版权声明:本文为博主原创文章,欢迎转载,转载标明原文地址: https://blog.csdn.net/u012943767/article/details/80462995
Apache Strom 实时计算系统
Storm简介
Apache Storm是一个分布式大数据实时计算系统,Storm设计用于在容错和水平可拓展方法中实时处理大数据,是一个数据流框架,可以使用Storm并行的对实时数据执行各种操作。相比于Hadoop的批量处理机制,Storm的实时处理机制更适合实时性要求比较高的场景。
Storm具有以下特点:
- 支撑各种实时类项目场景,实时处理消息以及更新数据库,基于最基础的实时计算语义,对实时数据进行计算。
- 高度的可伸缩性,如果需要扩容,直接添加机器即可,调整计算拓扑的并行度就可以了。无缝快速扩容。
- 高容错性,如果某台机器宕机了,重启后也不会影响作业,保证消息都不丢失。
- 高健壮性,从历史经验来看,
storm比hadoop,spark等大数据类系统都健壮,因为元数据都保存在zookeeper中 - 对用户友好,核心语义非常简单,开发起来效率很高,并且支持多种变成语言。
Storm的集群架构
接下来看看Strom的集群架构,Strom的集群拓扑如下图:
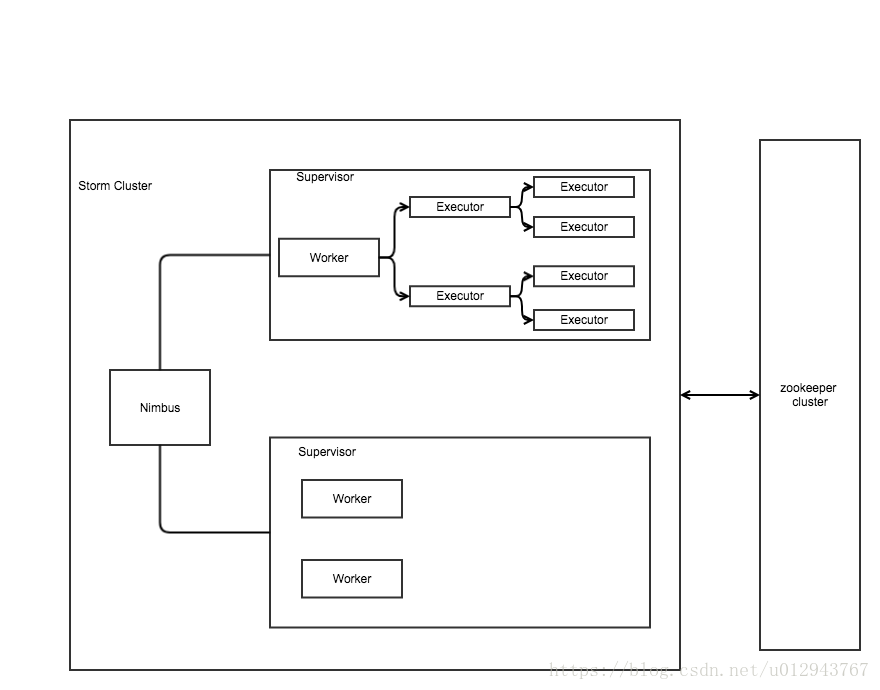
各种组件的解释如下:
Nimbus:Storm集群主节点,集群中的其他节点成为工作节点,主节点主要负责在工作节点之间分发数据,向工作节点分配任何和监视故障。Supervisor:工作节点叫做Supervisor,工作节点有多个工作进程,管理工作进程以完成由Numbus分配的任务。Worker:工作进程,工作进程会创建执行器,让执行器执行特定的任务,工作进程将有多个执行器。Executor:执行器是工作进程产生的单个线程,执行器运行多个任务。Task:任务执行实际的数据处理,主要输是运行一个计算。所以他是一个Spouts或者BotsZookeeper framework:Strom利用Zookeeper维护共享数据之间的协调服务,依赖于Zookeeper来监控工作节点的状态。
Storm核心概念
Storm处理数据的过程是从一端读取实时数据的输入流,并将其通过一系列小处理待援,并在另一端输出信息。在Storm中有以下概念:
Spouts:数据输入源,通过我们需要实现一个Spouts的接口,尝试在数据源读取数据,比如说在kafka中消费数据。Bolts:Bolts是逻辑处理单元,数据是Spouts中读取,然后会将数据传递到Bolts中处理,处理之后会把数据传递到另外的一个或多个的Bolts处理。Tuple: 在代码中的一条数据的数据结构,在Spouts和Bolts中传递。Steam:数据流的概念,是一个抽象的概念,可以想象为多个Tuple组成一个数据流Topplogy:拓扑,Spouts和多个Bolts连接在一起,组成一个拓扑。拓扑是有向图,定点是计算,边缘是数据流,简单的拓扑从Spouts开始,将数据发射到一个或多个Bolts处理,Bolts表示据欧最小处理逻辑的节点,Bolts的输出可以发射到另一个Bolts作为输入。Strom的工作主要是运行拓扑,开发Storm的工作其实也是开发拓扑。
