最近看了降维的各类算法,想简单做个回顾和小结,先上图
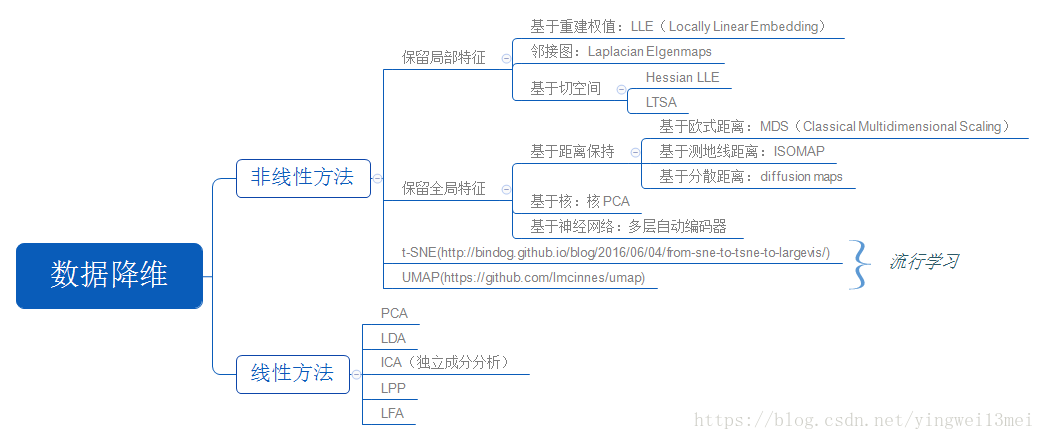
一、浅谈协方差矩阵
1、统计学的基本概念
均值:
方差:
标准差:
均值描述的是样本集合的中间点,它告诉我们的信息是有限的,而标准差给我们描述的是样本集合的各个样本点到均值的距离之平均。
以这两个集合为例,[0, 8, 12, 20]和[8, 9, 11, 12],两个集合的均值都是10,但显然两个集合的差别是很大的,计算两者的标准差,前者是8.3后者是1.8,显然后者较为集中,故其标准差小一些,标准差描述的就是这种“散布度”。之所以除以n-1而不是n,是因为这样能使我们以较小的样本集更好地逼近总体的标准差,即统计上所谓的“无偏估计”。而方差则仅仅是标准差的平方。
2、为啥需要协方差
标准差和方差一般是用来描述一维数据的,但现实生活中我们常常会遇到含有多维数据的数据集,最简单的是大家上学时免不了要统计多个学科的考试成绩。面对这样的数据集,我们当然可以按照每一维独立的计算其方差,但是通常我们还想了解更多,比如,一个男孩子的猥琐程度跟他受女孩子的欢迎程度是否存在一些联系。协方差就是这样一种用来度量两个随机变量关系的统计量,我们可以仿照方差的定义:
来度量各个维度偏离其均值的程度,协方差可以这样来定义:
协方差的结果有什么意义呢?如果结果为正值,则说明两者是正相关的(从协方差可以引出“相关系数”的定义),也就是说一个人越猥琐越受女孩欢迎。如果结果为负值, 就说明两者是负相关,越猥琐女孩子越讨厌。如果为0,则两者之间没有关系,猥琐不猥琐和女孩子喜不喜欢之间没有关联,就是统计上说的“相互独立”。
从协方差的定义上我们也可以看出一些显而易见的性质,如:
1、
2、
3、协方差矩阵
前面提到的猥琐和受欢迎的问题是典型的二维问题,而协方差也只能处理二维问题,那维数多了自然就需要计算多个协方差,比如n维的数据集就需要计算 个协方差,那自然而然我们会想到使用矩阵来组织这些数据。给出协方差矩阵的定义:
这个定义还是很容易理解的。协方差矩阵是一个对称的矩阵,而且对角线是各个维度的方差。
4、小结
理解协方差矩阵的关键就在于牢记它的计算是不同维度之间的协方差,而不是不同样本之间。拿到一个样本矩阵,最先要明确的就是一行是一个样本还是一个维度,心中明确整个计算过程就会顺流而下,这么一来就不会迷茫了。
二、PCA(主成分分析)
本质上讲,PCA就是将高维的数据通过线性变换投影到低维空间上去,但这个投影可不是随便投投,要遵循一个指导思想,那就是:找出最能够代表原始数据的投影方法。这里怎么理解这个思想呢?“最能代表原始数据”希望降维后的数据不能失真,也就是说,被PCA降掉的那些维度只能是那些噪声或是冗余的 数据。这里的噪声和冗余我认为可以这样认识:
- 我们常说“噪音污染”,意思就是“噪声”干扰我们想听到的真正声音。同样,假设样本中某个主要的维度A,它能代表原始数据,是“我们真正想听到的东西”,它本身含有的“能量”(即该维度的方差,为啥?别急,后文该解释的时候就有啦~)本来应该是很大的,但由于它与其他维度有那么一些千丝万缕的相关性,受到这些个相关维度的干扰, 它的能量被削弱了,我们就希望通过PCA处理后,使维度A与其他维度的相关性尽可能减弱,进而恢复维度A应有的能量,让我们“听的更清楚”!
