些左右节点都经过这一组Predicate进行评估之后,留下的都是至少能符合运行此Pod的基本条件;
于是这些节点谁是最好的,因此就需要进入第二步,Priority也是有一组优先函数组成的,这个函数不像Predicate它合不合理,而评估的是这个节点和运行此Pod的评估分数,比如node1进来,进入第一个Priority函数计算得两分,进入第二个Priority函数计算得三分,最终所有的Priority函数的分值的和就是这个node节点的整体得分分值,而后基于得分进行排序,逆序排序;
排完序之后,就看得分最高的有几个,然后会将得分最高的挑选出来,进入Select流程,进行随机挑选;
调度器流程
当我们未定义调度器的时候,直接使用默认值,准入控制器会为我们补齐该字段,
# 查看已创建的Pod调度器默认值
]# kubectl get pods -n dev my-dev-6568b4bdb-b4zmf -o yaml | grep schedulerName
schedulerName: default-scheduler
预先策略
pod以及节点对象
- CheckNodeCondition: 检查是否可以在节点磁盘、网络或未准备好的前提下能够将Pod调度上来;
- GeneralPredicates: 通用预先策略,它并不是一个单独的预选策略,如
- HostName: 对应的节点上Pod名称未被使用, 检查Pod对象是否定义了 pod.spec.hostname;
- PodFitsHostPorts: pod.spec.containers.ports.hostport,如果pod指定了hostport那么该pod就会绑定在节点的这个端口,如果占用那么就不会匹配这个节点;
- MatchNodeselector: pods.spec.nodeSelector,匹配与节点选择器一致的节点, 节点亲和性;
- PodFitsResoures: 检查节点是否有足够资源支撑这个pod运行;
- NoDiskConflict: 检查Pod依赖的存储卷是否满足需求, [ 以下默认没有启用] ;
- PodToleratesNodeTaints:检查Pod上的pod.spec.tolerations可容忍污点是否完全包含节点上的污点;
- PodToleratesNodeNoExecuteTaints: [未启];
- CheckNodeLabelPresence: 检查标签存在性, [未启];
- CheckServiceAffinity: 根据当前Pod对象所属的service,Pod可以属于一个或多个serivce [未启] ;
存储资源
- CheckVolumeBinding: 检查存储绑定关系
- NoVolumeZoneConflict: 是否为NoVolume指定区域
底层资源
- CheckNodeMemoryPressure: 检查内存节点是否处于压力过大的情况
- CheckNodePidPressure: 检查节点pid进程过多的情况
- CheckNodeDiskPressure: 检查磁盘是否将满
亲和性
- MatchInterPodAffinity: pod之间的亲和性
优先函数
如果定义多个, 得分分值越高挑选越大
- leastRequested: 有节点的空闲资源,与节点的总容量进行对比
- 算法:cpu((capacity-sum(request))*10/capacity)+memeory((capacity-sum(request))*10/capacity/2 说明:cpu*((总容量-已用容量)*10/总容量)+内存((总容量-已用容量)*10/总容量/2)
- BalancedResourceAllocation: Cpu和内存资源占用均衡越平均,优先级越高
- CPU和 内存资源被占用率相近胜出
- NodePreferAvoidPods: 节点倾向不要运行这个pod
- 根据节点注解信息来判定 “scheduler.alpha.kubernetes.io/preferAvoidPods”, 存在此注解得分为 0
- TaintToleration: 基于pod资源对节点污点的容忍度调度偏好,
- 将pod对象的spec.tolerations列表项与节点的taints列表项进行匹配度检查,匹配的条目越多得分越低;
- SelectorSpreading: 查找与Pod对象匹配的services,(rs, deploy, sts)
- 已经运行此类Pod对象的节点越少,得分度越高
- InterPodAffinity:
- 遍历Pod对象的亲和性条目,并将能够匹配到节点的权重相加,结果值越大,得分越高
- NodeAffinity: 节点亲和性,
- MostReuqestd: [未启]
- 与 leastRequested 相反,不同时使用, 使用越多,优先级越高,直到占用100%
- NodeLabel: 根据节点特定标签得分,只要有标签就行 [未启]
- ImageLocality: 根据满足当前Pod对象需求的镜像的体积大小之和 [未启]
selector
当一个Pod被调度的时候,所有通过预选策略的node都会进行一些硬性条件检查,而后经过优选策略进行软性分值计算,而后通过分值进行排序,接下来进行选择阶段了,最高分胜出;
-
节点倾向性
nodeName: 节点名称 nodeSelector: 节点挑选, 节点倾向性 -
Pod亲和性
- 某些个Pod运行在同一节点,或相邻节点
-
污点
- 给某些节点打上污点,这样Pod在挑选时如果能容忍这个节点那么就能运行在这个节点之上, 如这个pod有十个污点,而这个节点有五个污点并且是有Pod亲和性的子集
- Taints: 节点之上的污点
- Tolerations: Pod之上的污点
k8s调度器
