在使用深度学习框架进行目标检测与识别时,我们常常不知道如何去提高模型的鲁棒性以及检测的正确率。下面就为大家讲述一下如何对深度学习进行调参。从而对深度学习有更深的了解。
1.Data Augmentation(数据增强)
1.1几何变化
图像翻转(flipping)、裁剪(crop),缩放(scale)、旋转(rotation)、平移(shift)
1.2对比度变换(contrast)
在HSV颜色空间中,改变图片的色度(Hue)、饱和度(Saturation)、亮度(Value)
1.3颜色变换(color)
1.3.1在训练集像素值的RGB空间进行PCA,得到RGB空间的3个主方向向量以及3个特征值(p1,p2,p3,λ1, λ2, λ3)。对训练集中的每幅图像的每个像素,进行处理。
1.3.2噪声扰动,对图像中的每个像素的RGB值进行随机扰动,常用的噪声模式是椒盐噪声以及高斯噪声。
2预处理
2.1零中心化(zero-centered)以及归一化(normalization)
零中心化与归一化的目的是为了将消除量纲不同、数据变异、数值相差较大引起的影响。零中心化是对每一维度的数值减去该维度的平均值,归一化是对每一维度的数值减去该维度的平均值后再除以该维度的标准差。在训练神经网络中,对数据进行零中心化处理,可以增加基向量的正交性;而对数据进行归一化处理,可以有效地增加权重的收敛速度,而且其还有可能增加精度。
2.2PCA
先对数据进行零中心化处理,然后计算协方差矩阵。将数据变换到协方差矩阵的特征基准轴上。这样就对数据进行了解相关(协方差矩阵变成对角阵)。
数据协方差矩阵的第(i,j)个元素是数据第i个和第j个维度的协方差,该矩阵对角线上的元素是方差,我们可以对数据协方差矩阵可以进行svd(奇异值分解)运算。
2.3白化(whitening)
白化操作的输入是特征基准上的数据,然后对每个维度除以其特征值来对数值范围进行归一化。
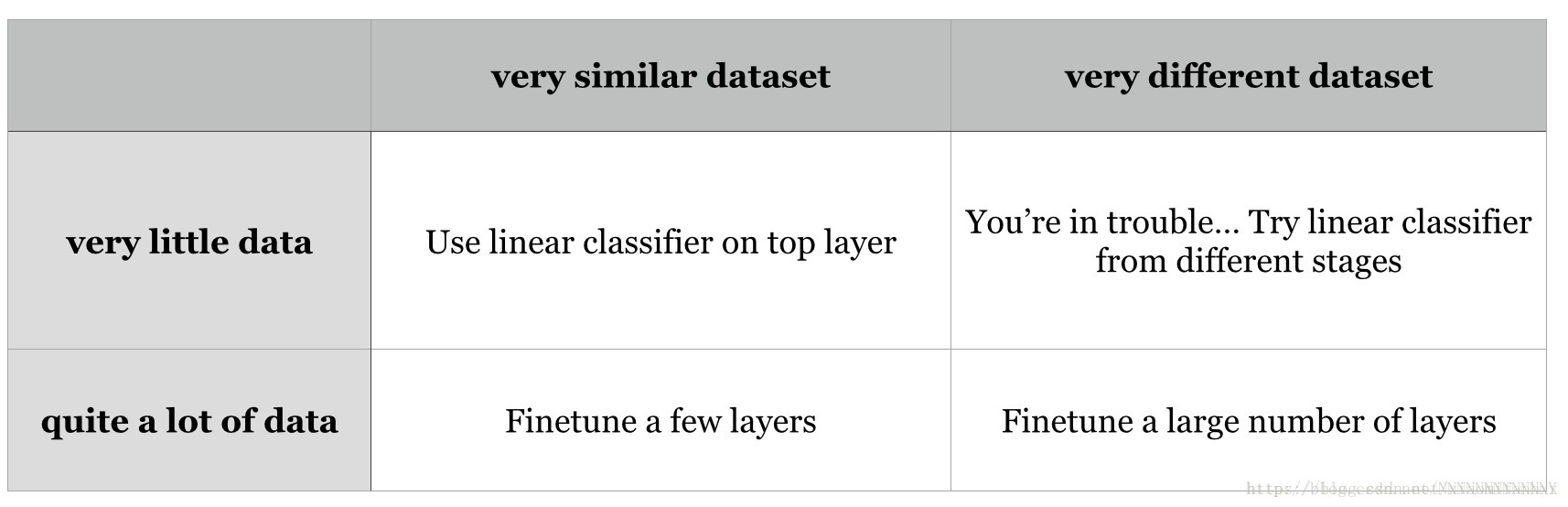
3Fine-tuning on pre-trained models
4权重(weights)初始化以及偏置(biase)初始化
权重初始化:小随机数初始化(Initialization with Small Random Numbers):权重初始值要非常接近0又不能等于0。解决方法就是将权重初始化为很小的数值,以此来打破对称性,现在一般使用的是截断正态分布。
偏置初始化:因为随机小数值权重矩阵已经打破了对称性,通常将偏置初始化为0。
5参数更新
5.1随机梯度下降算法:x+=-learning_rate*dx
5.2Momentum更新:
# 动量更新
v = mu * v - learning_rate * dx # 与速度融合
x += v # 与位置融合6学习率退火
6.1随步数衰减
每进行几个周期就根据一些因素降低学习率。典型的值是每过5个周期就将学习率减少一半,或者每20个周期减少到之前的0.1。在实践中可能看见这么一种经验做法:使用一个固定的学习率来进行训练的同时观察验证集错误率,每当验证集错误率停止下降,就乘以一个常数(比如0.5)来降低学习率。
6.2指数衰减。
数学公式是\alpha=\alpha_0e^{-kt},其中\alpha_0,k是超参数,t是迭代次数(也可以使用周期作为单位)
7常用的激活函数(Activation Functions)
a) Sigmoid:易饱和使梯度消失,在接近输出值0和1的地方梯度接近于0
b) Tanh双曲正切
c) ReLU 优选
d) Leaky ReLU
e) Maxout
8损失函数以及防止过拟合操作
损失函数:Cross Entropy 通常使用交叉损失,SoftMax分类器
防止过拟合:正则化(regularizations):L1 regularization:它会让权重向量在最优化的过程中变得稀疏(即非常接近0)。L2 regularization:相较L1正则化,L2正则化中的权重向量大多是分散的小数字。在实践中,如果不是特别关注某些明确的特征选择,一般说来L2正则化都会比L1正则化效果好。Dropout:可以理解为是对数量巨大的子网络们做了模型集成(model ensemble)。Batch_Normalization layer:可以理解为在网络的每一层之前都做预处理。加速收敛,加上它之后一般可以把dropout去掉。
9通过作图来观察loss与batch,learning_rate联系
可以画出随着不同参数训练集测试集的改变情况,观察它们的走势图来分析到底什么时候的参数比较合适。
a) 不同学习率与loss的曲线图,横坐标是epoch,纵坐标是loss。见图1。
b) 不同的batchsize与loss的曲线图,横坐标是training batches,纵坐标是loss。见图2。
c) 训练集和验证集准确率对比,横坐标是epoch,纵坐标是准确率。见图3。

参考博客:https://blog.csdn.net/nnnnnnnnnnnny/article/details/54577449