- 冗余:冗余也就是多余的意思,就是有它没它都一样,放着就是占地方。同样,假如样本中有些个维度,在所有的样本上变化不明显(极端情况:在所有的样本中该维度都等于同一个数),也就是说该维度上的方差接近于零,那么显然它对区分不同的样本丝毫起不到任何作用,这个维度即是冗余的,有它没它一个样,所以PCA应该去掉这些维度。
协方差阵
协方差矩阵度量的是维度与维度之间的关系,而非样本与样本之间。协方差矩阵的主对角线上的元素是各个维度上的方差(即能量),其他元素是两两维度间的协方差(即相关性)。我们要的东西协方差矩阵都有了,先来看“降噪”,让保留下的不同维度间的相关性尽可能小,也就是说让协方差矩阵中非对角线元素都基本为零。达到这个目的的方式自然不用说,线代中讲的很明 确——矩阵对角化。而对角化后得到的矩阵,其对角线上是协方差矩阵的特征值,它还有两个身份:首先,它还是各个维度上的新方差;其次,它是各个维度本身应该拥有的能量(能量的概念伴随特征值而来)。这也就是我们为何在前面称“方差”为“能量”的原因。也许第二点可能存在疑问,但我们应该注意到这个事实,通过对角化后,剩余维度间的相关性已经减到最弱,已经不会再受“噪声”的影响了,故此时拥有的能量应该比先前大了。看完了“降噪”,我们的“去冗余”还没完呢。对角化后的协方差矩阵,对角线上较小的新方差对应的就是那些该去掉的维度。
所以我们只取那些含有较大能量(特征值)的维度,其余的就舍掉即可。PCA的本质其实就是对角化协方差矩阵。
总结一下PCA的算法步骤:
设有m条n维数据。
1)将原始数据按列组成n行m列矩阵X
2)将X的每一行(代表一个属性字段)进行零均值化,即减去这一行的均值
3)求出协方差矩阵
4)求出协方差矩阵的特征值及对应的特征向量
5)将特征向量按对应特征值大小从上到下按行排列成矩阵,取前k行组成矩阵P
6) 即为降维到k维后的数据
PCA理解第一层境界:最大方差投影
正如PCA的名字一样, 你要找到主成分所在方向, 那么这个主成分所在方向是如何来的呢?
其实是希望你找到一个垂直的新的坐标系, 然后投影过去, 这里有两个问题。 第一问题: 找这个坐标系的标准或者目标是什么? 第二个问题, 为什么要垂直的, 如果不是垂直的呢?