一般来讲当我们创建Pod时都会被kube-scheduler当中的default-scheduler调取,目前来讲,k8s内部只有一个调度器,但是它支持插件式调度器,允许用户自定义调度器对接到已有的调度程序上;我们可以在外部施加各种条件,来影响调度结果,比如在定义Pod时,在spec字段中加上nodeName或nodeSelector来影响它的调度结果,或指定匹配node节点,如果没有节点被匹配,那它就会被Pending,这种就属于硬性调度机制;
也可以有一些柔性调度机制,比如Affinity,亲和性也分硬亲和和软亲和,硬亲和指的是,如果满足它的亲和性,它就可以把node作为调度节点,如果不满足,就直接排除,而软亲和指的是如果我们经过亲和性检测,发现没有一个节点符合这个亲和性,那么就随机亲和;
当然我们也可以使用污点, 从上面描述的来看可以看出node都是等待着被选择,那么我们也可以赋予node的主动权,给node加上一个污点,如果节点不能容忍这个污点,那么就不会调度上面来,这就给了node主动控制权;
高级调度设计
如果在某些特定场景当中,我们期望通过自己的预设来影响它的预先和优选过程,从而使得调度操作符合我们期望,此类的影响方式通常有如下几种:
- 节点选择器: nodeSelector, nodeName
- 节点亲和调度: nodeAffinity
节点选择器
- nodeName:如果我们期望将pod调度到某一特定的节点上,直接指定nodeName节点名称就行
]# cat nodeName-1.yaml
apiVersion: v1
kind: Pod
metadata:
name: pod-node-select
spec:
containers:
- name: pod-node-select
image: ikubernetes/myapp:v1
imagePullPolicy: IfNotPresent
nodeName: slave1 # 将节点指定至slave1的节点上 通过kubectl get nodes查看节点
nodeName: slave11 # 如果节点不存在,那么该pod会一直Pending等待该节点
# pod-node-select-2 0/1 Pending slave3
-
nodeSelector: 给一部分节点打上特有标签,节点通过nodeSelector匹配
]# kubectl explain pod.spec.nodeSelector # 可查看对应参数 # 通过 kubectl label 添加标签 kubectl label node slave1 disk=ssd # 通过给一些节点添加标签,然后通过 nodeSelector 选择更具有亲和性一些的节点,比如 全固态跑数据库 ]# cat nodeSelecto-1.yaml apiVersion: v1 kind: Pod metadata: name: pod-select-1 spec: containers: - name: pod-select-1 image: ikubernetes/myapp:v1 imagePullPolicy: IfNotPresent nodeSelector: # kubectl get node --show-labels, 或通过 kubectl label node 打标 disk: ssd
节点亲和调度
查看节点亲和性调度参数:
~]# kubectl explain pods.spec.affinity
- 同时指定nodeAffinity和nodeSeletor,那么他们是“与”关系,即符合条件的Node需要同时满足两个条件;
- 为nodeAffinity同时指定多个nodeSelectorTerms时,各条目间取逻辑“或”关系,即满足一个条件即可;
- 同一个nodeSeletorTerms中的多个matchExpression存在逻辑“与”关系,即Node需要同时满足多个条件;
- 如果调度以及完成了,后来将节点的label删除了,导致这个节点不能再满足这个亲和性了,那么已调度的Pod不会被remove,这个亲和性仅仅发生在调度的过程当中,调度完成后label的变动将不再有任何影响;
.nodeAffinity
节点亲和性
# kubectl explain pods.spec.affinity.nodeAffinity
# preferredDuringSchedulingIgnoredDuringExecution 软亲和性, 尽量满足的条件,不满足也可以
preference: 节点选择
weight: 权重 1-100
# requiredDuringSchedulingIgnoredDuringExecution 硬亲和性,必须要满足的条件,不满足一定不运行pending状态
nodeSelectorTerms: 节点选择器
matchExpressions: 匹配正则表达式
operator参数: In,NotIn, Exists, DoesNotExist. Gt, and Lt
matchFields: 匹配字段
硬亲和性
# 硬亲和性,必须要满足,不满足就pending
]# cat nodeAffinity-required-1.yaml
apiVersion: v1
kind: Pod
metadata:
name: nodeaffinity-hard-1
spec:
containers:
- name: nodeaffinity-hard-1
image: ikubernetes/myapp:v1
imagePullPolicy: IfNotPresent
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: disk # key为disk
operator: In # disk的value值应当包含 ssd或 pcie
values: # 只要满足这些条件,Pod就会运行在这个节点之上
- ssd # 不满足就会一直处于pending的状态
- pcie
软亲和性
]# cat nodeAffinity-required-2.yaml