一个简单拓扑的结构如下:
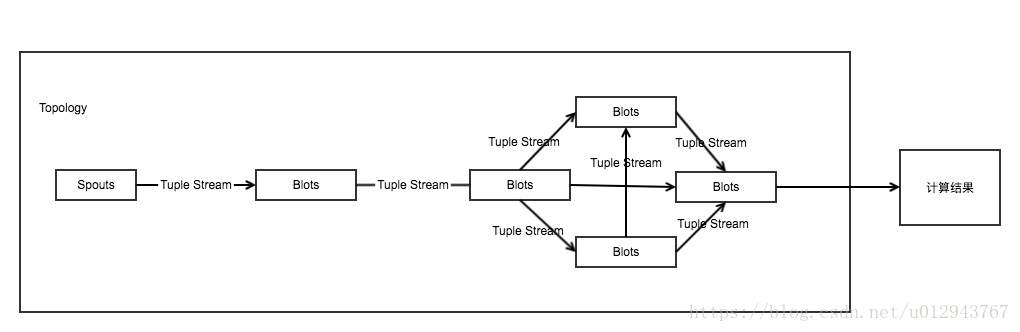
流分组
上面说到,数据可以从Spouts中流到Bolts,也可以从一个Bolts流到另一个Bolts,其中Spouts和Bolts都是独立运行在某一个Task中的,所以说Task的数量就是你Storm集群的并行度,而在这种情况下,怎么决定一个Bolts或者Spouts处理出来的结果,流向另一个Bolts的规则呢?此时需要使用到流分组。流分组是控制数据流向规则的一个东西。Storm中有4个内置的分组:
- 随机分组(
Shuffle Grouping),表示数据随机达到,负载均衡的效果。比如BoltA运行在task1/task2/task3中,而Bolt2运行在task4/task5/task6中,而BoltsA的数据要流向BoltB,则他们的流向为task1->task4/task2->task5/task3->task6 - 字段分组(
Fields Grouping),表示数据按照字段来区分,具有相同字符串的元组将会流向相同的Bolts中处理 - 全局分组(
Global Grouping),所有流可以分组并向前到一个Bolts。此分组将源的所有实例生成的元组发送到单个目标实例(具体来说,选择具有最低ID的工作程序) - 所有分组(
All Grouping),所有分组将每个元组的单个副本发送到接收Bolts的所有实例。这种分组用于向Bolts发送信号。所有分组对于连接操作都很有用。相当于广播。 None Grouping,不分组,目前等同于Shuffle Grouping。Direct Grouping直接分组,由Tuple的发射单元直接决定Tuple将发射给那个Bolts,一般情况下是由接收Tuple的Bolts决定接收哪个Bolts发射的Tuple。这是一种比较特别的分组方法,用这种分组意味着消息的发送者指定由消息接收者的哪个Task处理这个消息。 只有被声明为Direct Stream的消息流可以声明这种分组方法。而且这种消息Tuple必须使用emitDirect方法来发射。消息处理者可以通过TopologyContext来获取处理它的消息的taskid(OutputCollector.emit方法也会返回taskid)。
总结
本篇文章主要介绍了Storm的一些基本知识,包括集群架构,Storm的核心概念,以及并行度和流分组的相关概念。