如果你能理解第一个问题, 那么你就知道为什么PCA主成分是特征值和特征向量了。 如果你能理解第二个问题, 那么你就知道PCA和ICA到底有什么区别了。 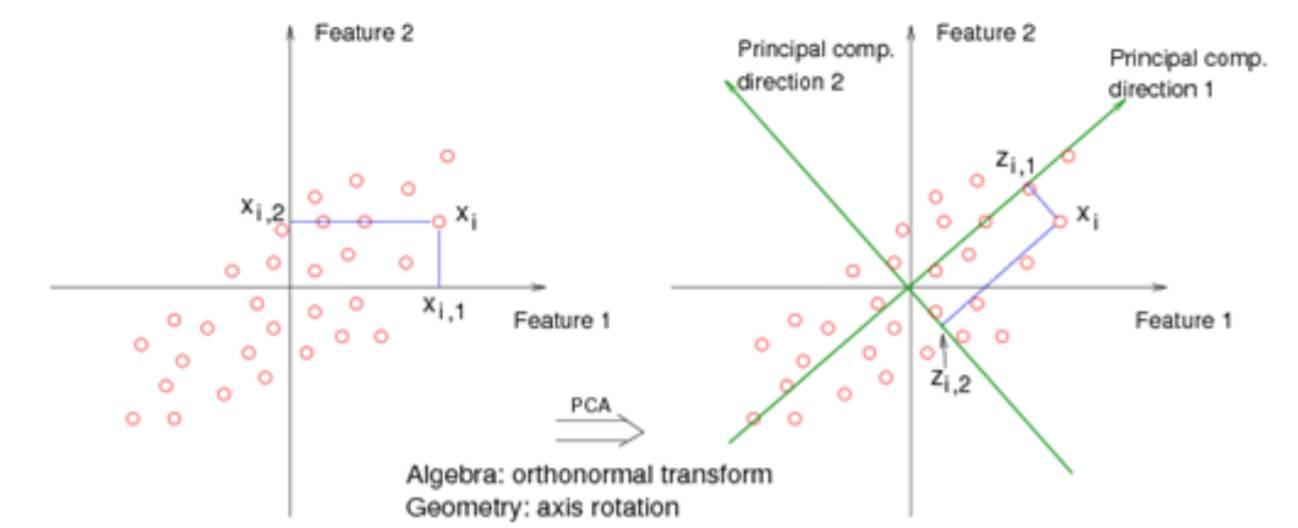
对于第一个问题: 其实是要求解方差最小或者最大。 按照这个目标, 你代入拉格朗日求最值, 你可以解出来, 主成分方向,刚好是S的特征向量和特征值! 是不是很神奇? 伟大的拉格朗日(参考 “一步一步走向锥规划 - QP” “一挑三 FJ vs KKT “)

现在回答了,希望你理解了, PCA是对什么东西求解特征值和特征向量。 也理解为什么是求解的结果就是特征值和特征向量吧!
这仅仅是PCA的本意! 我们也经常看到PCA用在图像处理里面, 希望用最早的主成分重建图像:

这是怎么做到的呢?
PCA理解第二层境界:最小重建误差
什么是重建, 那么就是找个新的基坐标, 然后减少一维或者多维自由度。 然后重建整个数据。 好比你找到一个新的视角去看这个问题, 但是希望自由度小一维或者几维。

那么目标就是要最小重建误差,同样我们可以根据最小重建误差推导出类似的目标形式。

虽然在第二层境界里面, 也可以直观的看成忽略了最小特征值对应的特征向量所在的维度。 但是你能体会到和第一层境界的差别么? 一个是找主成分, 一个是维度缩减。 所以在这个层次上,才是把PCA看成降维工具的最佳视角。
PCA理解第三层境界:高斯先验误差
在第二层的基础上, 如果引入最小二乘法和带高斯先验的最大似然估计的等价性。(参考”一步一步走向锥规划 - LS” “最小二乘法的4种求解” ) 那么就到了理解的第三层境界了。
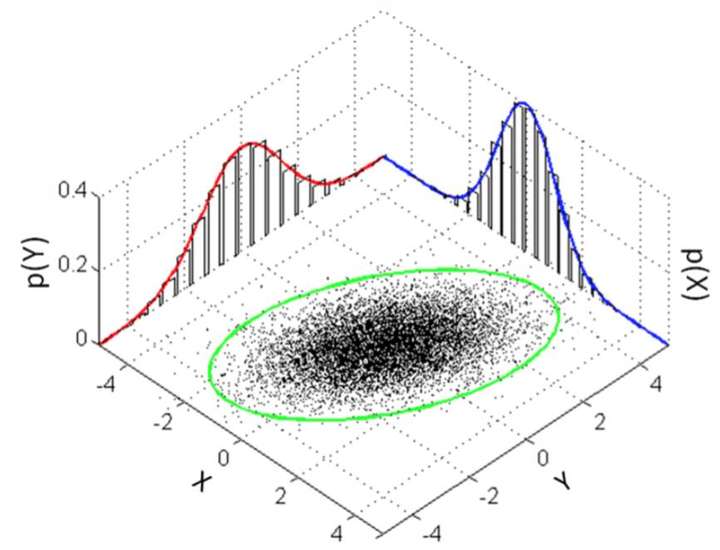
所以, 重最小重建误差, 我们知道求解最小二乘法, 从最小二乘法, 我们可以得到高斯先验误差。

有了高斯先验误差的认识,我们对PCA的理解, 进入了概率分布的层次了。 而正是基于这个概率分布层次的理解, 才能走到Hinton的理解境界。
PCA理解第四层境界(Hinton境界):线性流形对齐
如果我们把高斯先验的认识, 到到数据联合分布, 但是如果把数据概率值看成是空间。 那么我们可以直接到达一个新的空间认知。