apiVersion: v1
kind: Pod
metadata:
name: nodeaffinity-soft-2
spec:
containers:
- name: nodeaffinity-soft-2
image: ikubernetes/myapp:v1
imagePullPolicy: IfNotPresent
affinity:
nodeAffinity:
# 软亲和性,当条件不满足时,使用默认的default-schedule挑选节点
preferredDuringSchedulingIgnoredDuringExecution:
- preference:
matchExpressions:
- key: disk
operator: In
values:
- pcie
weight: 30
.podAffinity
Pod亲和性调度,调度器随机将第一个Pod选择一个位置,然后第二个Pod会根据第一个Pod进行调度。Pod亲和性并不强制限制在同一个节点,也可以是相近的节点(或拥有一样标签)
~]# 通过kubectl explain pods.spec.affinity.podAffinity查看选项
对于Pod资源来讲,在运行过程中因为Pod之间的关系,可能会根据业务需求将其运行在同一个或不能在同一个节点上,像这种高级调度控制器,称之为Pod间的Affinity或Anti-Affinity,这两种调度关系分别为亲和性、反亲和性;
Pod亲和性主要用于描述两个Pod之间能否运行于同一位置,同一位置可能是同一机房,同一节点,同一集群等,因此在定义Pod亲和性时,我们必须有一个机制来人为定义何为同一位置,有一个专门的字段,叫做topologyKey;
如果要使用Pod亲和性来调度,只需要在Pod的spec下面的affinity字段当中使用podAffinity或者使用podAntiAffinity来定义即可,但是Pod的亲和性和反亲和性有一个要求,如果要使用Pod亲和性,假如有三百个节点,每调度一个Pod都需要评估这个Pod和其他Pod是不是在同一个位置,可能会遍历每一个节点查询位置是不是一样的,所以评估过程就被拖慢,因此在较大的规模的集群当中,反而不是特别适合于使用podAffinity,或者不易于使用较细的粒度进行区分同一位置;
podAntiAffinity指的是几个Pod一定不能在同一个位置,Pod的podAntiAffinity严格要求集群当中的每一个节点,都必须设置正确的标签,否则没法评估到底是不是反亲和性的,否则反亲和性就无法工作,因此Pod的亲和性调度,还是有着较大局限性的;
preferredDuringSchedulingIgnoredDuringExecution 软亲和性
requiredDuringSchedulingIgnoredDuringExecution 硬亲和性
labelSelector:指定一组目标Pod资源
namespaces: 指定labelSelector是哪一组名称空间
topologyKey: 位置拓扑键, 相同即是同一位置,只能有一个key
亲和性
]# cat podAffinity-hard.yaml
apiVersion: v1
kind: Pod
metadata:
name: pod-affinity-p-1
labels:
app: pod-affinity-1
spec:
containers:
- name: podaffinity-1
image: ikubernetes/myapp:v1
imagePullPolicy: IfNotPresent
---
apiVersion: v1
kind: Pod
metadata:
name: pod-affinity-m-2
labels:
app: pod-affinity-2
spec:
containers:
- name: podaffinity-1
image: ikubernetes/myapp:v1
imagePullPolicy: IfNotPresent
affinity:
podAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: app
operator: In
values: ["pod-affinity-1"]
topologyKey: kubernetes.io/hostname # 选择相同的逻辑节点或同一区域的物理节点,硬亲和性,指定必须运行在同一个区域节点相匹配亲和性 Pod的机房,通过 kubectl get nodes --show-labels 查看labels
]# kubectl get pods -o wide
NAME READY STATUS IP NODE
pod-affinity-m-2 1/1 Running 10.244.2.6 slave2
pod-affinity-p-1 1/1 Running 10.244.2.5 slave2
demo-2
# slave 1 slave2 运行 tj-pod
# pod2 亲和 tj-pod这个pod , 但是pod2 依赖于 slave1 天津机房
# kubectl labels node slave jf=tj
apiVersion: apps/v1
kind: Deployment
metadata:
name: my-execution
spec:
replicas: 3
selector:
matchLabels:
app: my-execution
template:
metadata:
labels:
app: my-execution
spec:
containers:
- name: my-execution
image: ubuntu:latest
imagePullPolicy: IfNotPresent
command: ["/bin/sh"]
args: ["-c", "while true;do sleep 10;done"]
resources:
limits:
memory: "10Mi"
cpu: "5m"
requests:
memory: "10Mi"
cpu: "5m"
---
apiVersion: v1
kind: Pod
metadata:
name: tj-pod
labels:
name: tj-pod
spec:
affinity:
podAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- topologyKey: jf
labelSelector:
matchExpressions:
- key: app # 这里是pod亲和, 需要选择的是pod的标签而不是node的
operator: In
values:
- my-execution
# matchLabels: jf: bj
containers:
- name: tj-pod
image: ubuntu:latest
command:
- sleep
- "3600"
resources:
limits:
memory: "10Mi"
cpu: "5m"
requests:
memory: "10Mi"
cpu: "5m"
反亲和性
# 将两个节点加至同一个区域,测试反亲和性如果在同一个区域, 反亲和节点是否运行
]# kubectl label nodes slave1 zone=bj
]# kubectl label nodes slave2 zone=bj
]# cat podAffinity-anti.yaml
apiVersion: v1
kind: Pod
metadata:
name: pod-affinity-anti-p-1
labels:
app: pod-affinity-anti-1
spec:
containers:
- name: podaffinity-anti-1
image: ikubernetes/myapp:v1
imagePullPolicy: IfNotPresent
---
apiVersion: v1
kind: Pod
metadata:
name: pod-affinity-anti-m-2
labels:
app: pod-affinity-anti-2
spec:
containers:
- name: podaffinity-anti-1
image: ikubernetes/myapp:v1
imagePullPolicy: IfNotPresent
affinity:
podAntiAffinity: # 反亲和性,与定义的Pod运行节点刚好相反的
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: app
operator: In
values: ["pod-affinity-anti-1"]
topologyKey: zone # 选择为zone的逻辑或物理位置节点
]# kubectl get pods -o wide
NAME READY STATUS IP NODE
pod-affinity-anti-m-2 0/1 Pending <none> <none>
pod-affinity-anti-p-1 1/1 Running 10.244.1.13 slave1
# 将 slave2 的zone label删除, 反亲和性的Pod会立即运行到与之相反的节点。
]# kubectl label nodes slave2 zone-
]# kubectl get pods -o wide
NAME READY STATUS IP NODE
pod-affinity-anti-m-2 1/1 Running 10.244.2.8 slave2
pod-affinity-anti-p-1 1/1 Running 10.244.1.13 slave1
污点和容忍度
- 无论是NodeAffinity还是PodAffinity还是PodAntiAffinity都是Pod选择运行在哪个节点上,他们都是基于Pod选节点的,所以无论是哪一个都是我们的节点等待被选择,Taints这种机制使得我们的节点可以反对Pod被调度,或接纳Pod调度的主控权, 从而能够使得节点在必要时可以排斥它不期望运行的Pod
- 与NodeAffinity或者PodAffinity不同的是,它必须要结合Tolerations才能协同工作的,也就是说一旦一个节点打上了污点之后Pod能不能调度到这个节点上要取决于这个Pod上有没有对应污点的容忍度,以将来要基于污点来调度的话,那就必须要确保在节点上能够有污点,在Pod上有容忍度,否则的话,任何不能容忍这个污点的Pod都无法调度上来,从而使得该节点可以用于运行特定类型的Pod;
污点参数
taint的effect定义对Pod排斥效果, 当Pod不能容忍这个污点时,采取的行为
| 参数 | 说明 |
|---|---|
| Noschedule | 仅影响调度过程,对现存的Pod对象不产生影响, 如果不容忍就不允许调度过来 |
| NoExecute | 不仅影响调度还影响现存Pod对象, 不容忍Pod对象将被驱逐 |
| PreferNoschedule | 不容忍会影响调度,但最终还是能被允许 |
Tolerations匹配Taints
- key必须相同;
- value必须相同;
- effect必须相同;
容忍度评估
- 等值比较-Equal: 我们定义容忍度,表示容忍度与污点在key,value和effect完全匹配
- 存在性判断-Exists:两者的key与effect必须完全匹配,但是value可以使用空值,只需要判断存不存在,一个节点可以有多个污点,一个Pod对象也可以有多个容忍度,两者在做匹配时要遵循
污点使用
Command:
kubectl taint node nodename key=value:effect参数