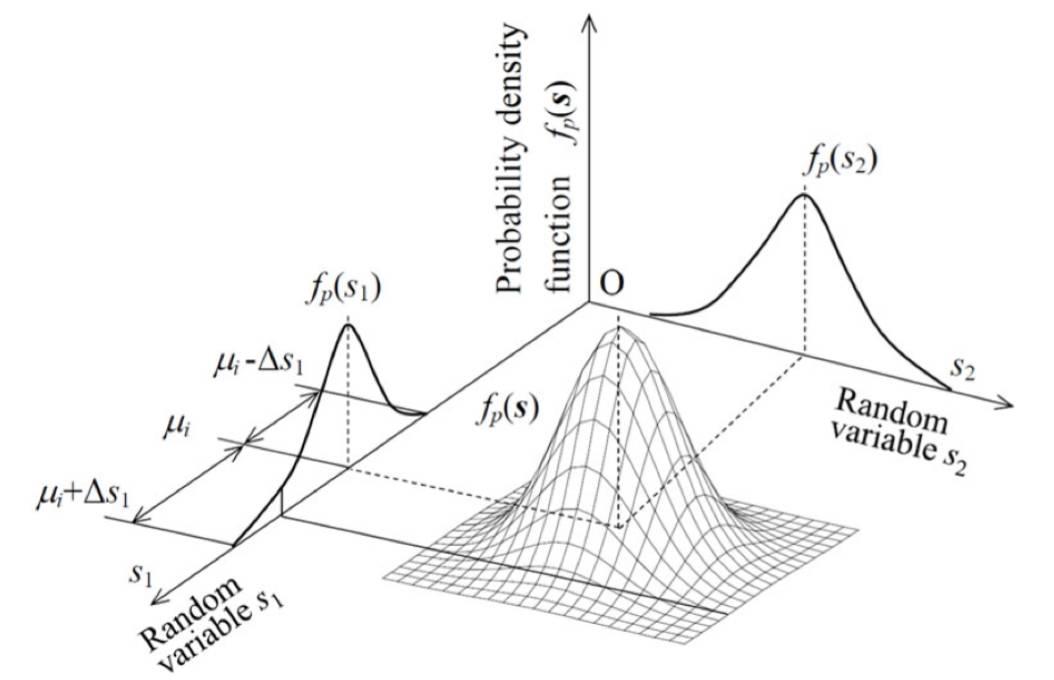
这就是“Deep Learning”书里面写的, 烙饼空间(Pancake), 而在烙饼空间里面找一个线性流行,就是PCA要干的事情。 我们看到目标函数形式和最小重建误差完全一致。 但是认知完全不在一个层次了。
小结
这里罗列理解PCA的4种境界,试图通过解释Hinton如何理解PCA的, 来强调PCA的重要程度。 尤其崇拜Hinton对简单问题的高深认知。不仅仅是PCA,尤其是他对EM算法的再认识, 诞生了VBEM算法, 让VB算法完全从物理界过渡到了机器学习界(参考 “变の贝叶斯”)。 有机会可以看我对EM算法的回答,理解EM算法的9种境界。
三、SVD(奇异值分解)
从Andrew的课来看: SVD 相当于an implementation of PCA 1.现在的计算机计算SVD已经很成熟了,Andrew本人将其视作平方运算这样的计算。 2.用SVD来实现PCA,避免了高维sigma矩阵(设计矩阵/协方差矩阵)的计算,太妙了!!!
https://blog.csdn.net/qiusuoxiaozi/article/details/50810521
四、FA(因子分析)
因子分析其实就是认为高维样本点实际上是由低维样本点经过高斯分布、线性变换、误差扰动生成的,因此高维数据可以使用低维来表示(本质上就是一种降维算法)。因子分析(factor analysis)是一种数据简化的技术。它通过研究众多变量之间的内部依赖关系,探求观测数据中的基本结构,并用少数几个假想变量来表示其基本的数据结构。这几个假想变量能够反映原来众多变量的主要信息。原始的变量是可观测的显在变量,而假想变量是不可观测的潜在变量,称为因子。
五、LDA(linear discriminant analysis)
六、t-SNE
http://bindog.github.io/blog/2016/06/04/from-sne-to-tsne-to-largevis/
七、UMAP
https://github.com/lmcinnes/umap
如何理解主成分分析中的协方差矩阵的特征值的几何含义?
https://www.zhihu.com/question/36348219/answer/275378672