-
添加污点
# 给节点打上污点 ~]# kubectl taint node slave2 node-type=qa:NoSchedule # 删除污点 ~]# kubectl taint node slave2 node-type- # 查看节点的污点情况 ~]# kubectl get nodes slave2 -o yaml spec: podCIDR: 10.244.2.0/24 podCIDRs: - 10.244.2.0/24 taints: - effect: NoSchedule key: node-type value: qa # 给节点打上污点 ~]# kubectl taint node slave1 node-type=dev:NoExecute # 查看节点的污点情况 ~]# kubectl get nodes slave2 -o yaml spec: podCIDR: 10.244.1.0/24 podCIDRs: - 10.244.1.0/24 taints: - effect: NoExecute key: node-type value: dev -
定义Pod污点容忍度
~]# kubectl explain deploy.spec.template.spec.tolerations 容忍污点
effect # 污点级别参数
key: # 节点定义的taints key
operator: # 污点评估值 Exists and Equal
tolerationSeconds:# 容忍时间,定义可以忍受在一段时间内的驱逐 单位: 秒
value: # 节点定义的 taints value
# 先定义一个普通的Pod查看 是否能够运行
]# cat deploy-effect.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: my-myapp-effect
labels:
app: my-effect-first
spec:
replicas: 3
selector:
matchLabels:
app: my-effect-first
template:
metadata:
name: my-myapp-effect
labels:
app: my-effect-first
spec:
containers:
- name: my-myapp-effect
image: ikubernetes/myapp:v1
imagePullPolicy: IfNotPresent
# 当没有定义污点时,节点的NoSchedule 不允许没有定义Pod 容忍度的容器运行
- 添加污点-Equal
spec:
# Pod内容不变
template:
# Pod内容不变
spec:
# Pod内容不变
tolerations:
- effect: NoSchedule
key: node-type
operator: Equal # 当定义 Equal时 key value必须相等
value: "qa"
]# kubectl get pods -o wide
NAME READY STATUS IP NODE
my-myapp-effect-6964b5756-cdmzs 1/1 Running 10.244.2.9 slave2
my-myapp-effect-6964b5756-j2mpm 1/1 Running 10.244.2.10 slave2
my-myapp-effect-6964b5756-js42g 1/1 Running 10.244.2.11 slave2
- Exists
tolerations:
- effect: NoExecute
key: node-type
operator: Exists # 只需要 key跟effect能相等,那么就能匹配到对应节点的污点
value: "" # 此处需为空, 通配符匹配
]# kubectl get pods -o wide
NAME READY STATUS IP NODE
my-myapp-effect-65f65f8784-j8k2w 1/1 Running 10.244.1.14 slave1
my-myapp-effect-65f65f8784-s6n4t 1/1 Running 10.244.1.15 slave1
my-myapp-effect-65f65f8784-vftnh 1/1 Running 10.244.1.16 slave1
- effect不添加等值时
tolerations:
- effect: "" # 啥都不加 匹配所有
key: node-type # key必须要有
operator: Exists # 只需要 key跟effect能相等,那么就能匹配到对应节点的污点
value: "" # 此处需为空, 通配符匹配
# Pod会随机挑选一个节点运行。
k8s内建污点
Kubernetes在1.6之后引入了几个表达节点问题的几个污点,他们由Node Controller根据节点的实际状态在需要时自动添加;
| key | 说明 |
|---|---|
| node.kubernetes.io/not-ready | 节点未就绪 |
| node.kubernetes.io/unreachable | 节点不可达 |
| node.kubernetes.io/unreachable | 磁盘耗尽 |
| node.kubernetes.io/out-of-disk | 内存耗尽 |
| node.kubernetes.io/disk-pressure | 磁盘耗尽 |
| node.kubernetes.io/network-unavailable | 网络不可用 |
| node.kubernetes.io/unschedulable | 不可被调度 |
| node.kubernetes.io/uninitialized | 未被初始化 |